







 本文介绍了如何使用Python进行网络爬虫,以获取特定歌曲网站的歌词。作者通过分析网页,找到POST请求的参数,包括id、token和时间戳,并在遇到问题后改为GET请求成功获取数据。代码示例中展示了如何利用requests库发送请求,解析JSON数据并保存歌词到txt文件。
本文介绍了如何使用Python进行网络爬虫,以获取特定歌曲网站的歌词。作者通过分析网页,找到POST请求的参数,包括id、token和时间戳,并在遇到问题后改为GET请求成功获取数据。代码示例中展示了如何利用requests库发送请求,解析JSON数据并保存歌词到txt文件。
今天我们来讲Python爬虫的第二个课【获取某歌曲网站的歌曲的歌词】,如果对你有帮助的还请各位佬多多关注,多多点赞,多多收藏!!
PS上一节课:请查看【爬虫专栏】
步入正题
第一步,歌曲网址:点我进入
这边我就随便点一位歌手为例,就点击张杰的

这边我就随便点击一首歌为例,就点击《天下》
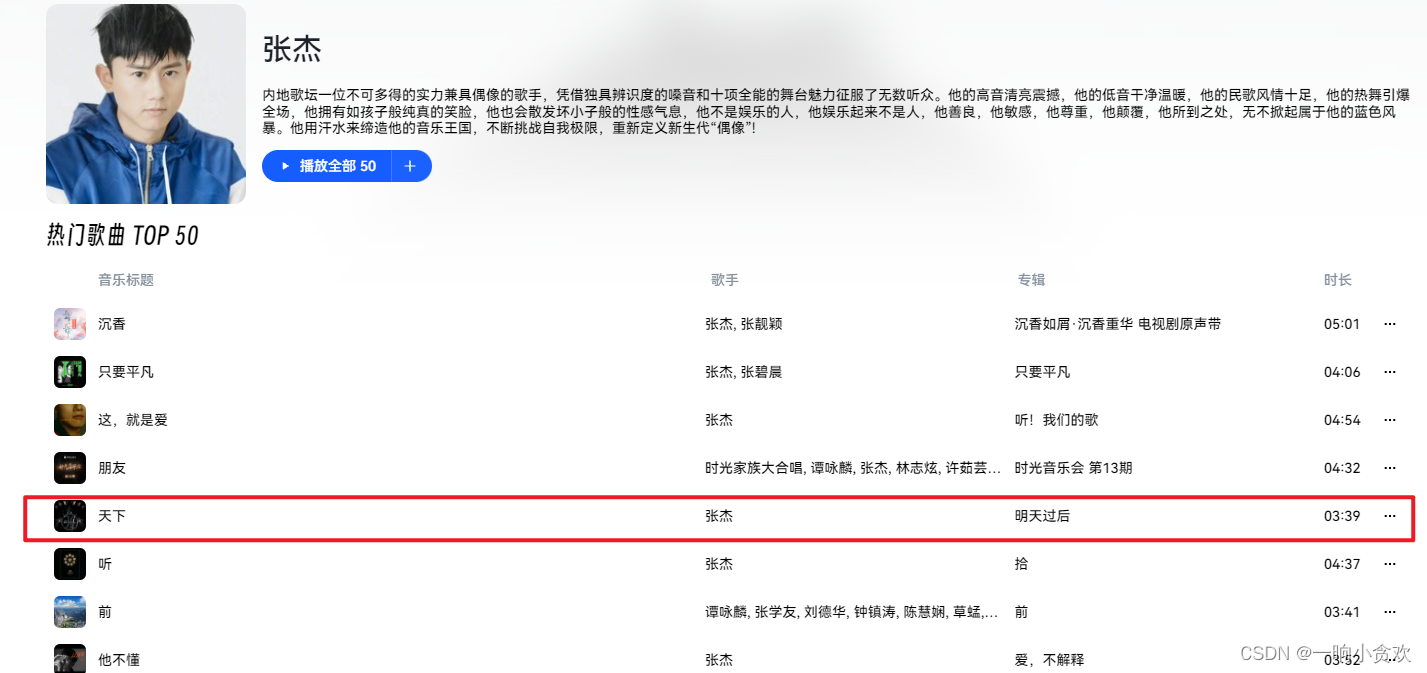
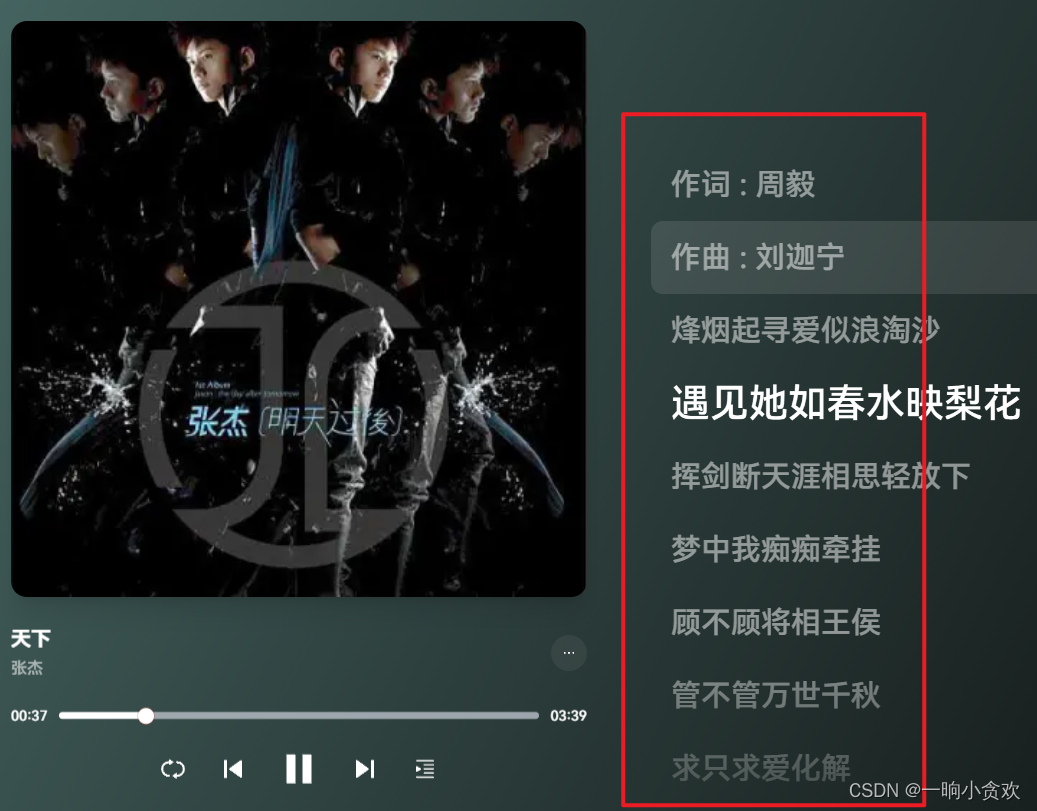
大家点击左下角这里放大,显示歌词
第 2 步,点击【f12】点击清空,在点击播放
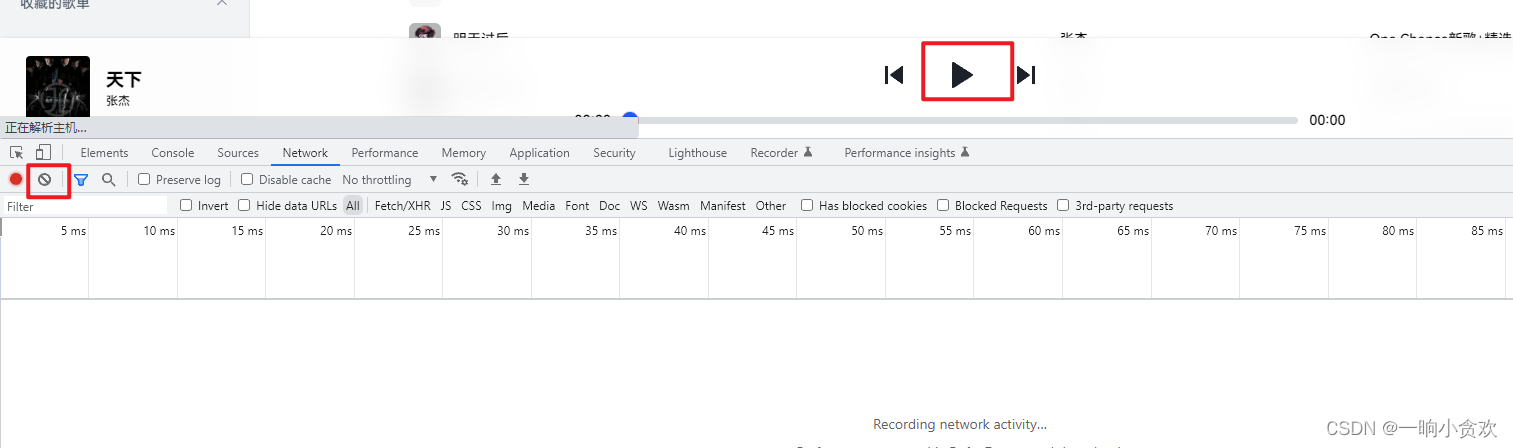
找个歌词的 URL
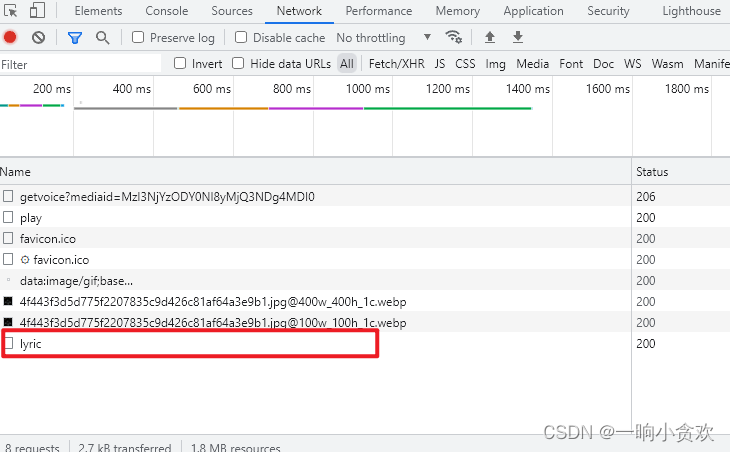
找到返回的歌词:

查看 歌词的 URL以及请求方法
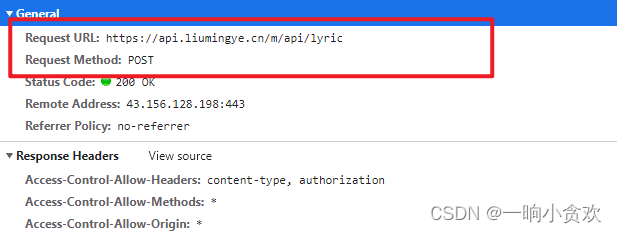
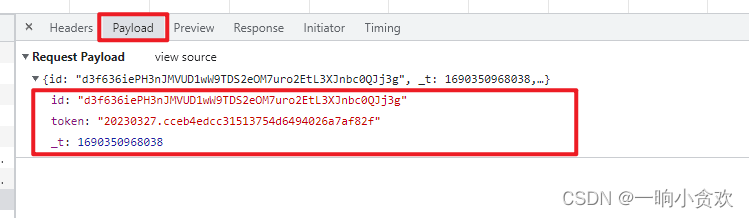
发现是POST请求,我们看一下携带参数
我后期调试发现这里写的post请求,但是用了post一直拿不到数据,我果断改get请求成功了!!
一共有三个参数:
1、【id】
2、【token】
3、【_t】时间戳
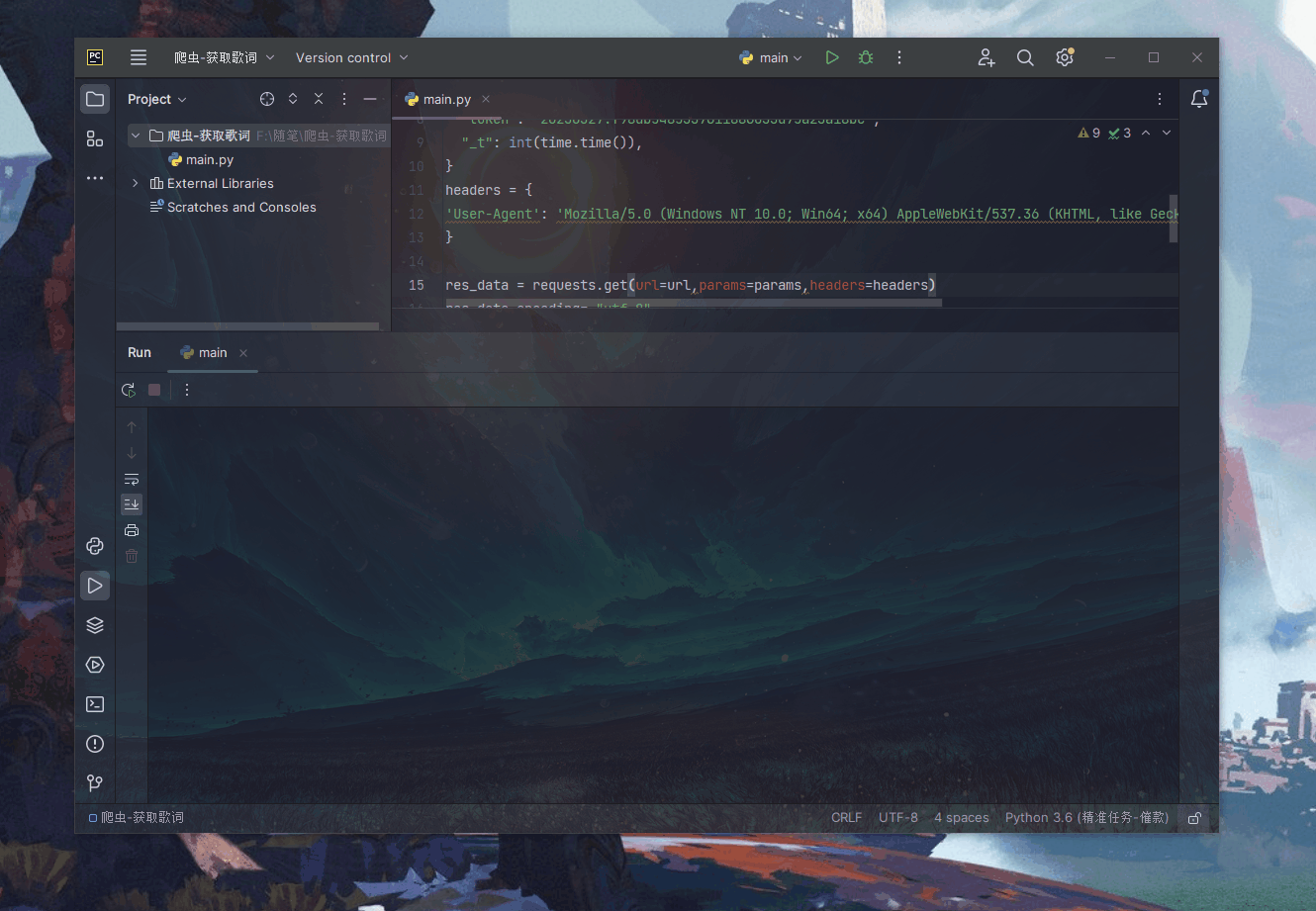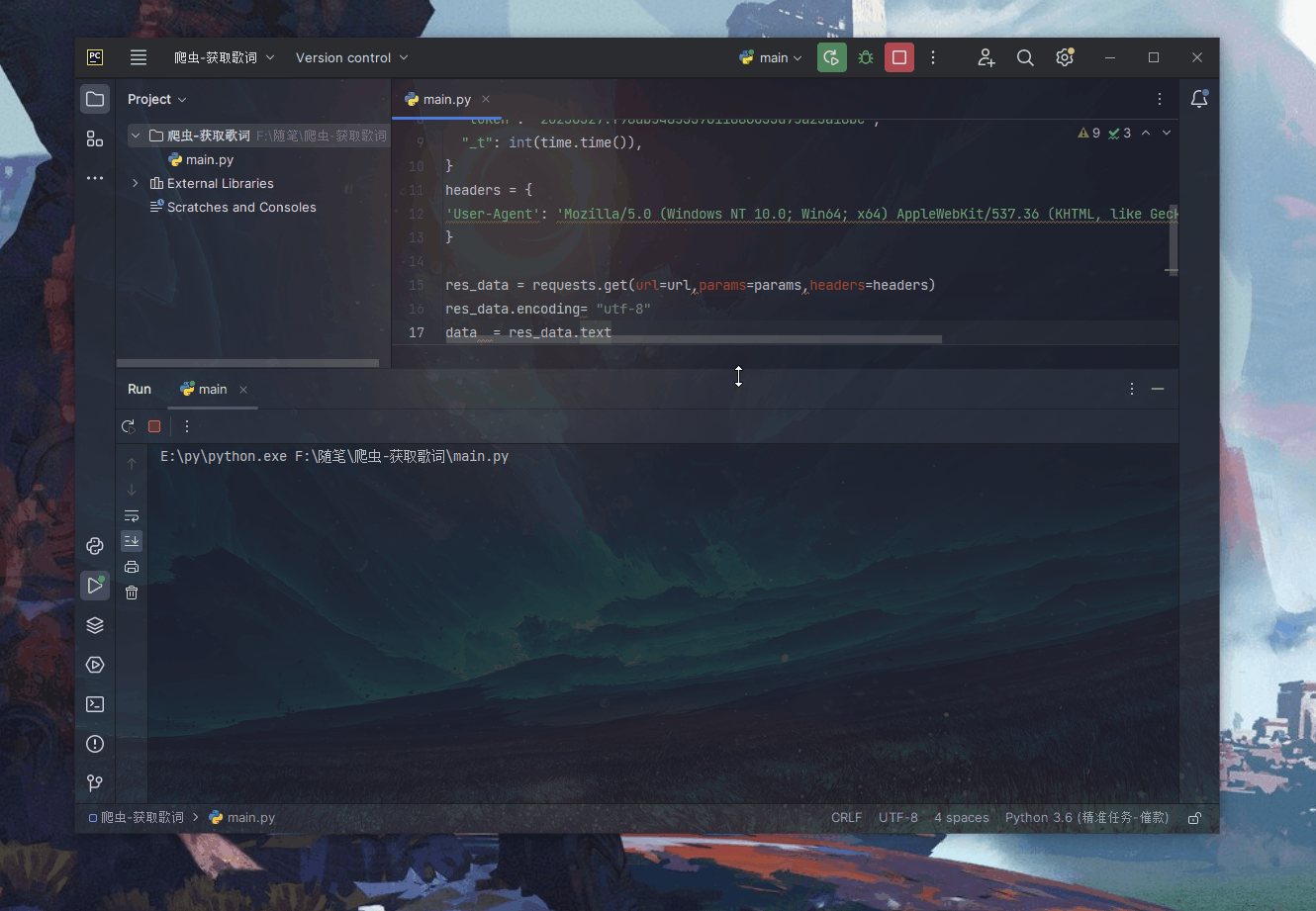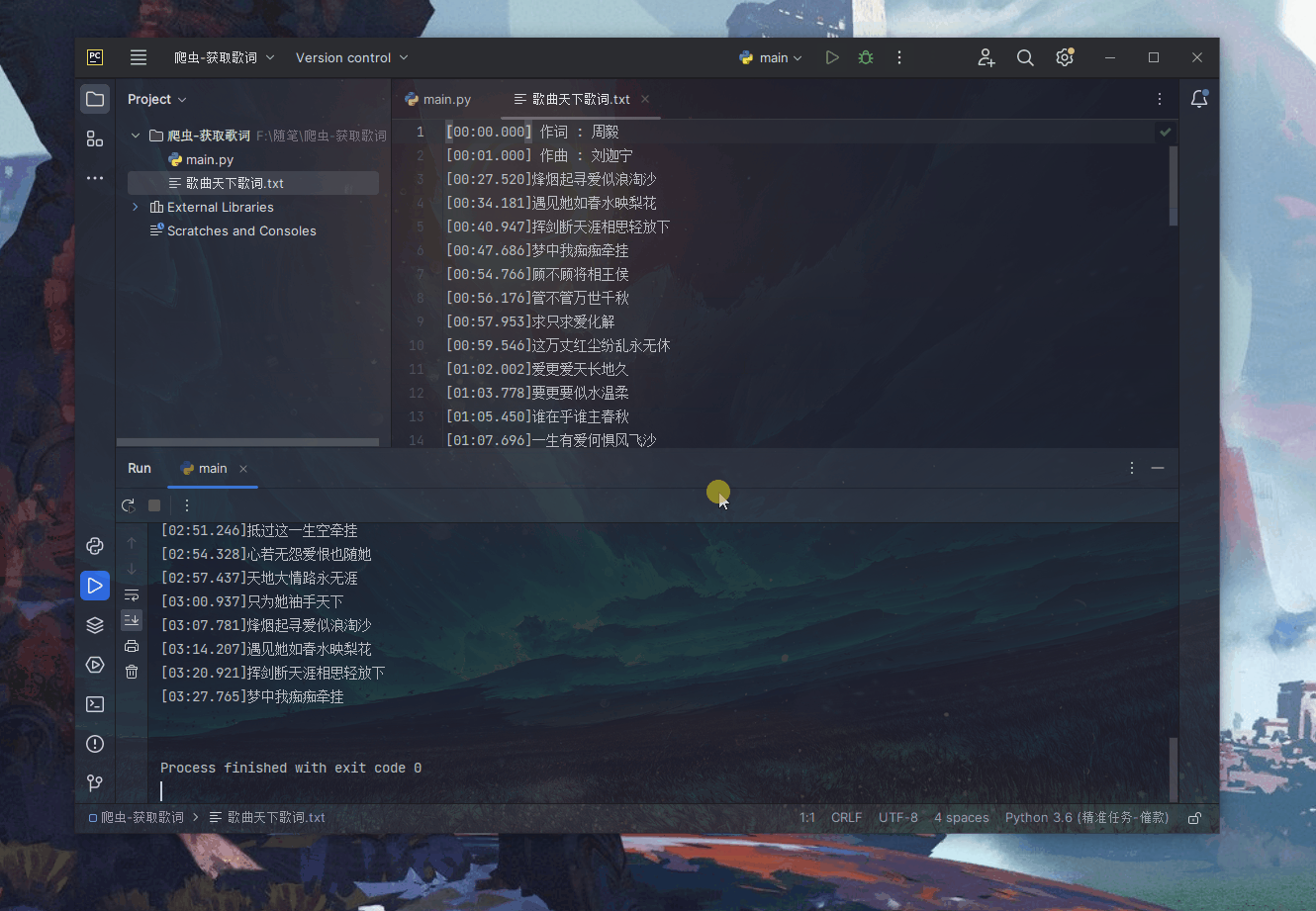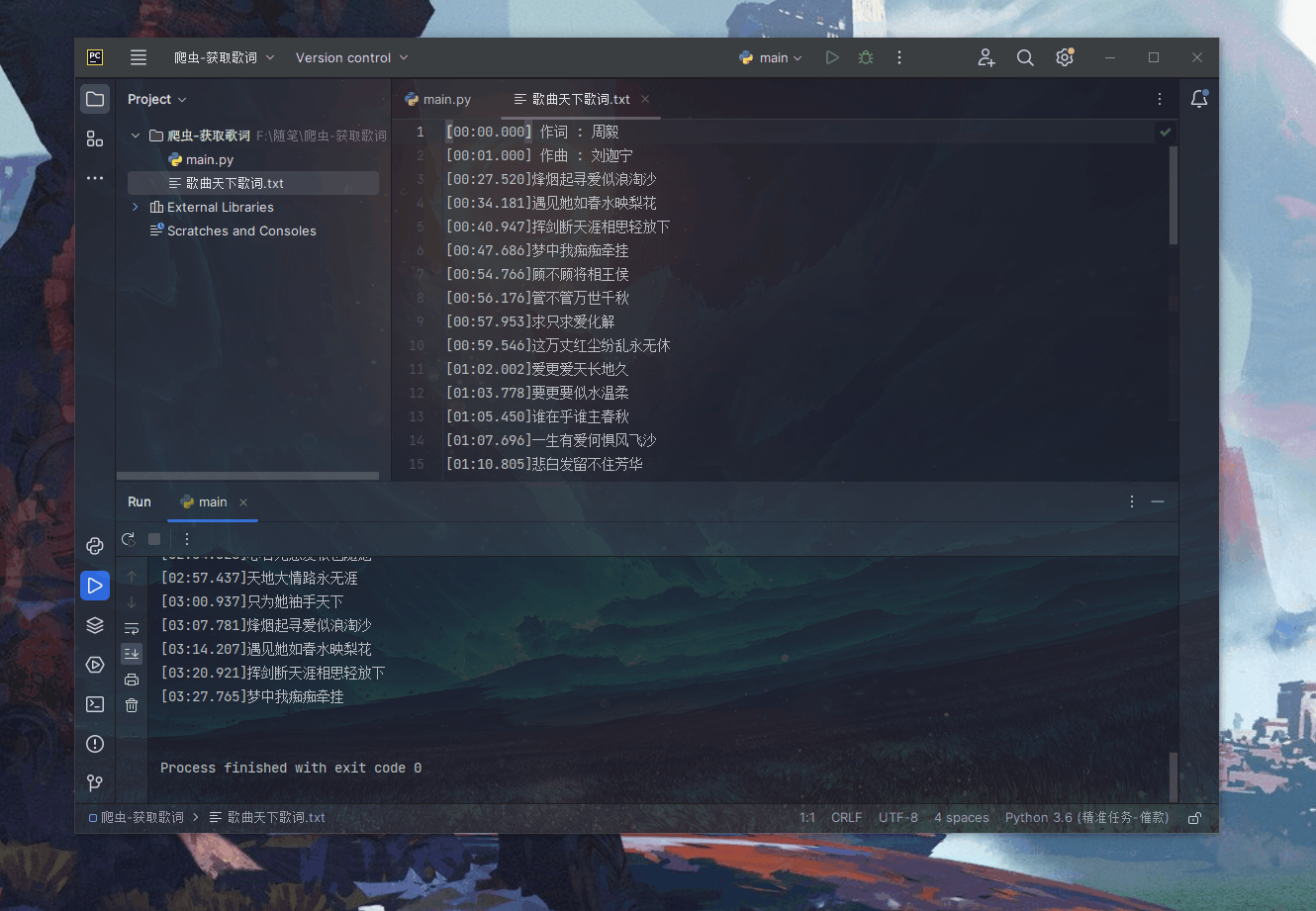
🆗,成功
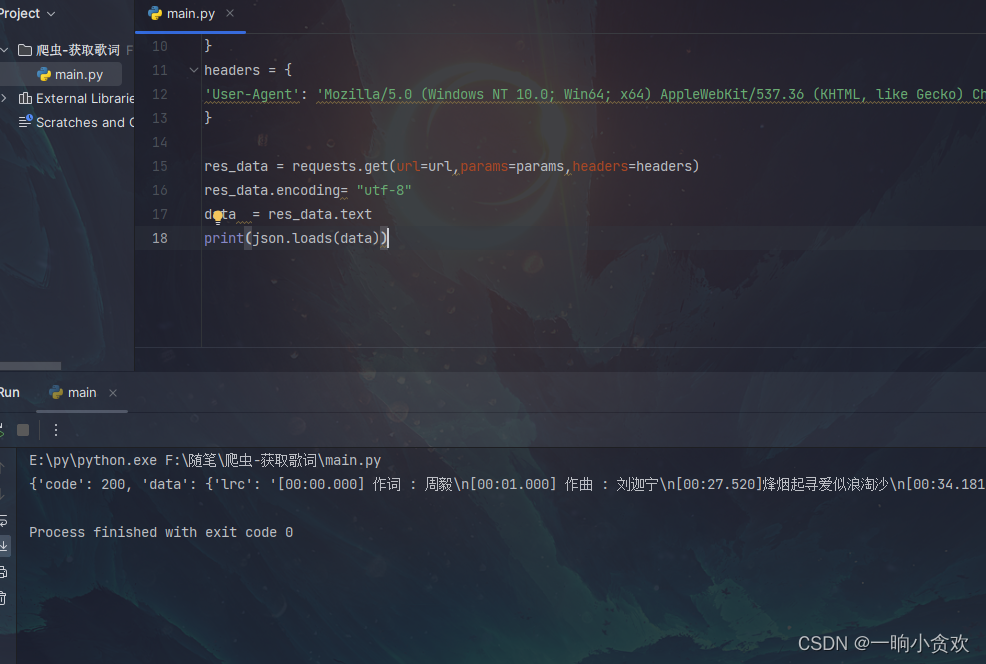
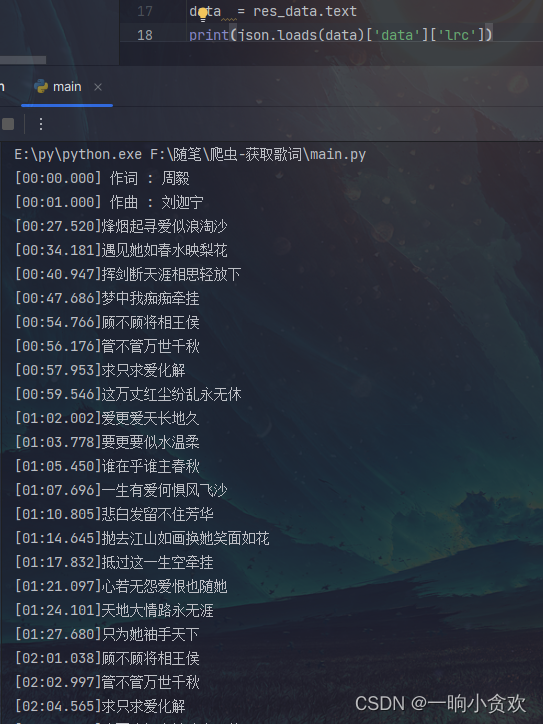
数据清洗一下(歌词自带换行符可直接写入txt文本,下方有代码):
代码
这个代码需加上,浏览器伪装:headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36’}
import json
import time
import requests
url = 'https://api.liumingye.cn/m/api/lyric'
params = {
"id": "d3f636iePH3nJMVUD1wW9TDS2eOM7uro2EtL3XJnbc0QJj3g",
"token": "20230327.f98db5485337611886033d75a23a18bc",
"_t": int(time.time()),
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
res_data = requests.get(url=url,params=params,headers=headers)
res_data.encoding= "utf-8"
data = res_data.text
with open("./歌曲天下歌词.txt",'w',encoding='utf-8') as f:
f.write(json.loads(data)['data']['lrc'])
print(json.loads(data)['data']['lrc'])
PS:
这样我们就可以点击任何一首歌,查看改歌曲的的【id】以及【token】,这样就可以获取改歌曲的歌词!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











