专栏导读
-
🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手
-
-
-
-
📕 此外还有python基础专栏:请点击——>Python基础学习专栏求订阅
-
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
-
❤️ 欢迎各位佬关注! ❤️
1、网址分析
-
-
2、请求方法:get
-
3、参数: 无
-
4、返回响应,HTML(静态网页)
2、选择:lxml+xpath
-
既然返回的是html静态网页,直接lxml+xpath,最方便!!
-
我直接写出关键的xpath
-
每页都有10个名言名句,我先把整页的div获取到,其余的内容、作者、标签都在其下面
//div[@class="col-md-8"]//div[@class="quote"]
.//span[@class="text"]
.//span//small[@class="author"]
//div[@class="tags"]//a
3、完整代码+写入Excel
'''
@Project :项目名称
@File :程序.py
@IDE :PyCharm
@Author :一晌小贪欢
@Date :2024/01/22 15:33
'''
import openpyxl
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
wb = openpyxl.Workbook()
ws = wb.active
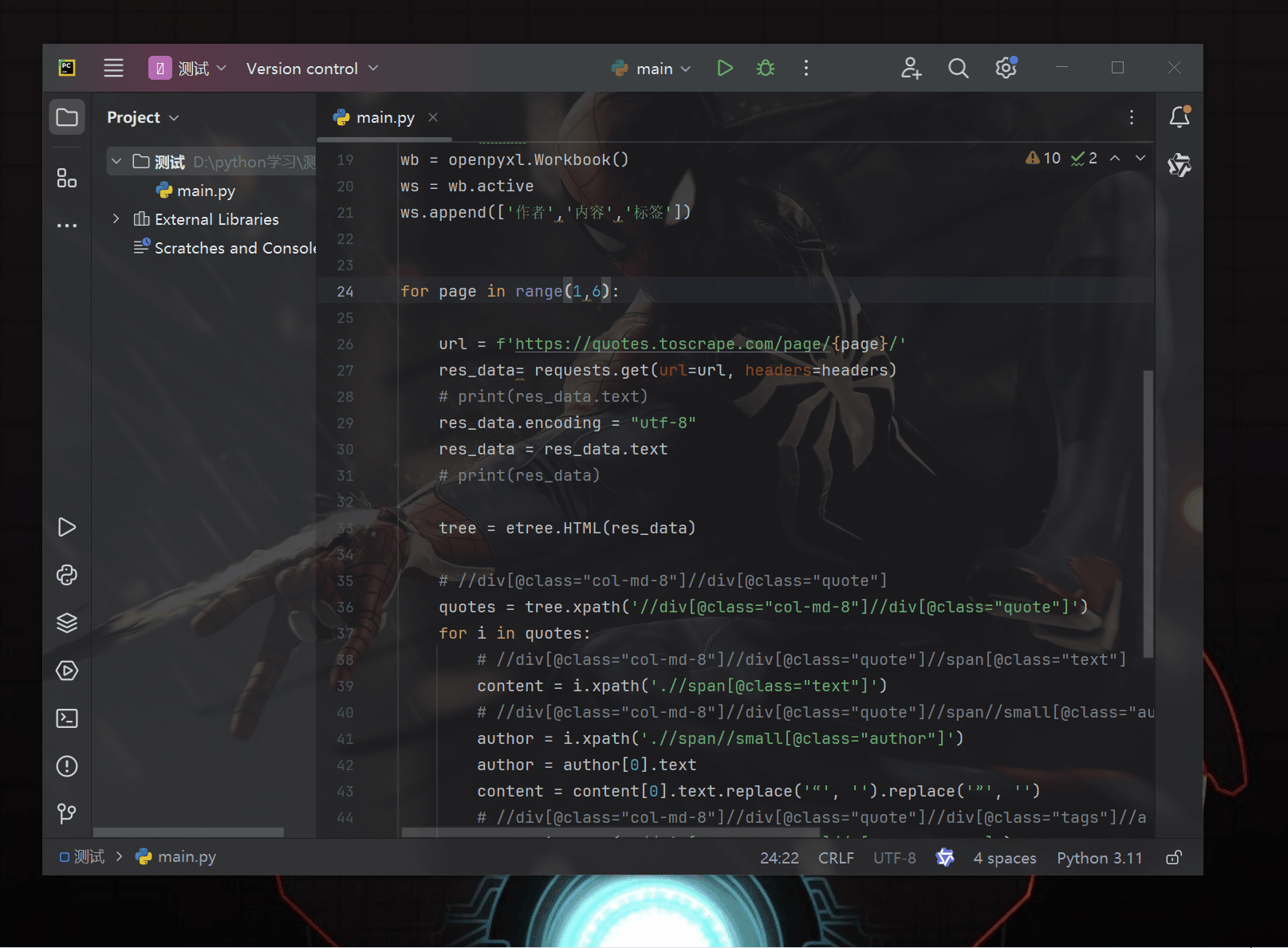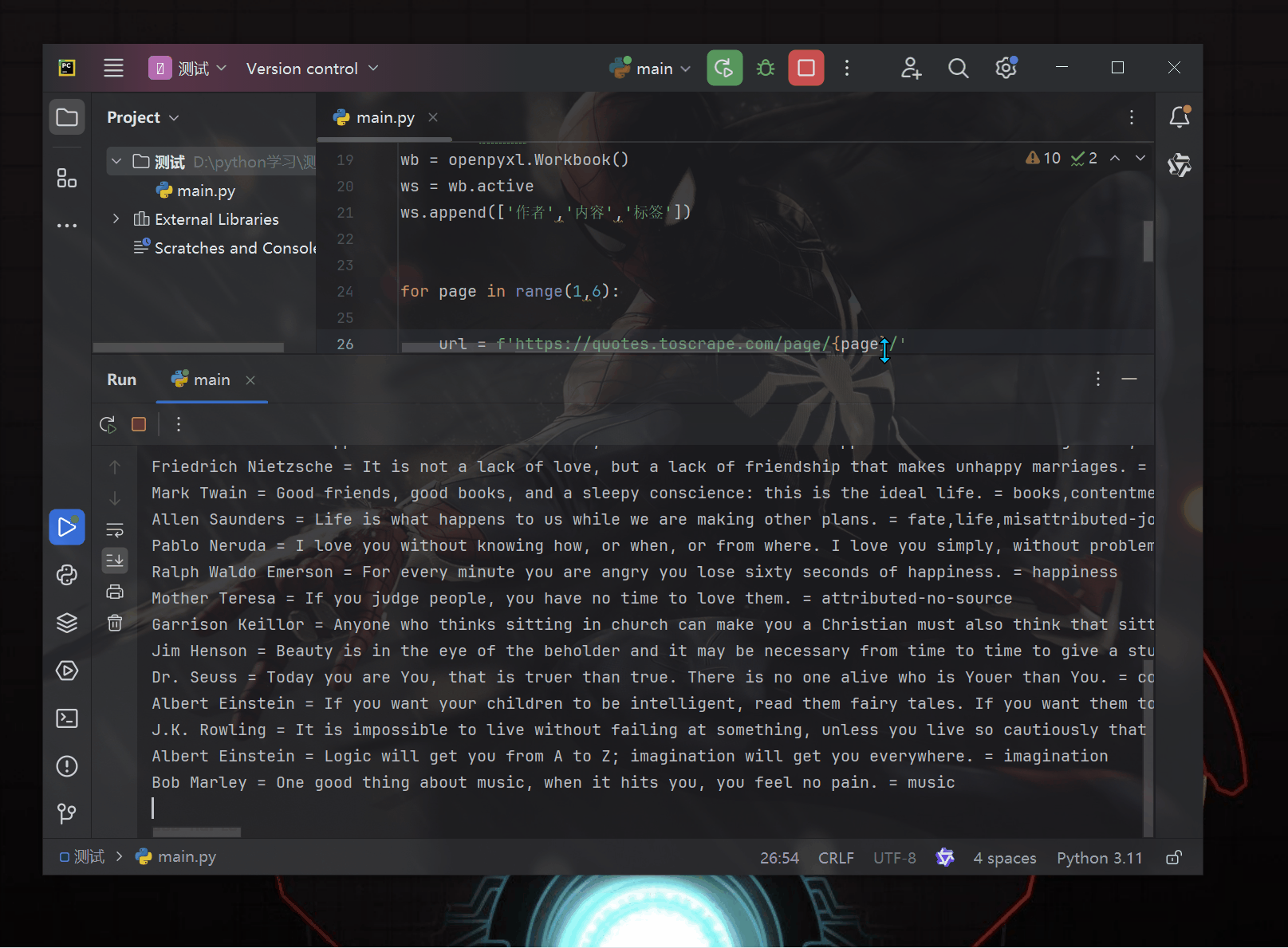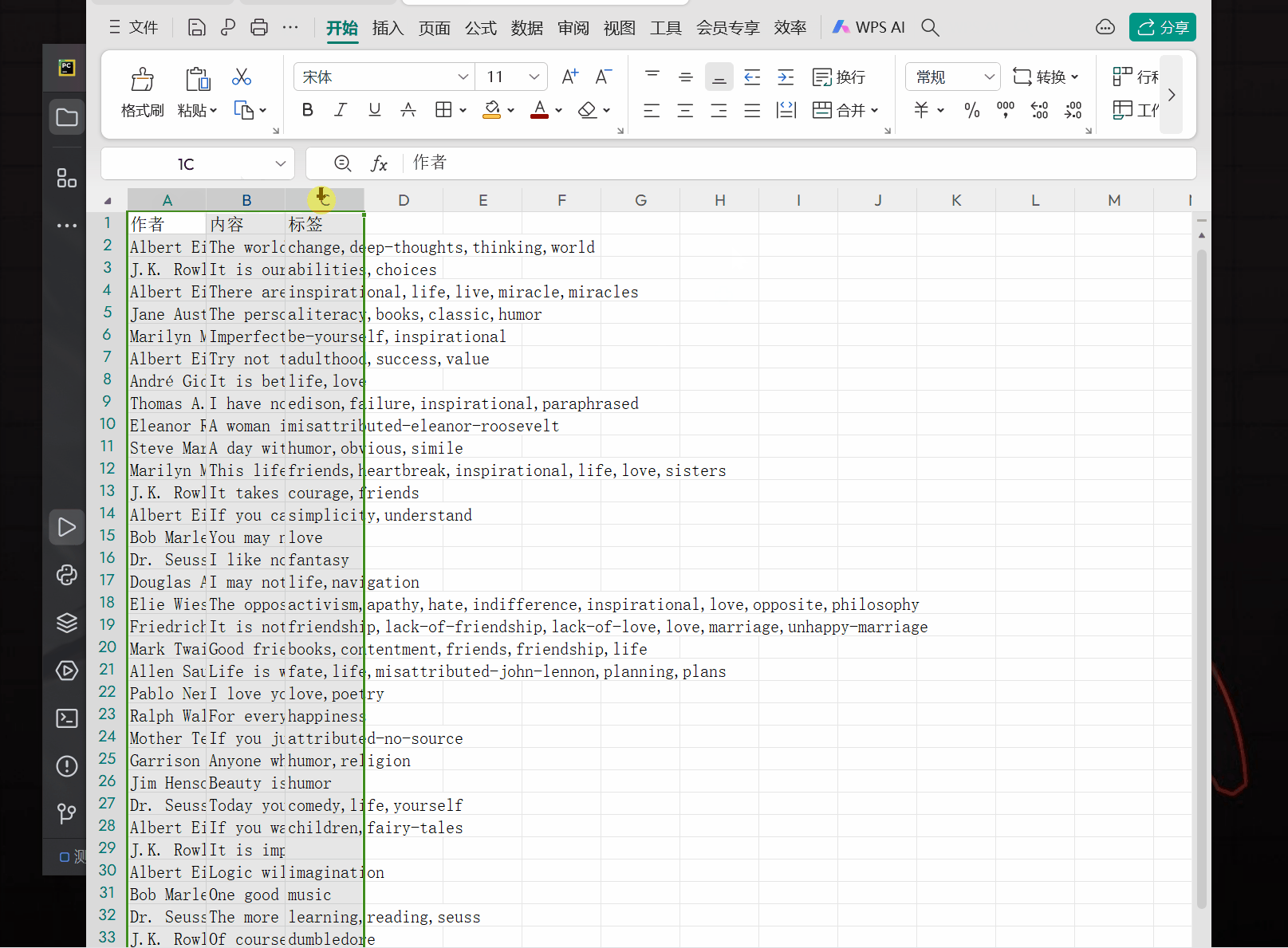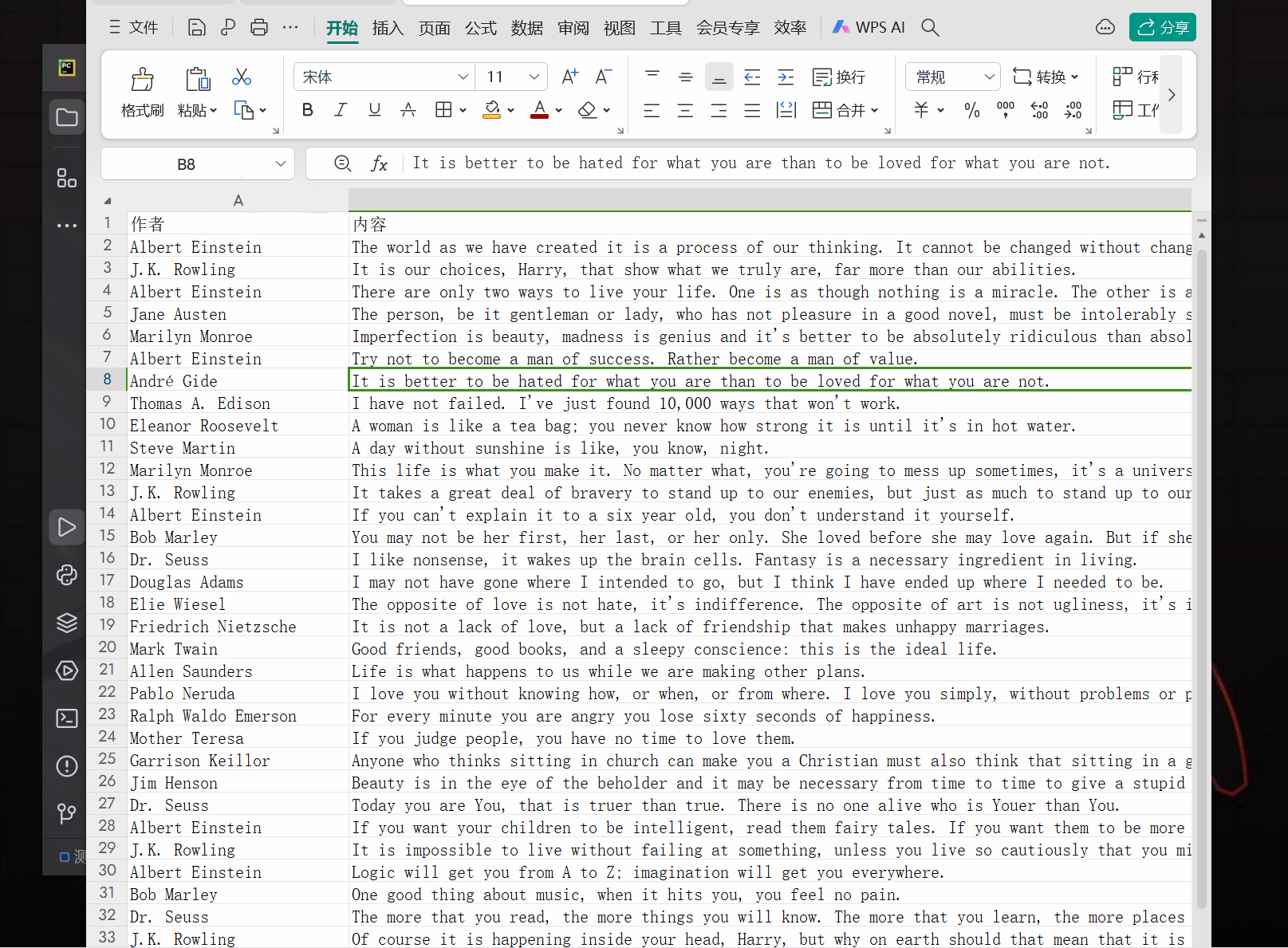
ws.append(['作者','内容','标签'])
for page in range(1,6):
url = f'https://quotes.toscrape.com/page/{page}/'
res_data= requests.get(url=url, headers=headers)
res_data.encoding = "utf-8"
res_data = res_data.text
tree = etree.HTML(res_data)
quotes = tree.xpath('//div[@class="col-md-8"]//div[@class="quote"]')
for i in quotes:
content = i.xpath('.//span[@class="text"]')
author = i.xpath('.//span//small[@class="author"]')
author = author[0].text
content = content[0].text.replace('“', '').replace('”', '')
tags = i.xpath('.//div[@class="tags"]//a[@class="tag"]')
tags_list = []
for i2 in tags:
tags_list.append(i2.text)
tag = ','.join(tags_list)
print(author, '=',content, "=",tag)
ws.append([author, content, tag])
wb.save("保存结果.xlsx")
总结
-
希望对初学者有帮助
-
致力于办公自动化的小小程序员一枚
-
希望能得到大家的【一个免费关注】!感谢
-
求个 🤞 关注 🤞
-
-
求个 ❤️ 喜欢 ❤️
-
-
求个 👍 收藏 👍
-


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











