






量化的概念就不必多说。直接看公式
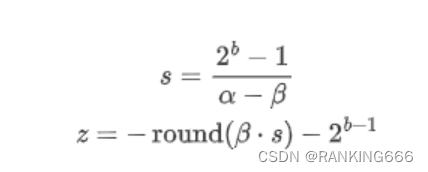
1. 量化分为对称量化和非对称量化:
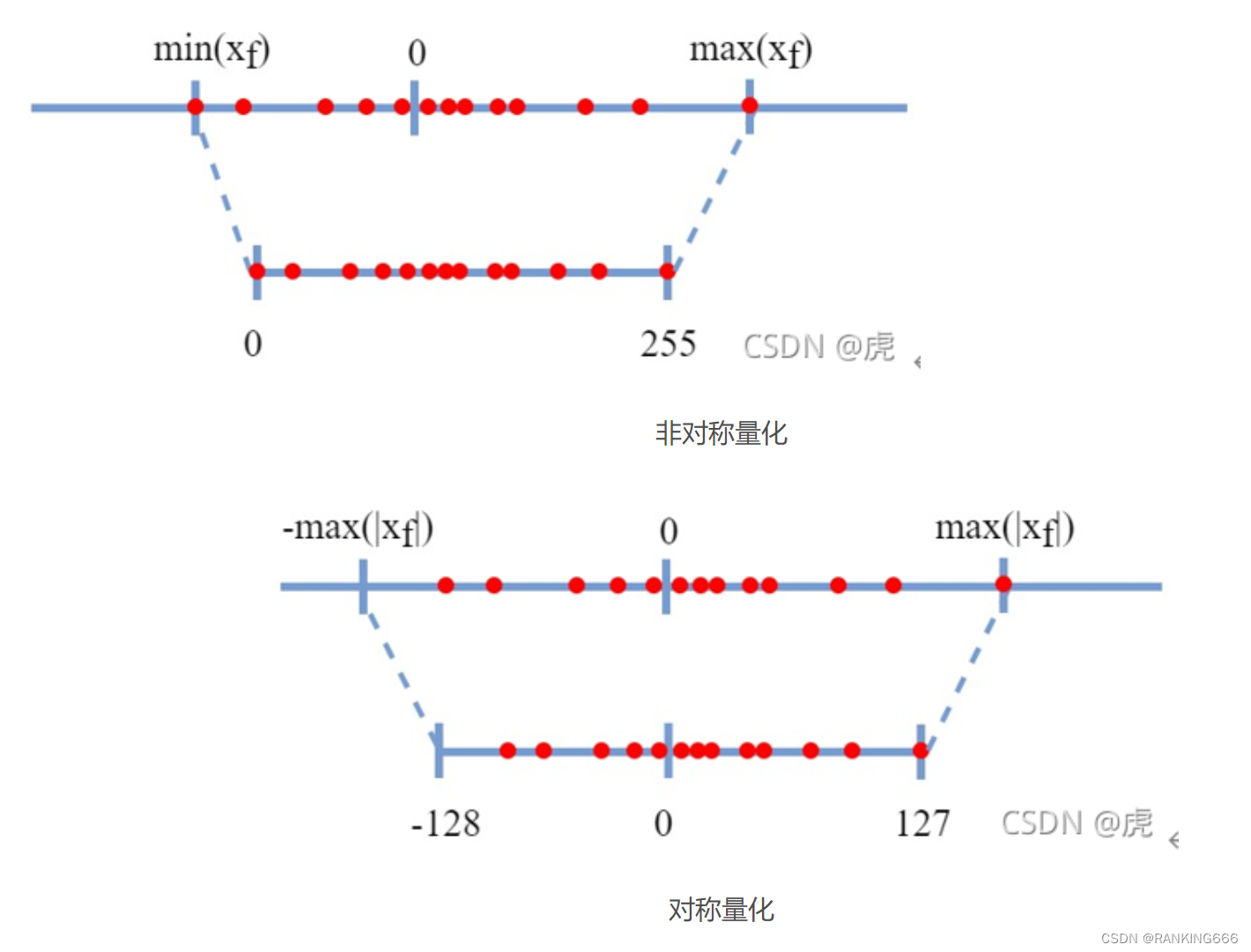
对称量化就是取浮点数的最大绝对值,扩展,比如映射到-127-127,而非对称量化很简单就是最大值对应255,最小值对应0。
这里需要注意的是对于z的计算,对称量化的z就是0,相对简单。
同时,在考虑到硬件实际加速效果时,一般来说对激活使用非对称量化,而对权重采用对称量化。具体看公式:

可以看到,在都是非对称量化时,模型前向推理计算一共有四项,
对于第一项来说无论是对称还是非对称量化都是共有项 ,故无法避免(当然也不能避免这是计算的主力呀),
对于第三和第四项来说,是在推理之前已经预设好的,故在推理过程中也不会增加计算负担,
而对于第二项来说,可以看到是包含Xint的,意思是对于没批数据,我们都需要在推理过程中增加一个计算的附加项,这会导致延迟和功耗方面的显着开销,因为它相当于添加了一个额外的通道。所以第二项希望能够去除。故Zw为0即可,因此对于权重采用对称量化。
①这就引出一个新的问题,那既然非对称量化会引入Z,那为什么还要采用非对称量化来增加第三和第四项呢?
首先,对称量化对于离散的最值是非常敏感的,因为量化的方法是找到最值然后左右映射;其次,在激活函数是relu的时候,激活值全大于0,这个情况下还是用对称量化就会浪费一个bit的表示能力,只能[0, 127];
2. per-tensor和per-channel量化:
per-tensor就是整个神经网络层用一组量化参数(scale, zero-point),per-channel就是一层神经网络每个通道用一组量化参数(scale, zero-point)。那么就是per-channel需要存更多的量化参数,对gemm的计算也有一点影响。
可以想象到per-channel量化很明显细粒度更高,所以一般来说效果会更好,但当前主流的量化仍然是权重和激活都采用per-tensor量化。
第一点:简单节省内存,虽然现在每个通道的权重量化越来越普遍,但并不是所有的商业硬件都是支持的,因此,重要的是需要检查硬件设备是否支持。第二点:对于激活来说,通道量化是非常困难的,因为我们不能将scale从求和中剔除,因此需要为每个输入通道重新调整累加器的scale。因为每一层计算都是对应通道乘再加上去的,如果每个通道的量化区别很大,就会对结果产生很大的误差。
3. 量化与反量化:
反量化一般是用在QAT中,这个之后再说,反量化就是把量化的浮点数再反量化为浮点数:float->int->float。这里在QAT中再详细介绍。
4. PTQ和QAT:
PTQ指的是采用预先训练好的FP32模型,将其直接转换为定点模型。
优点:PTQ简单方便快捷,只需要少量的校准数据甚至不需要数据,在短时间就能完成量化的工作。
PTQ用起来确实很好用,但是精度的表现是不如QAT的,所以需要其他的方法提高精度。尤其是在针对激活的低位量化(例如 4 位及以下)时。PTQ技术可能不足以减轻低位量化引起的大量化误差。在这些情况下,我们求助于量化感知训练 (QAT)
min-max对于离群值敏感,效果差,其他校准的策略来说,相对简单效果更好的有:KL散度(KL divergence):最小化量化后int8与float32数据的KL散度,tensorrt采用这个策略。百分比(Percentile):选取tensor的99%或者其他百分比的数值,其余的截断。等等,高级一点的还有MSE,CE,BN based range setting(作者也还没看过,之后会看看)。还有将量化范围定为可以训练的参数LSQ(待补充)
QAT指的是在训练期间对量化噪声源进行建模。这允许模型找到比训练后量化更多的最优解。然而,更高的准确性伴随着神经网络的训练成本,即更长的训练时间、需要标记数据和超参数搜索。
QAT就是在训练中插入fake quantize节点 做dequantize(quantize(x, b, s), b, s),对quantize这个节点因为导数为0,采用STE(即梯度为0)来解决。
5. Add量化和Concat量化:
Add量化主要看公式:
![]()
![]()

但是在实际过程中,应该是两个输入的量化范围必须完全匹配。
Concat量化看公式:
![]()
![]()
![]()
与Add类似,两个分支通常不共享相同的量化参数,从而需要Requantization。
6. 零散点
BN融合:就是在推理过程中将Bn层和conv层的参数进行融合,两层融合为一层:
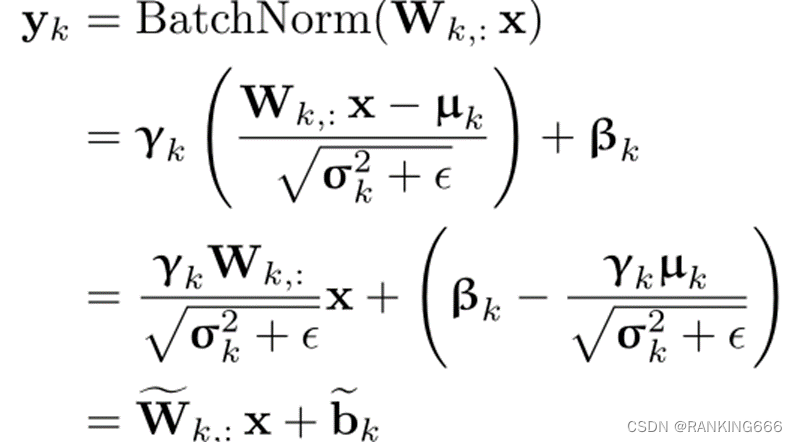
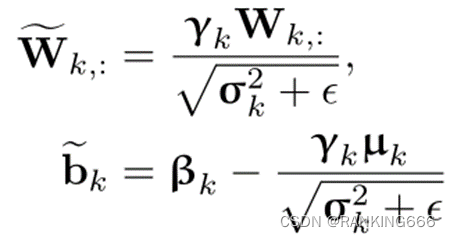
需要注意的是,在BN融合时per-channel和per-tensor就会产生区别,对于per-channel来说BN参数刚好可以每次都融合到每个 channel的scale里,对性能几乎不会产生影响。而对于per-tensor来说每个通道的BN参数不一样,如果想要直接融合进 scale里面,就变成了通道数个scale_k,如果选一个最大的scale_k,性能就会崩坏。意思是说per-tensor对于所有的通道都采用了统一的量化参数,而每个通道的BN层参数其实是不一样的。(待补充)
同时在QAT中使用BN融合也会出现很多的问题:首先:如果QAT训练时就直接将BN完全融合到卷积进行训练,相当于BN没有了,会造成梯度爆炸,其次,如果QAT过程中将BN层和卷积继续分置,只在部署推理的时候做结合,会带来BN融合的消极效应。也就是上面说的per-tensort的影响。
解决方案:静态融合与两次前向传播(待补充)
Cross-Layer Equalization(CLE)跨层均衡:量化误差的一个常见问题是,同一张量中的元素大小可能显著不同。不同的量化范围设置方案就是试图在裁剪和舍入误差之间找到一个好的折衷。但有时候折中不了。比如在深度可分离卷积中尤其普遍,因为用少量的权重负责每个输出特征,这可能导致权重的更高可变性。BN融合会加重这一效应,并可能导致连接到各种输出通道的权重之间的严重不平衡。虽这对于更细粒度的量化粒度(例如,每通道量化)来说不是什么问题,但对于更广泛使用的per-Tensor量化来说,这是一个大问题。(待补充)
Bias correction(偏差校准):因为量化误差通常是偏移性的,即原始的期望输出和量化后该层或该网络的输出相比,发生了移位。(待补充)
AdaRound:像一般的直接Round采用的四舍五入的方法并不能得到最优的结果,因此有各种各样的优化算法。(待补充)
激活融合:实际操作中,我们往往会在线性运算之后直接进行非线性激活。因此,许多硬件解决方案都带有在重新量化步骤之前应用非线性的硬件单元。为了保证一致性,我们需要在激活之后再进行量化,并且可以使用激活融合的方式。例如,RELU只需将该激活量化的最小可表示值设置为0。(待补充)
Partial Quantization(部分量化):量化后对模型效果影响比较大(也就是更加敏感)的就用高比特来表示,用float32/float16/int16。这个敏感度判别采用最直接简单的方法:每次只量化一层跑一遍,看模型效果的影响,影响大的就更敏感,反之就不敏感。
打打 模型,将其直接转换为定点模型。训练后量化 (PTQ) 算法采用预先训练好的 FP32 模型,将其直接转换为定点模型。训练后量化 (PTQ) 算法采用预 FP32 模型,将















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









