







目录
3.1.1 Initial Capacity与Load Factor
概述
HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用nul键和null值,因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的。
数据结构
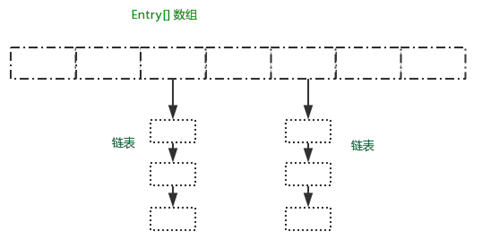
HashMap底层是以数组+链表方式进行存储,通过对key的hash计算和数组长度得到value在数组中存储的位置(index = hash值 & (length - 1))。当不同的key的hash值相同时,对应数组的位置将生成一个链表来储存相同hash的value值(在JDK 1.8之前,新插入的元素都是放在了链表的头部位置,但是这种操作在高并发的环境下容易导致死锁,所以JDK 1.8之后,新插入的元素都放在了链表的尾部,并且链表长度超过8时会转化为红黑树存储)。
HashMap总体存储结构如下图所示。
方法分析
2.1 put()
在该方法中,添加键值对时,首先进行table是否初始化的判断,如果没有进行初始化(分配空间,Entry[]数组的长度)。然后进行key是否为null的判断,如果key==null ,放置在Entry[]的0号位置。计算在Entry[]数组的存储位置,判断该位置上是否已有元素,如果已经有元素存在,则遍历该Entry[]数组位置上的单链表。判断key是否存在,如果key已经存在,则用新的value值,替换点旧的value值,并将旧的value值返回。如果key不存在于HashMap中,程序继续向下执行。将key-vlaue, 生成Entry实体,调用addEntry()方法,添加到HashMap中的Entry[]数组中。

2.2 addEntry()
添加方法的具体操作,在添加之前先进行容量的判断,如果当前容量达到了阈值,并且需要存储到Entry[]数组中,先进行扩容操作,扩充的容量为table长度的2倍。重新计算hash值,和数组存储的位置,扩容后的链表顺序与扩容前的链表顺序相反。然后将新添加的Entry实体存放到当前Entry[]位置链表的头部。

2.3 get()
在get方法中,首先计算hash值,然后调用indexFor()方法得到该key在table中的存储位置,得到该位置的单链表,遍历列表找到key和指定key内容相等的Entry,返回entry.value值。 
2.4 remove()
删除操作,先计算指定key的hash值,然后计算出table中的存储位置,判断当前位置是否Entry实体存在,如果没有直接返回,若当前位置有Entry实体存在,则开始遍历列表。定义了三个Entry引用,分别为pre, e ,next。 在循环遍历的过程中,首先判断pre 和 e 是否相等,若相等表明,table的当前位置只有一个元素,直接将table[i] = next = null 。若形成了pre -> e -> next 的连接关系,判断e的key是否和指定的key 相等,若相等则让pre -> next ,e 失去引用。 
疑问解答
“如果两个key的hashcode相同,你如何获取值对象?”答案:当我们调用get(key)方法,HashMap会使用key的hashcode值,找到bucket位置,然后获取值对象。
“如果有两个值对象,储存在同一个bucket ?”答案:将会遍历链表直到找到值对象。
“这时会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?”答案:找到bucket位置之后,会调用keys.equals()方法,去找到链表中正确的节点,最终找到要找的值对象。
HashMap的线程是不安全的,多线程环境中推荐是ConcurrentHashMap。
扩容原理
3.1 HashMap的容量与性能
HashMap的性能受到两个参数的影响:初始化容量和负载因子,下面来详细讲述这几个关键问题。
3.1.1 Initial Capacity与Load Factor
Initial Capacity:
初始化容量,它表示HashMap底层的那个数组,也就是Entry数组有多长,这个值默认是16。
Load Factor:
负载因子,它表示HashMap的负载程度,换句话说,它表示HashMap到底有多满了,是不是需要扩容了,这个值默认是0.75f。
初始化容量和负载因子的默认值是Java官方经过实践和优化得到的数据,可以适应大多数的场景。
当然也可以不使用其默认值,可以在构造的时候,自定义HashMap的容量和负载因子:
//单纯指定容量
Map<String,String> hashMapWithCapacity=new HashMap<>(64);
//自定义容量和负载因子
Map<String,String> hashMapWithCapacityAndLF=new HashMap<>(64, 0.9f);一旦需要自定义容量和负载因子,我们需要搞清楚,他们到底是什么,用来干嘛,会对性能造成什么影响。
一句话:这两个数值会影响到HashMap的扩容,而扩容是一个对性能影响非常大的操作。
3.2 HashMap的扩容
3.2.1 扩容是什么
HashMap的扩容:HashMap被初始化之后,其容量是有限的(可以是默认,也可以是自定义的),当元素不断被插入,是HashMap达到一定的程度(负载因子决定),这个时候,HashMap就会扩容。
根据源码,使用公式表示,是否扩容由容量和负载因子的乘积决定!!!!
触发扩容的条件:
HashMap.Size >= Capacity * LoadFactorHashMap.Size:当前HashMap的实际元素个数
Capacity:容量
LoadFactor:负载因子
如果在默认值的条件下:
HashMap.Size = 16 * 0.75 = 12也就是,默认的情况下,插入十二个元素的时候,就会触发扩容。
3.2.2 扩容的步骤
一旦HashMap的size超过了Capacity * LoadFactor乘积,就会触发扩容,那如何扩容呢?,需要经过两步:
resize:即:创建一个new Entry数组,长度是原来old Entry的2倍。
rehash:遍历old Entry数组,把里面的每一个元素取出来重新计算hash和index。为什么要重新计算呢?想一想之前的index计算公式:
index = hash值 & (length - 1)对,因为长度已经改了,所以index肯定会不一样,举个例子:
当原数组长度为16时,Hash运算是和1111做与运算;
新数组长度为32,Hash运算是和11111做与运算。
Hash结果显然不同。
3.3 什么时候触发扩容?
一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍。
HashMap的容量是有上限的,必须小于1<<30,即1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为Integer.MAX_VALUE(2的31一次方 - 1)。
3.3.1 JDK7中的扩容机制
JDK7的扩容机制相对简单,有以下特性:
- 空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。
- 有参构造函数:根据参数确定容量、负载因子、阈值等。
- 第一次put时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据负载因子确定阈值。
- 如果不是第一次扩容,则 新容量=旧容量*2,新阈值=新容量*负载因子。
3.3.2 JDK8的扩容机制
JDK8的扩容做了许多调整。
HashMap的容量变化通常存在以下几种情况:
- 空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
- 有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让阈值=容量*负载因子 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
- 如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
3.3.3 JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
- 是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。
- 因为是头插法,因此新旧链表的元素位置会发生转置现象。
- 元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
3.3.4 JDK8的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因如下图:
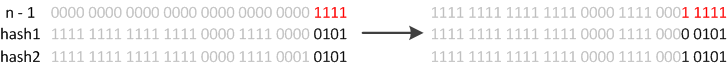
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:
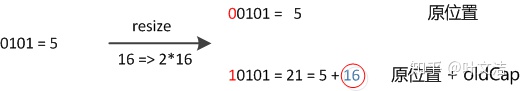
(图片来源于文末的参考链接)
因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节:
- JDK8在迁移元素时是正序的,不会出现链表转置的发生。
- 如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。
3.4 总结
Initial Capacity设置高:大量存储,少量迭代
Initial Capacity设置低:数据少,迭代频繁
参考链接:
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









