






背景介绍
对于联邦学习我们常常考虑的是保护隐私的分布式有监督学习任务的训练。该文章考虑的是联邦学习怎么用于无监督学习之一的聚类问题。该文章研究的主要问题是每个client由于数据局限性,只有部分的类别数据,在这样数据异构(Non-IID)的情况下如何进行高效的聚类。此外,该方法也可以帮助一些监督学习联邦学习,特别是基于聚类的个性化联邦学习算法。
该论文提出的方法最大的特点是one-shot,client只需要与server进行一次数据传输即可。具有较强的鲁棒性并能减少开销。此外,该论文还发现数据异构(Non-IID)有利于聚类任务的性能,也就是说对于很多监督学习来说的Non-IID问题反而促进了聚类任务的完成。
相关工作
集中式聚类
最经典的K-means算法(since 1982),因为简单高效经久不衰。随机初始化k个聚类中心,再根据每个点到聚类中心距离进行归类,更新聚类中心为类中所有点的平均值。
之后有更多研究关注更好的初始化聚类中心,能够达到更快的收敛速度。
本文中本地的聚类过程就是采用一个更高效的初始化中心的K-means算法
分布式聚类方法
文中也列出了有关注通信效率并效果好的聚类方法。但他们没有关注到联邦学习领域中数据异构的问题,及每个分布点的数据包含的类别数量不是一样的
联邦聚类
过去的联邦聚类都是关注于怎么划分Client,是个性化联邦学习的上游任务。本文主要关注的是如何对数据本身进行聚类。当然本文也验证了其方法在划分client中的有效性。
K-FED的具体设计
对聚类问题的建模采用一个矩阵优化的损失函数
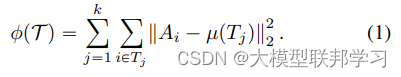
其中A矩阵是聚类结果,
A
∈
R
n
×
d
A\in R^{n \times d}
A∈Rn×d, 为n个聚类中心的表示,d为数据点的维度.


实验
数据集构造
按照不同高斯分布生成数据点,每个client只有部分高斯分布的结果

异构性带来的好处
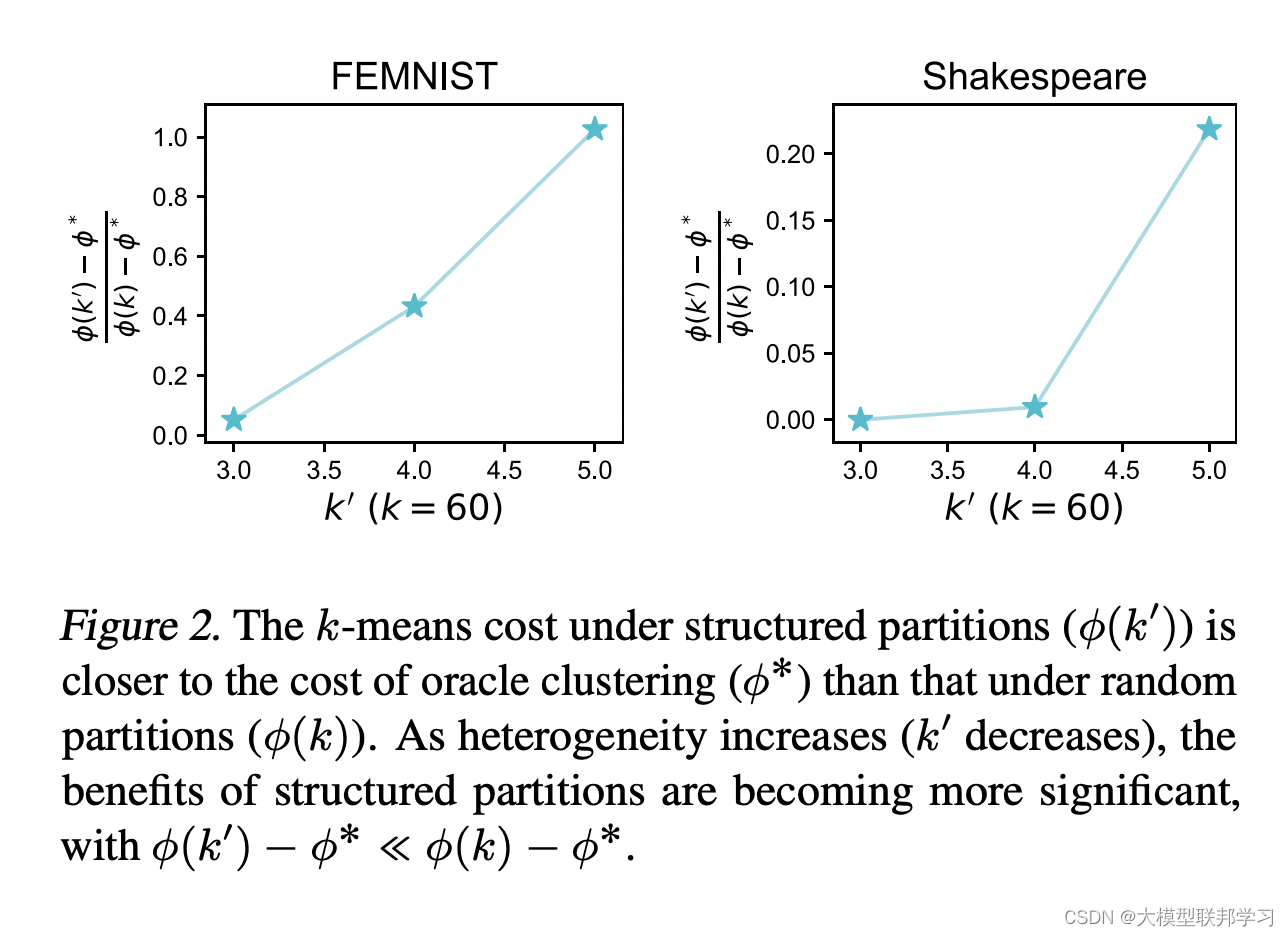
k‘越小,相比于最大k的聚类结果,离集中式聚类结果的差距越小














 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









