







一、C++为何复杂
- C++提供了更多的内存模型。第一种就是提供了太多的可以放对象的地方,如堆栈中、栈中、全局数据区里面。第二种就是提供了太多可以访问对象的方式,直接访问、指针访问、引用访问。
new出来的放在堆中,局部变量放在栈中,全局变量以及静态变量放在全局数据区中。 - JAVA的内存模型要简单很多,所有对象都只能放在堆里面,然后只有一种方式去访问那个对象,就是通过引用。(当然,也可以说成是指针。但因为JAVA只有一种方式去访问,所以开发人员干脆就把星号去掉,然后JAVA开发者和别人说我这个不叫指针叫引用,但其实它和C++的引用是不一样的,它更像是C++的指针)
- JAVA指针(引用)和C++指针的区别:
- 没有*号
- 不能计算
- JAVA指针(引用)和C++引用的区别:
- C++引用绑定一个变量后不能换一个变量来绑定(专一)
- JAVA指针(引用)和C++指针的区别:
二、引用
int x=4;
int &y = x;
- 引用相当于为变量取一个别名,双方绑定在一起。访问y的地址其实就是访问x的地址,这和指针是不同的。
- 引用初始化时右值必须是一个变量,不能是常数。这与指针不同,指针的右值可以是一个常数。
- 当然,其实也存在一种可能,引用的右边可以是一个常量,那就是引用和Const配合使用!
void test(const int &i){
cout<<"成功了"<<endl;
}
test(3); //成功了 ,为什么可以这样我也不知道?????
- 引用绑定后,是无法更改的,也就是说y不能在再和其它的变量进行绑定。这也和指针是不同的。
- C++有了指针为什么还要新增引用的定义???
- 为了使代码少一点
*号,使得代码更简洁易懂
- 为了使代码少一点
缺点:
void fun1 (int &x){}
void fun2(int x){}
int main(){
int y=23;
fun1(&y); //Ugly ,but explicit
fun2(y); //Clean , but hidden
}
也就是说,对于使用引用类型参数的函数,仅仅通过函数调用是无法知道fun(y),这个传进去的y是拷贝还是引用,无法确定y会不会在函数内被改变。
二、引用的限制, 引用和指针一起用的效果
No references to references// && 是非法的No pointers to references
int &* p; //error
离p近的是* 因此p是一个指针类型,它指向的是一个int类型的引用。 也就是说p存储的是引用的地址。我们知道引用的地址是无法获取到的(获取到的是引用所引用的变量的地址),因此 int &* p;是不可行的。
Reference to pointer is ok
void fun(int *& p){} // it's OK
离p近的是&,因此p是一个引用类型,所引用对象是一个指向int类型的指针。这是可行的。
No arrays of references
三、邪恶的指针
下面我们来看一个可以欺骗编译器的指针并越权使用的例子
class A{
private:
int a;
const int b;
public:
A():a(10),b(10){};
void fun(){ cout<<a<<" b:"<<b<<endl; };
};
我们知道const类型(b)的变量是不可以改变的,类中private的变量(a)外界是无法直接访问的,但其实通过指针是统统可以做到的。
int main() {
A a;
int *p = (int *)&a;
*p=20; //这里就直接访问了私有变量a的值
a.fun(); //这里输出:20 , 10
p++; //让指针指向const型变量b
*p=50;
a.fun(); //这里输出: 20 , 50
}
在上述代码中,a对象的一个私有变量a 和 私有且是const类型的变量b,均可以通过指针来访问并肆无忌惮的修改。 C++的对象其实就像是一个指针数组,可以通过地址偏移来访问成员表。C++之所以留下这种这些不安全的机制,可能是为了更好的兼容C语言吧。
三、向上造(转)型
一、用法
- D is derived from B //Derive Base
- D --> B // B b =d;
- D* --> B* // B * b =&d ;
- D& --> B& // B & b = d ;
四、虚函数与多态
一、先看用法举例
class A{
public:
virtual void fun1();
virtual void fun2();
};
class B : public A{
public:
virtual void fun2();// 重写了基类的方法
};
int main(){
A a;
B b;
A *a1_ptr = &a;
A *a2_ptr = &b;
// 当派生类“重写”了基类的虚方法,调用该方法时
// 程序根据 指针或引用 指向的 “对象的类型”来选择使用哪个方法
a1_ptr->fun2();// call A::fun2();
a2_ptr->fun2();// call B::fun1();
// 否则
// 程序根据“指针或引用的类型”来选择使用哪个方法
a1_ptr->fun1();// call A::fun1();
a2_ptr->fun1();// call A::fun1();
}
- 可以看出,当派生类重写了基类的虚方法,调用该方法时,程序将根据指针或引用所
指向的"对象的类型”选择用哪个方法。 - 如果不是虚函数,则根据
指针或引用 的类型来选择使用哪个方法。 - 下面来看看如何用虚函数实现多态,这个例子的代码中所使用的类来自上一个例子。
void fun(A * pr){ //类外定义一个函数,
pr->fun2();
};
int main() {
A a;
B b;
fun(&a); // call A::fun2();
fun(&b); // call B::fun2();
}
二、虚函数实现原理
- 这个图来自https://www.cnblogs.com/malecrab/p/5572730.html
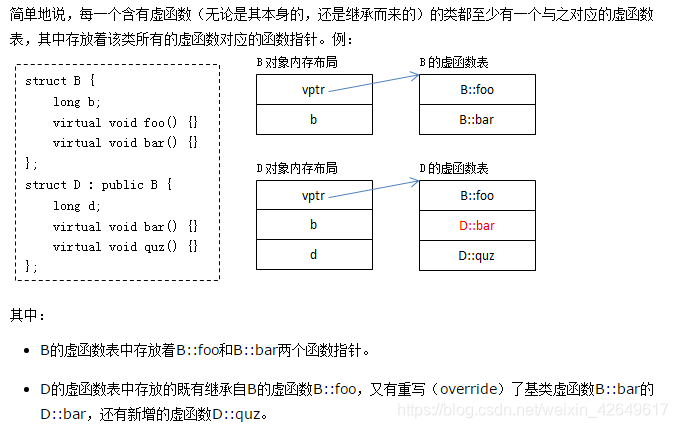
- 任何一个类,只要里面多加一个visual关键字,这个类所分配的空间就会大一点。
- 每个类都会有一张虚函数地表,如果派生类没有重新定义虚函数,则自类的虚函数表将保存
父类的版本。如果派生类重新定义了则更新一下。 - 调用函数时,程序将查看存储再对象中的虚函数表地址,转向相应的虚函数表,找到所要执行的函数执行。(查找哪个类的虚函数表,是根据
指针或引用所指向的对象来决定) 静态绑定:代码所要调用的函数是确定的,在编译阶段就非常明确的知道到底应该调用哪个函数。动态绑定:代码所要调用的函数是不确定的,只有在运行阶段才能知道应该调用哪个函数。而使用虚函数实现程序的多态性就是动态绑定!- 其它oop语言都是默认就是动态绑定的,比如说JAVA。只有C++默认是静态绑定,那么C++为什么要这么干呢,其实是因为静态绑定的效率要高于动态绑定。
需要注意的是:- 如果基类有虚函数,那么派生类重写了这个虚函数,但函数前面不写vistual,那么这个派生类的函数也是虚函数
- 如果基类某个函数不是虚函数,那么派生类即便重写了这个非虚函数,且还加上visual,也无法实现多态,因为父类这个函数不是虚函数。
- 构造函数不能为虚函数。
- 基类的析构函数应该为虚函数。
- delete p; 假如这个代码的本意是释放p所指向的对象的内存,但如果p这个指针是一个基类类型的指针,那么就有可能调用基类的析构函数,从而造成混乱
- 友元函数不能为虚,因为友元函数不是类成员,只有类成员才能是虚函数。
五、函数隐藏
https://blog.csdn.net/buknow/article/details/80517594 这篇博客写的非常好
- 函数重写:也称作
覆盖,是用于类的继承中,函数名、参数个数、类型都相同,仅函数体不同。 //基类函数必须是虚函数 - 函数重载:是指同一作用域的不同函数使用相同的函数名,但是参数个数或类型不同。
- 函数隐藏:既不是重载也不是重写,例如:函数名及参数完全相同却又不是虚函数,却在子类中重新实现该函数,也就是所谓的隐藏。(有点像是不同作用域的’重载’)
- 如果派生类的函数与基类的函数
同名,但是参数不同。此时,不论有无virtual关键字,基类的函数都将被隐藏。(注意与重载区分)
②如果派生类的函数与基类的函数同名,且参数也相同,但是基类函数没有virtual关键字。此时,基类的函数被隐藏。(注意与覆盖区分)
- 如果派生类的函数与基类的函数
函数隐藏:
- 同名 、不同参数。
- 同名、同参数、非虚函数
函数重写、覆盖:
- 同名、同参、虚函数
函数重载:
- 同一区域内、同名、不同参`
五、拷贝构造
一、先看例子
int num=0; //用于计数
class B{
public:
B(){ num++; cout<<"Call the B() , num = "<<num<<endl; };
~B(){ num--; cout<<"Call the ~B() , num = "<<num<<endl; };
};
void fun(B b) { //这个 B b = x; 它没有调用B() 这个构造函数,但却使用了~B()函数
cout<<"Call the fun(B b) , num = "<<num<<endl;
};
int main() {
B x;
fun(x);
}
运行结果如下:
Call the B() , num = 1
Call the fun(B b) , num = 1 //明明创建了对象b, 但却没有调用对应B()构造函数
Call the ~B() , num = 0
Call the ~B() , num = -1
Press any key to continue
可以明显的看到诡异之处,fun(B b)这个函数中虽然初始化了一个对象b,但却没有调用构造函数,却使用了析构函数,从而导致num 最终不是0了。
二、原理
- 对象的初始化可以是 B b; 或者 B b(10); 其实也可以这样写:
B b = 10; //这就相当于B b(10);
- 因此,在fun(B b)这个函数中局部变量b的初始化有这么一个过程:
B b = x;,其实这就相当于B b(x); 虽然我们所创建的类中并没有写出 B(B b)这种类型的构造函数,但其实编译器会自动帮我们生成一个!这样就可以很好的解释了为什么num最后不是=0的问题了。我们可以自行创建一个构造函数: B::B(B b){num++; } 。 这样就可以解决num不为0的问题,在这里不做测验。- B::B(B b){ } ,这就叫做拷贝构造。
三、注意事项:
- B::B(B b){ } ,这就叫做拷贝构造。
- 如果类中有
指针型变量的话,那么如果使用了系统默认的拷贝构造之后将会出现很大的问题。通过拷贝构造函数初始化的新对象 中的指针型变量 所指向地址和被拷贝的对象中 的指针型变量 所指向的地址完全一样。这样就会进行两次delete操作 重复释放内存, 就会报错。 - 因此当类中存在指针型变量时,要自己重写一个拷贝构造函数,为指针型变量新分配一块内存。另外,这里给一个建议:一个类创建之后,最好要有三个函数:
默认构造函数、虚析构函数、拷贝构造函数
四、补充
- 所谓
浅拷贝,就是说编译器提供的默认的拷贝构造函数和赋值运算符重载函数,仅仅是将对象中各个数据成员的值拷贝给另一个同一个类对象对应的数据成员。 - 在`深拷贝情况下,对于对象中动态成员,就不能仅仅简单地赋值,而应该重新动态分配空间。
- 详细内容待需要时在深究。














 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









