






取模分片
以 orders 表为例,分片键为customer_id,根据customer_id取模分别将数据插入dn1和dn2节点。
修改schema.xml
#为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为 mod_rule(自定义的名字)
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ></table>

修改rule.xml
#在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id,
#还有选择分片算法 mod-long(对字段求模运算),customer_id 对两个节点求模,根据结果分片
#配置算法 mod-long 参数 count 为 2,两个节点
<tableRule name="mod_rule">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
…
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>

分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务
需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则。
修改schema.xml配置文件
<table name="orders_ware_info" dataNode="dn1,dn2" rule="sharding_by_intfile" ></table>
修改rule.xml配置文件
(2)修改rule.xml配置文件
<tableRule name="sharding_by_intfile">
<rule>
<columns>areacode</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
…
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
</function>
# columns:分片字段,algorithm:分片函数
# mapFile:标识配置文件名称,type:0为int型、非0为String,
#defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,
# 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错
修改partition-hash-int.txt配置文件
110=0
120=1
创建orders_ware_info,并且插入数据
CREATE TABLE orders_ware_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`address` VARCHAR(200) comment '地址',
`areacode` VARCHAR(20) comment '区域编号',
PRIMARY KEY(id)
);
#(6)插入数据
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'北京','110');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,'天津','120');
查询Mycat、dn1、dn2可以看到数据分片效果

范围约定分片
修改schema.xml配置文件
<table name="payment_info" dataNode="dn1,dn2" rule="auto_sharding_long" ></table>
#(2)修改rule.xml配置文件
<tableRule name="auto_sharding_long">
<rule>
<columns>order_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
..
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
# columns:分片字段,algorithm:分片函数
# mapFile:标识配置文件名称
#defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,
# 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就
#报错
修改autopartition-long.txt配置文件
0-102=0
103-200=1
连接mycat创建表并且插入数据
CREATE TABLE payment_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`payment_status` INT comment '支付状态',
PRIMARY KEY(id)
);
#(6)插入数据
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);
INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);
发现dn1和dn2都有该表且数据分步如下

按时间分片
修改schema.xml配置文件
<table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table>
修改rule.xml配置文件
<tableRule name="sharding_by_date">
<rule>
<columns>login_date</columns>
<algorithm>shardingByDate</algorithm>
</rule>
</tableRule>
…
<function name="shardingByDate" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2019-01-01</property>
<property name="sEndDate">2019-01-04</property>
<property name="sPartionDay">2</property>
</function>
# columns:分片字段,algorithm:分片函数
#dateFormat :日期格式
#sBeginDate :开始日期
#sEndDate:结束日期,则代表数据达到了这个日期的分片后循环从开始分片插入
#sPartionDay :分区天数,即默认从开始日期算起,分隔 2 天一个分区
连接mycat建表插入数据
CREATE TABLE login_info
(
`id` INT AUTO_INCREMENT comment '编号',
`user_id` INT comment '用户编号',
`login_date` date comment '登录日期',
PRIMARY KEY(id)
);
#(6)插入数据
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2019-01-01');
INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2019-01-02');
INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2019-01-03');
INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2019-01-04');
INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2019-01-05');
INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2019-01-06');
然后发现dn1和dn2都有该表且数据分布如下:

最终的scheml.xml文件
<?xml version="1.0" encoding="GBK"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<!-- 垂直分表customer表 在dn2节点上 -->
<table name="customer" dataNode="dn2" ></table>
<!-- 水平分表orders表 为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为 mod_rule(自定义的名字) -->
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" >
<!--join查询 主表orders主键id关联 副表orders_detail主键order_id-->
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
<!--全局表-->
<table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>
<!--分片枚举-->
<table name="orders_ware_info" dataNode="dn1,dn2" rule="sharding_by_intfile" ></table>
<!--分片范围内-->
<table name="payment_info" dataNode="dn1,dn2" rule="auto_sharding_long" ></table>
<!--分片时间范围-->
<table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table>
</schema>
<!-- dn1节点 -->
<dataNode name="dn1" dataHost="host1" database="orders" />
<!-- dn2节点 -->
<dataNode name="dn2" dataHost="host2" database="orders" />
<!-- dn1节点数据库host1信息 -->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.174.130:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<!-- dn2节点数据库host2信息 -->
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="192.168.174.10:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
最终的rule.xml
<?xml version="1.0" encoding="GBK"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<!--取模分片-->
<tableRule name="mod_rule">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<!--枚举分片-->
<tableRule name="sharding_by_intfile">
<rule>
<columns>areacode</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<!--范围内分片-->
<tableRule name="auto_sharding_long">
<rule>
<columns>order_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<!--时间范围内分片-->
<tableRule name="sharding_by_date">
<rule>
<columns>login_date</columns>
<algorithm>shardingByDate</algorithm>
</rule>
</tableRule>
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 榛樿鏄? -->
<property name="count">2</property><!-- 瑕佸垎鐗囩殑鏁版嵁搴撹妭鐐规暟閲忥紝蹇呴』鎸囧畾锛屽惁鍒欐病娉曞垎鐗?-->
<property name="virtualBucketTimes">160</property><!-- 涓€涓疄闄呯殑鏁版嵁搴撹妭鐐硅鏄犲皠涓鸿繖涔堝铏氭嫙鑺傜偣锛岄粯璁ゆ槸160鍊嶏紝涔熷氨鏄櫄鎷熻妭鐐规暟鏄墿鐞嗚妭鐐规暟鐨?60鍊?-->
<!-- <property name="weightMapFile">weightMapFile</property> 鑺傜偣鐨勬潈閲嶏紝娌℃湁鎸囧畾鏉冮噸鐨勮妭鐐归粯璁ゆ槸1銆備互properties鏂囦欢鐨勬牸寮忓~鍐欙紝浠ヤ粠0寮€濮嬪埌count-1鐨勬暣鏁板€间篃灏辨槸鑺傜偣绱㈠紩涓簁ey锛屼互鑺傜偣鏉冮噸鍊间负鍊笺€傛墍鏈夋潈閲嶅€煎繀椤绘槸姝f暣鏁帮紝鍚﹀垯浠?浠f浛 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
鐢ㄤ簬娴嬭瘯鏃惰瀵熷悇鐗╃悊鑺傜偣涓庤櫄鎷熻妭鐐圭殑鍒嗗竷鎯呭喌锛屽鏋滄寚瀹氫簡杩欎釜灞炴€э紝浼氭妸铏氭嫙鑺傜偣鐨刴urmur hash鍊间笌鐗╃悊鑺傜偣鐨勬槧灏勬寜琛岃緭鍑哄埌杩欎釜鏂囦欢锛屾病鏈夐粯璁ゅ€硷紝濡傛灉涓嶆寚瀹氾紝灏变笉浼氳緭鍑轰换浣曚笢瑗?-->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
<function name="shardingByDate" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2019-01-01</property>
<property name="sEndDate">2019-01-04</property>
<property name="sPartionDay">2</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat 提供
了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式
数据库方式
利用数据库一个表 来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。
Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。
如果内存中的号段用完了 Mycat 会再向数据库要一次。
问:那如果 Mycat 崩溃了 ,那内存中的序列岂不是都没了?
是的。如果是这样,那么 Mycat 启动后会向数据库申请新的号段,原有号段会弃用。
也就是说如果 Mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复
建立数据库脚本
#在 dn1 上创建全局序列表
CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOT
NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB;
#创建全局序列所需函数
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS
VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
#初始化序列表记录
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,
100);
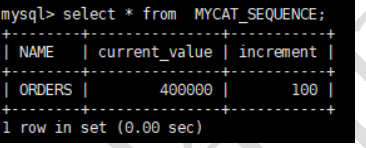
修改 Mycat 配置
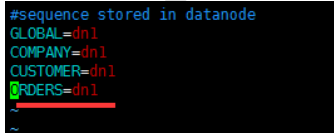
#修改sequence_db_conf.properties
vim sequence_db_conf.properties
#意思是 ORDERS这个序列在dn1这个节点上,具体dn1节点是哪台机子,请参考schema.xm
#修改server.xml
#全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1

验证
#登录 Mycat,插入数据
insert into orders(id,amount,customer_id,order_type) values(next value for
MYCATSEQ_ORDERS,1000,101,102)
















 3880
3880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









