







关于不平衡数据的处理,相关文献数不胜数,几乎大同小异,其中本人比较推荐 @机器之心 与 @刘芷宁的两篇文章。
机器之心:机器学习中如何处理不平衡数据?zhuanlan.zhihu.com
在此基础上,本文试图回答以下三个工作中遇到的问题,以供参考。
1. 重采样与代价敏感学习作用在数据集上的表现如何
2. 先划分训练-测试集还是先进行重采样
3. 面对不平衡数据,如何显著提升模型的表现
一、重采样与代价敏感学习
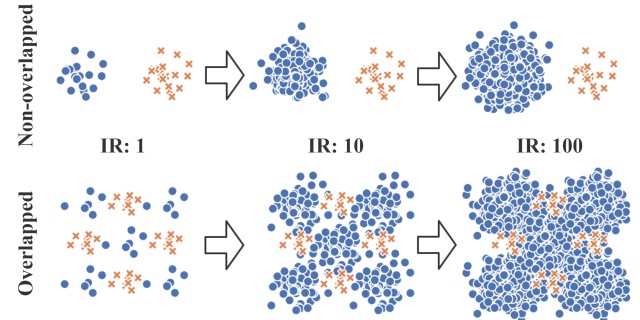
重采样,顾名思义即重新进行采样,它通过减少多数类样本或者增加少数类样本的方式,来直接改变原始数据的分布,强制数据从不平衡转为平衡。其中,SMOTE算法合成数据也是一种特殊的过采样方法;代价敏感学习的核心思想是基于成本的分类,它赋予少数类更高的权重,使得分错少数类的代价更高,从而在追求整体代价最小的目标下,学习器就必定偏向于尽可能将少数类划分正确。
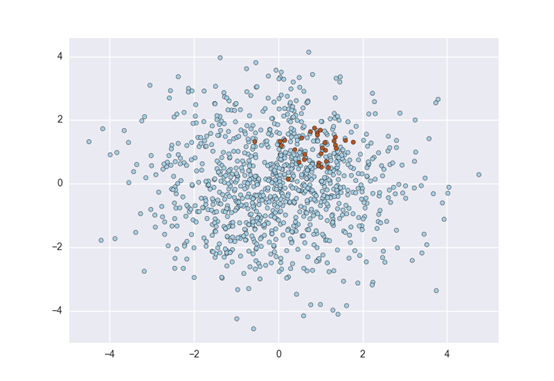
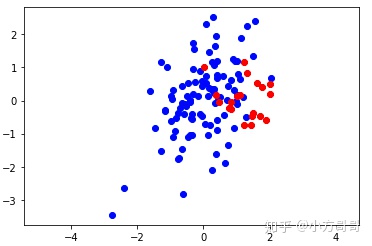
本文基于仿真数据,对重采样与代价敏感学习两类方法进行可视化实验分析。为此我们考虑一个两变量二分类问题,假设我们有两个类:C0 与C1,其中 C0 的点遵循均值为[1.4, 0]、协方差矩阵为[[0.3, 0], [0, 0.3]]的二维高斯分布;C1 的点遵循均值为[0, 0]、协方差矩阵为[[0.5, 0], [0.5, 1]]的二维高斯分布。并假设数据集中1/6的点来自C0,其余5/6来自C1。下图是包含120个点的数据集按照上述假设的理论分布情况:
import numpy as np
np.random.seed(2)
mean = [0, 0]
cov = [[0.5, 0], [0.5, 1]]
mean2 = [1.4, 0]
cov2 = [[0.3, 0], [0, 0.3]]
import matplotlib.pyplot as plt
x, y = n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









