







数据结构
本文参考邓俊辉老师的教材《数据结构(C++语言版)》及mooc课程,总结1-6章
邓老师上课的所有资源均已公开:https://dsa.cs.tsinghua.edu.cn/~deng/ds/dsacpp/index.htm
第一章 绪论
复杂度度量
-
时间复杂度:T(n);
-
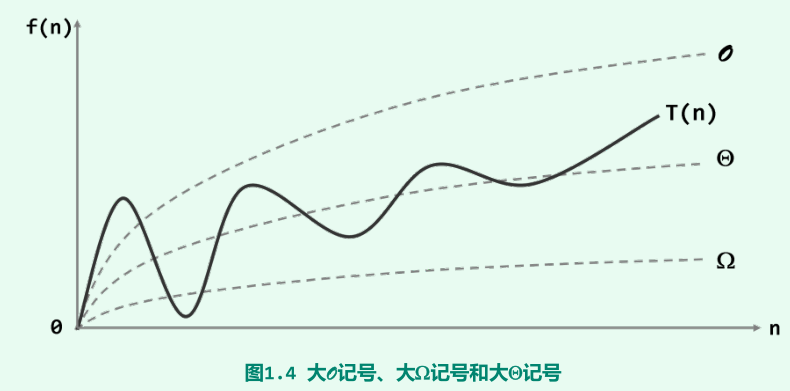
渐进复杂度:
-
O(f(n)):f(n)给出了T(n)增长速度的渐进上界;
-
Ω(g(n)):g(n)给出了T(n)增长速度的渐进下界;
-
Θ(h(n)):对算法复杂度的准确估计。
-
-
空间复杂度:不会多于基本操作次数,时间复杂度是空间复杂度的天然上界。
复杂度分析
-
典型复杂度(由小到大):O(1); O(logn); O(√n); O(n); O(nlogn); O(n^2); O(n^3); O(2^n);

递归
-
线性递归(运行时间及空间均为O(n))

-
二分递归(运行时间为O(n); 运行空间为O(logn))

抽象数据类型
- 抽象数据类型(abstract data type, ADT)
第二章 向量
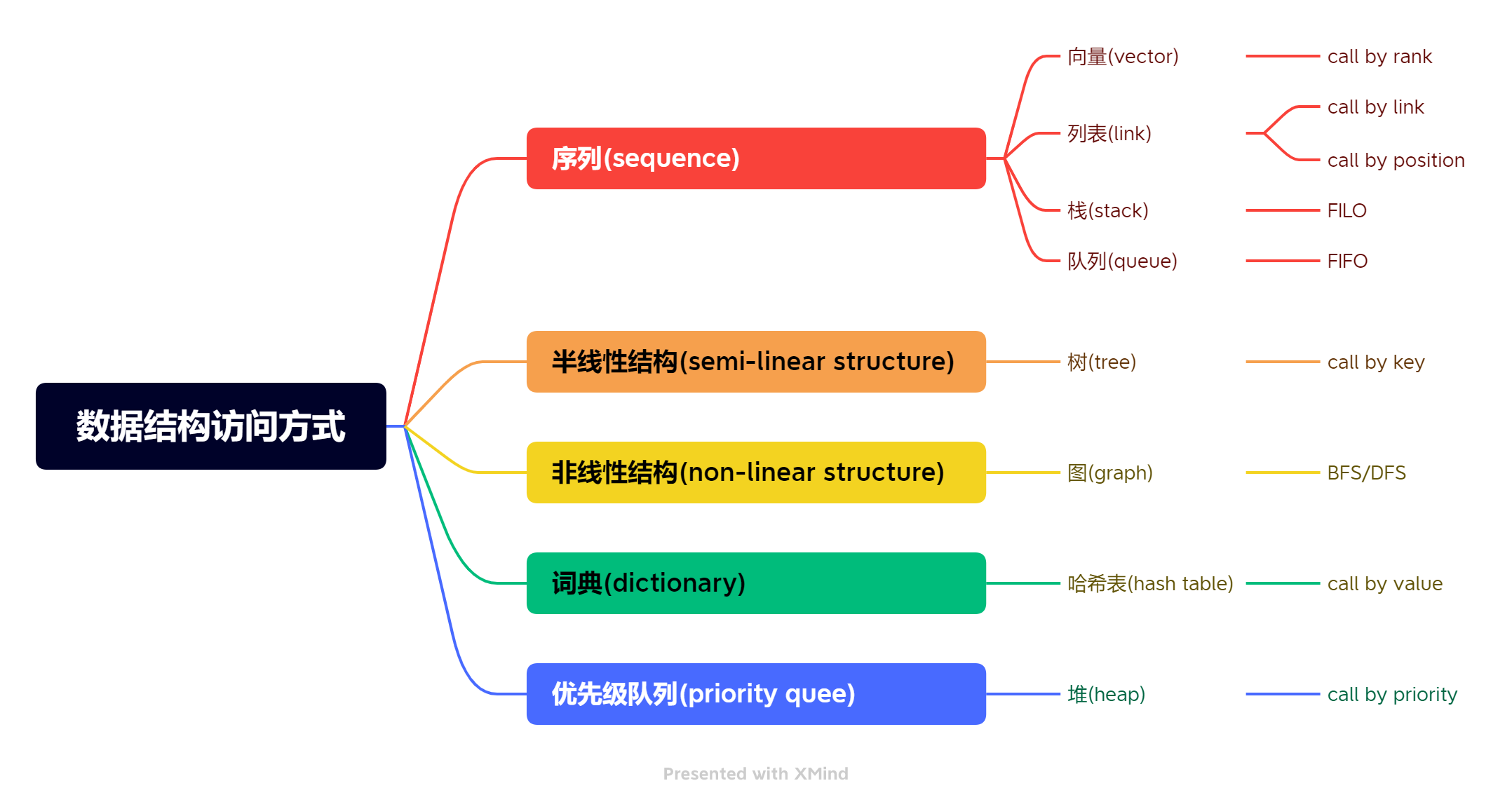
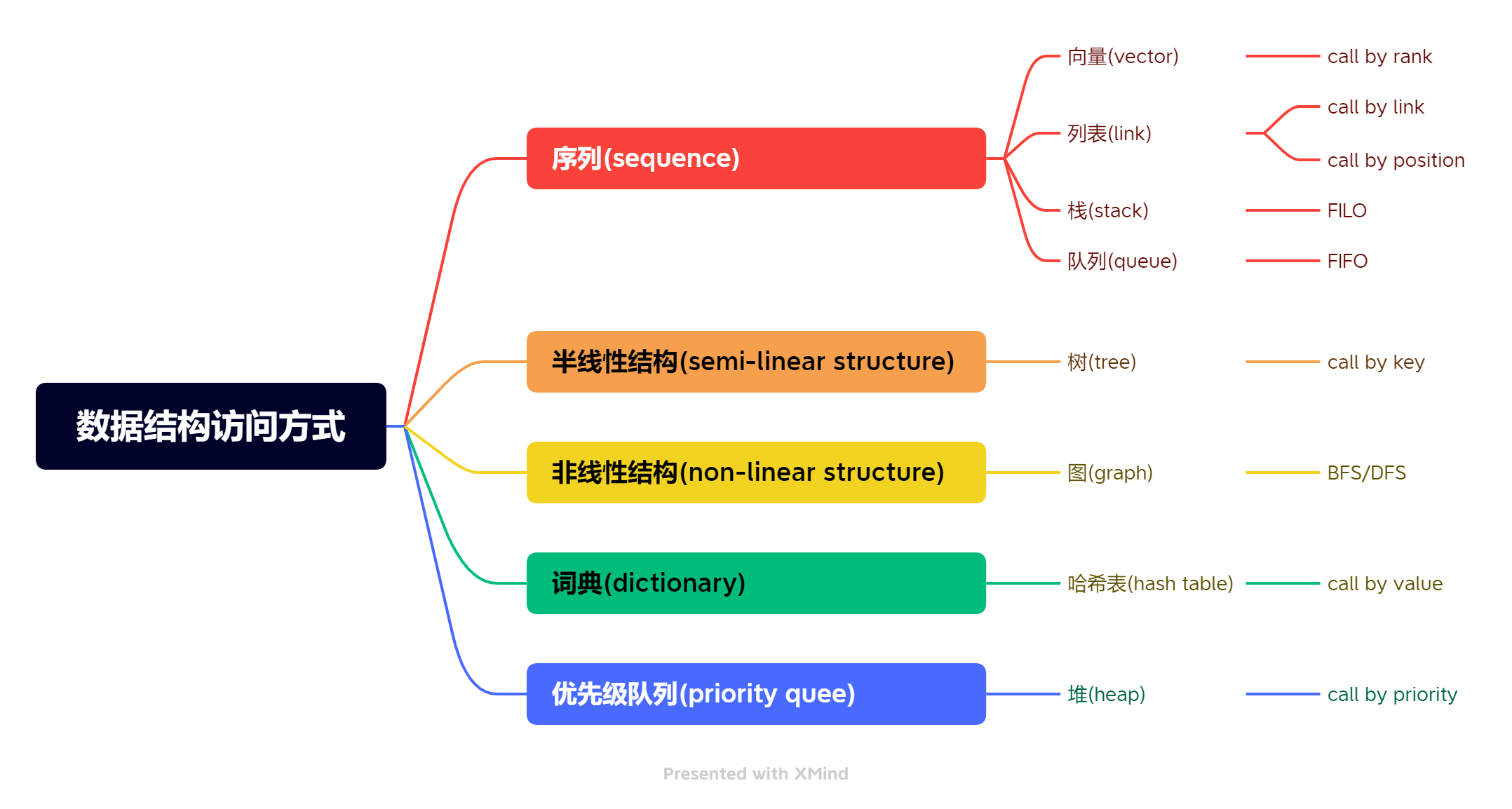
数据结构访问方式总结
从数组到向量
- 向量(vector)就是线性数组的一种抽象与泛化,它也是由具有线性次序的一组元素构成的集合V = { v_0 , v1 , …, vn-1 },其中的元素分别由秩(r)相互区分;
- 向量中,各数据项的物理存放位置与逻辑次序完全对应,故可通过秩直接访问对应的元素,即“循秩访问”(call-by-rank)。
vector模板类实现与C++标准库
-
《数据结构》利用数组对vector进行了底层实现:
- 向量中秩为r的元素 , 对应于内部数组中的elem[r] , 其物理地址为elem + r;
- 模板类如下:



-
vector为C++模板类中的顺序容器
初始化 含义 vector v1 初始化为空 vector v2 = v1 根据v1进行赋值初始化 vector v2(v1) 根据v1进行直接初始化 vector v3(n, val) 构造初始化,v3中有n个val vector v3(n) 构造初始化,v3中有n个T类型的默认值 vector v3(b, e) 将迭代器b和e指定范围内的元素拷贝到v3 vector v4 = {a, b, c…} 参数列表赋值初始化 vector v4{a, b,c…} 参数列表直接初始化
动态空间管理
-
静态空间管理
-
装填因子:向量实际规模与其内部数组容量的比值(即size/capacity);
-
扩容及缩容算法(注意容量加倍的方法:左移1位,缩容同理,右移1位);

-
常规向量算法
- 直接引用元素:重载操作符“[ ]";
- 顺序查找
find(e, lo, hi):O(n); - 插入
insert(r, e):O(n); - 删除:
- 区间删除
remove(lo, hi):最好为O(1),最坏为O(n); - 单元素删除
remove(r);
- 区间删除
- 唯一化
deduplicate():针对无序向量,O(n^2); - 遍历
traverse():O(n);
有序向量
-
唯一化
uniquify():针对有序向量,采用双指针,O(n);

-
二分查找(减而治之,A版本)
-
复杂度O(logn)(对比顺序查找为O(n));

-
查找长度不均衡,导致平均查找长度为O(1.5∙logn);

-
-
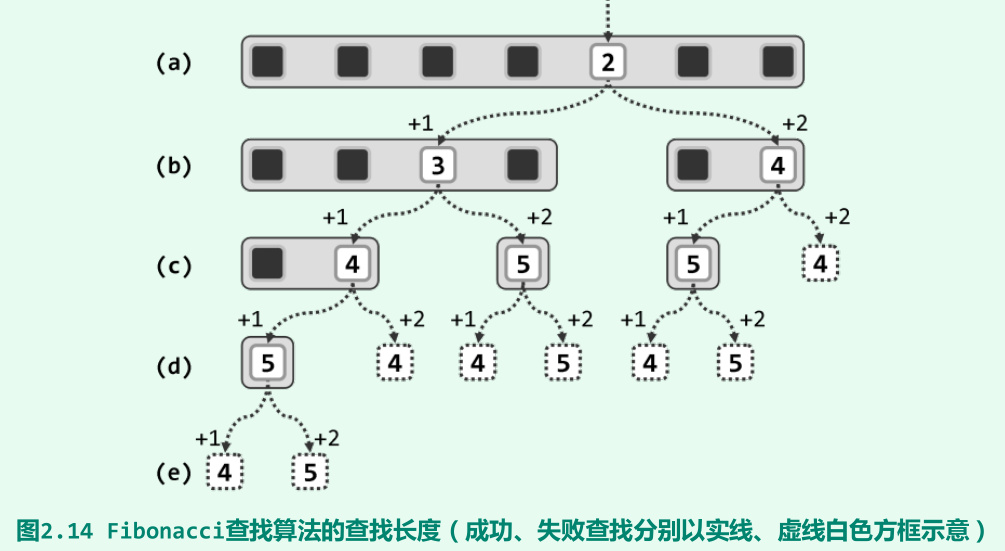
Fibonacci查找(在二分查找基础上,按黄金分割比来确定mi)
-
平均查找长度为O(1.44∙logn);
-
排序器
-
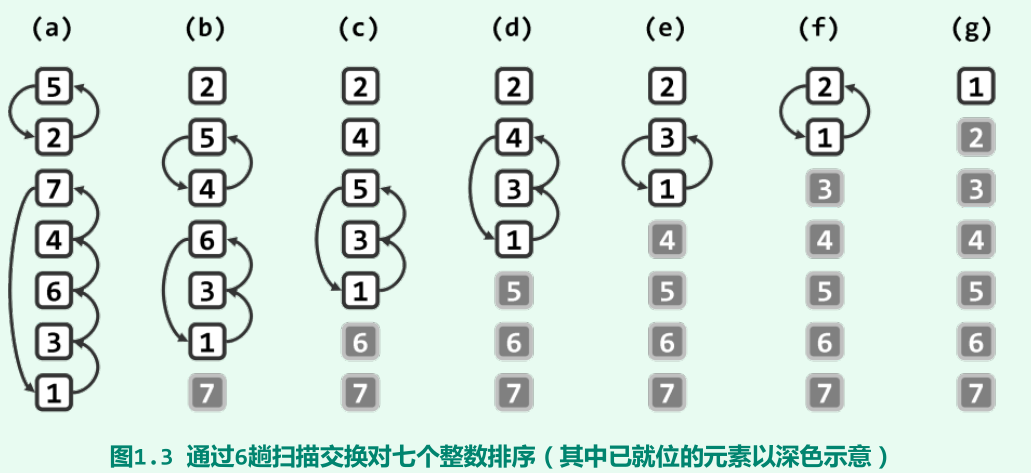
起泡排序(O(n))
-
原理
-
实现


-
-
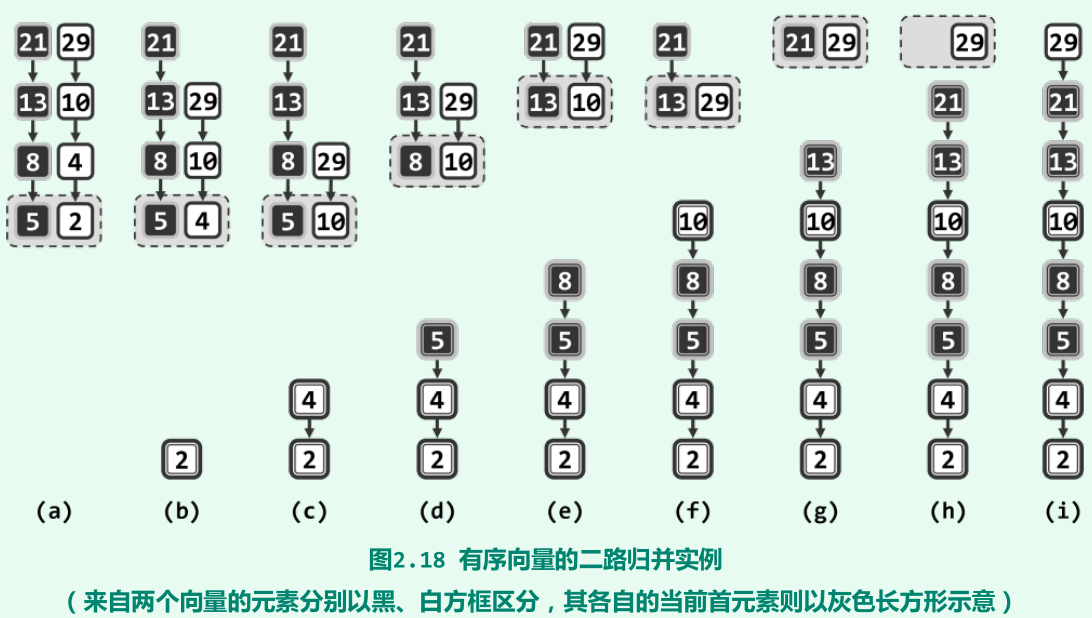
归并排序(分而治之,O(n))
-
思路
-
实现(迭代)


-
第三章 列表
数据结构访问方式总结
从向量到列表
-
列表是由有线性逻辑次序的一组元素构成的集合:L = { a_0 , a_1 , …, a_n-1 }
-
列表(list)结构尽管也要求各元素在逻辑上具有线性次序,但对其物理地址却未作任何限制,即“动态存储”策略;
-
逻辑上互为前驱和后继的元素之间,维护某种索引关系,可抽象地理解为被索引元素的位置(position),故列表元素是“循位置访问”(call-by-position)的;也可称作“循链接访问”(call-by-link)。
接口
-
列表节点(listnode模板类)

-
列表(list模板类)



列表
-
结构
-
头节点(header)和尾节点(trailer)始终存在,但对外并不可见(做为哨兵节点);
-
第一个和最后一个节点分别称作首节点(first node)和末节点(last node)。

-
-
默认构造方法;
-
由秩到位置的转换:重载操作符”[ ]“;
-
查找:重载操作接口
find(e)和find(e, p, n),O(n); -
插入:O(1)
- 前插入
insertAsPred(T const& e); - 后插入
insertAsSucc(T const& e); insertAsFirst()和insertAsLast();
- 前插入
-
删除
remove(ListNodePosi(T) p),O(1); -
唯一化
duplicate(),O(n^2);
有序列表
- 唯一化
uniquify(),同向量原理,O(n); - 查找
search(T const& e, int n, ListNodePosi(T) p),O(n);
排序器
-
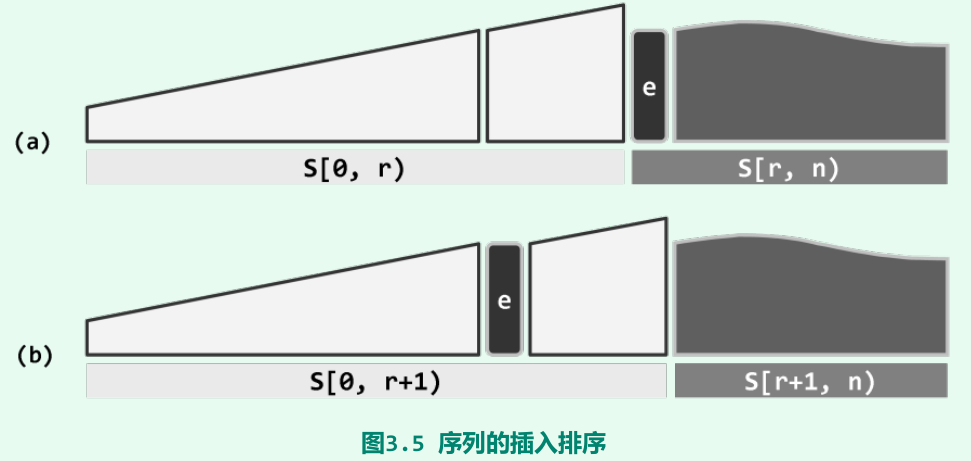
插入排序:O(n^2)
-
原理:将整个序列视作并切分为两部分:有序的前缀,无序的后缀;通过迭代,反复地将后缀的首元素转移至前缀中。
-
实现

-
-
选择排序:O(nlogn)
-
原理:将序列划分为无序前缀和有序后缀两部分;此外,还要求前缀不
大于后后缀;每次需从前缀中选出最大者,并作为最小元素移至后中。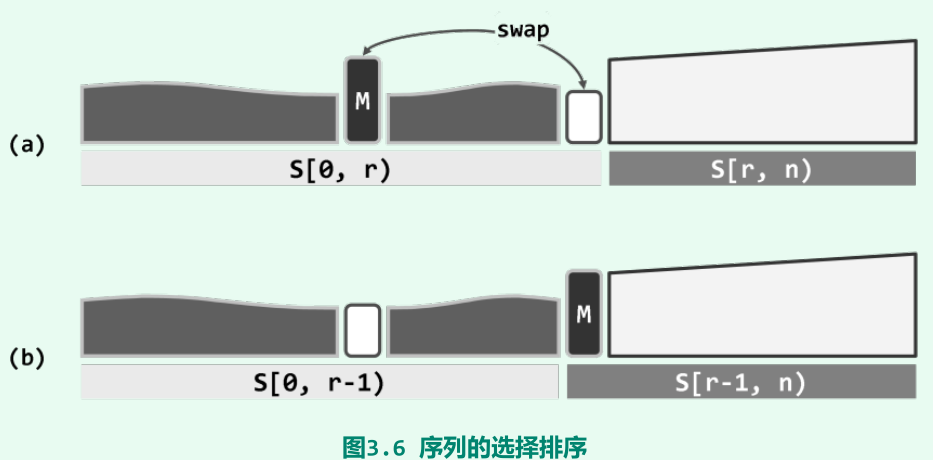
-
实现


-
-
归并排序:O(n + m),线性正比于两个子列表的长度之和。
-
实现


-
第四章 栈和队列
- 栈与队列的外部接口更为简化和紧凑,故可视作向量与列表的特例。
栈及典型应用
-
将栈作为向量的派生类,利用C++的继承机制实现stack模板类。

-
栈的应用——逆序输出
-
进制转换(短除法的体现)


-
-
栈的应用——递归嵌套
-
栈混洗
-
括号匹配

-
-
栈的应用——延迟缓冲
-
表达式求值(基于中缀表达式,结合优先级表,数栈+符栈)

-
算法自左向右扫描表达式,并对其中字符逐一做相应的处理。那些已经扫描过但尚不能处理的操作数与运算符,将分别缓冲至栈opnd和栈optr。一旦判定已缓存的子表达式优先级足够高,便弹出相关的操作数和运算符,随即执行运算,并将结果压入栈opnd。
-
逆波兰表达式(RPN,也称后缀表达式):操作符紧邻于对应的(最后一个)操作数之后。
例如:RPN表达式
1 2 + 3 4 ^ *即对应于( 1 + 2 ) * 3 ^ 4。
-
-
试探与回溯
-
八皇后
-
问题

-
求解:基于试探回溯策略,首先将各皇后分配至每一行。然后,从空棋盘开始,逐个尝试着将她们放置到无冲突的某列。每放置好一个皇后,才继续试探下一个。若当前皇后在任何列都会造成冲突,则后续皇后的试探都必将是徒劳的,故此时应该回溯到上一皇后。
-
实例
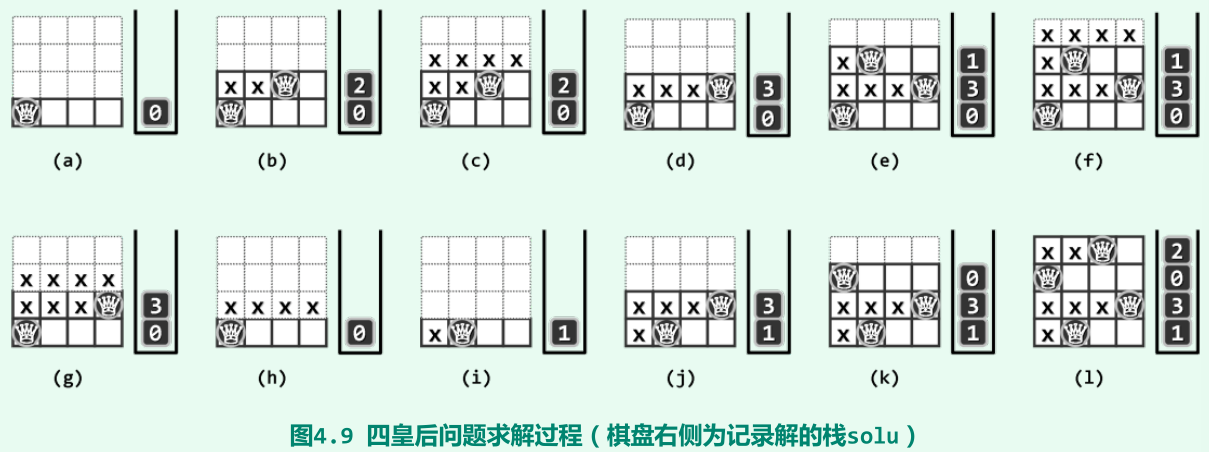
-
-
迷宫寻径
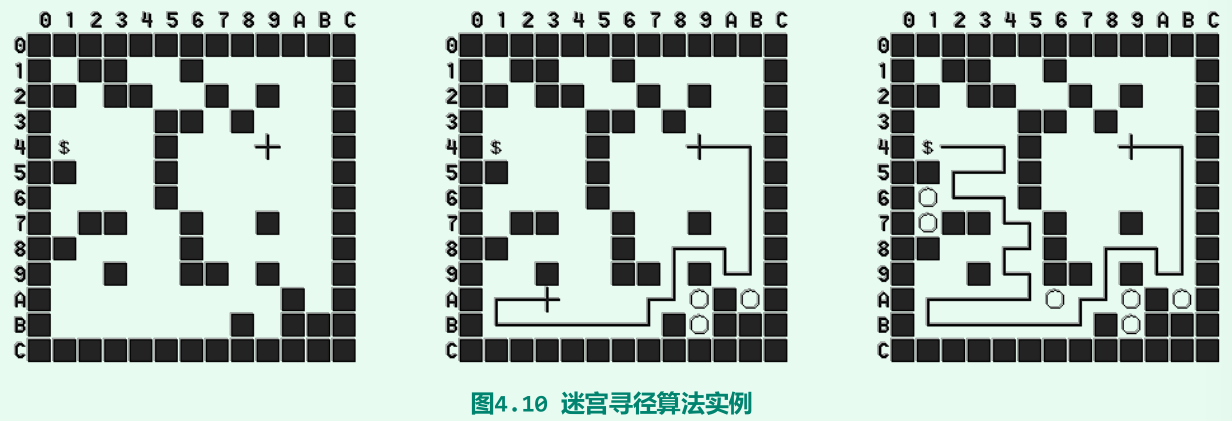
队列及典型应用
-
将队列作为列表的派生类,利用C++的继承机制实现queue模板类。

-
队列应用:循环分配器、银行服务模拟。
第五章 二叉树
-
树中的元素之间并不存在天然的直接后继或直接前驱关系,属于半线性结构。
-
树是一种分层结构,层次化这一特征几乎蕴含于所有事物及其联系当中,成为其本质属性之一。
二叉树及其表示
-
树
- 顶点(vertex),边(edge),根(root);
- v的深度(depth):沿节点v到根r的唯一通路所经过边的数目;
- 祖先(ancestor),后代(descendant),父亲(parent),孩子(child);
- v的度数或度(degree),叶节点(leaf);
- v的子树(subtree);
- 高度(height):所有节点深度的最大值。
-
二叉树**(binary tree)**
- 每个节点的度数均不超过2;
- 真二叉树(proper binary tree):不含一度节点的二叉树。
-
多叉树及表示
-
可将各节点组织为向量或列表,其中每个元素除保存节点本身的信息(node)外,还需要保存父节点/孩子节点(或二者都有)的秩或位置。
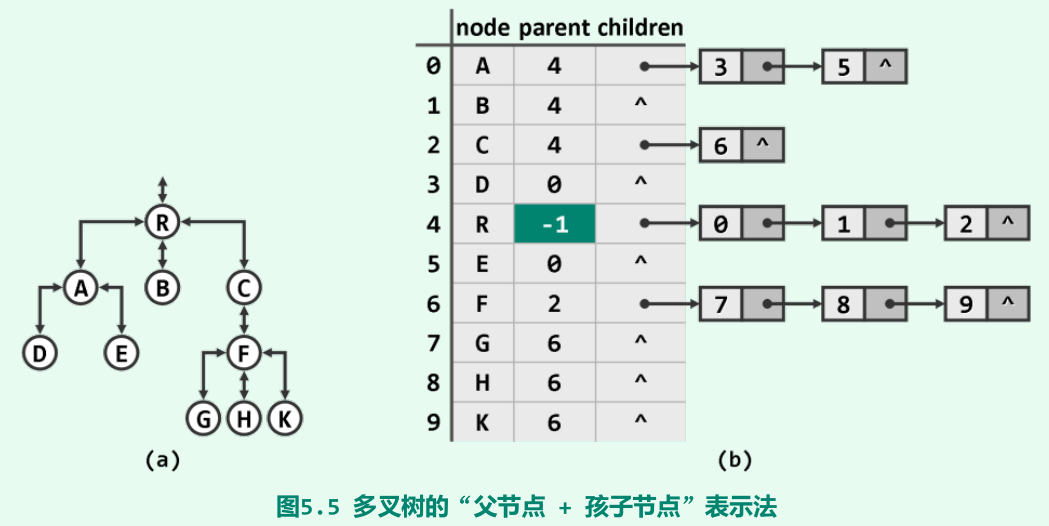
-
编码树
-
二进制编码
-
解码歧义

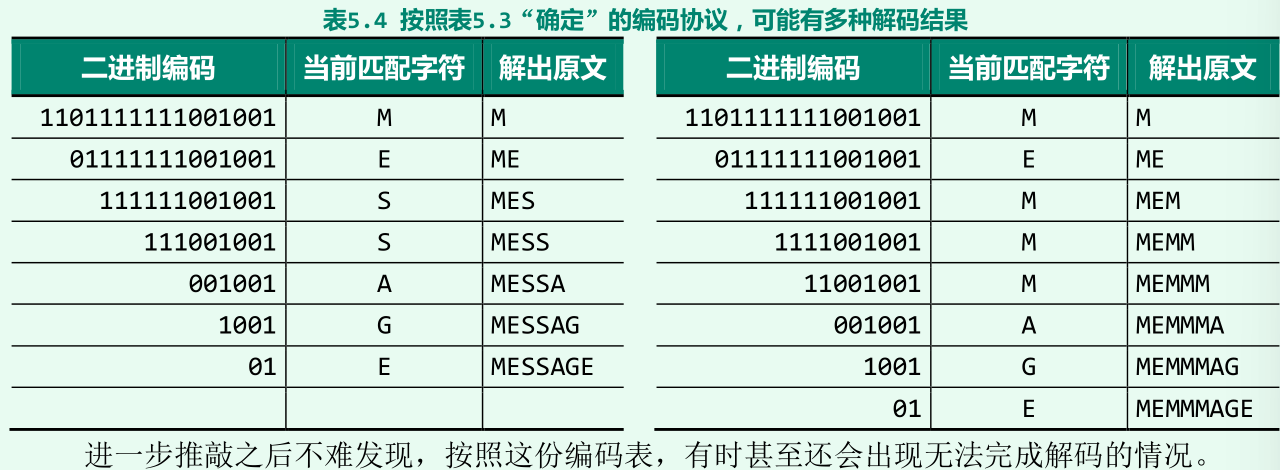
-
前缀无歧义编码:任何两个原始字符所对应的二进制编码串,相互都不得是前缀。
-
-
二叉编码树
-
从根节点出发,每次向左(右)都对应于一个0(1)比特位。
-
PFC编码树
- 图(b)为上表5-3对应的编码树:导致解码歧义的根源在于,在 其 编码树中字符’M’是’S’的父亲;
- 图(a)所有字符都对应于叶节点,歧义现象消除。

-
基于PFC 编码树的解码:从前向后扫描该串,同时在树中相应移动。起始时从树根出发,视各比特位的取值相应地向左或右深入下一层,直到抵达叶节点。然后重回树根。
-
二叉树的实现
-
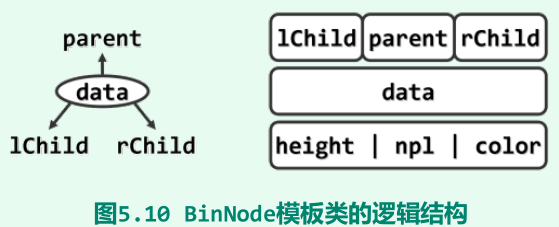
二叉树节点(BinNode模板类)
-
类比list,先定义ListNode模板类,再定义List。

-
成员变量:data的类型由模板变量T指定,用于存放数值对象。lChild、rChild和parent均为指针类型,分别指向左、右孩子以及父节点的位置。
-
快捷方式


-
二叉树节点操作接口——插入孩子节点

-
-
二叉树(BinTree模板类)


- 注意:BinNode和BinTree中两个同名的insertAsLC(),它们各自所属的对象类型不同。
遍历
-
遍历:按照事先约定的某种规则或次序,对节点各访问一次而且仅一次,等效于将半线性的树形结构转换为线性结构。
-
递归式遍历:O(n)
-
根据节点V在其中的访问次序,有VLR、LVR和LRV。
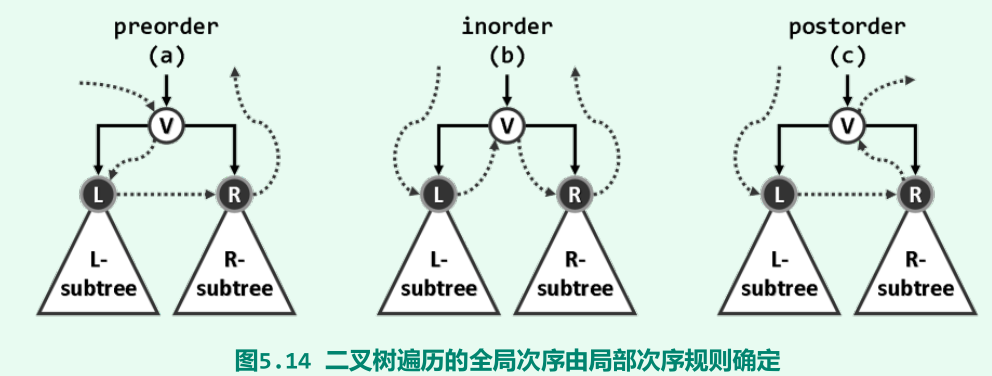
-
先序遍历(VLR)

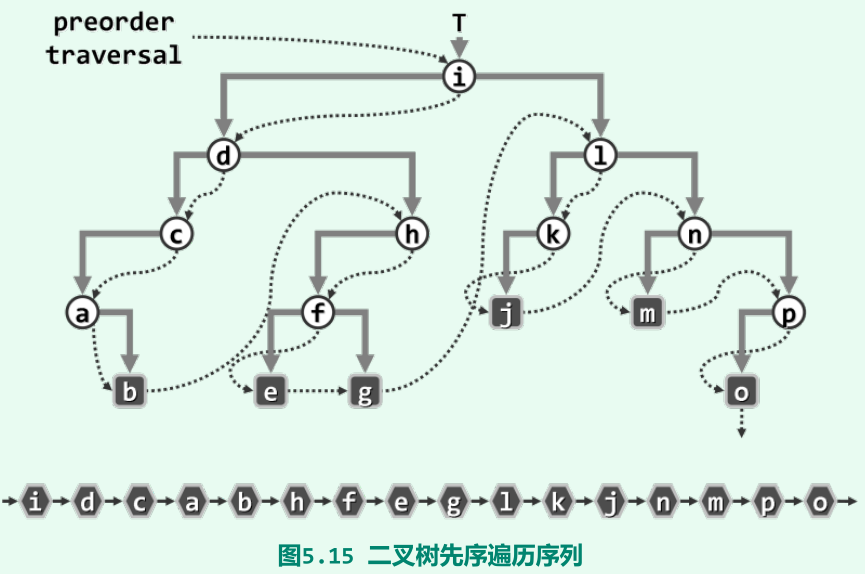
-
后序遍历(LRV)

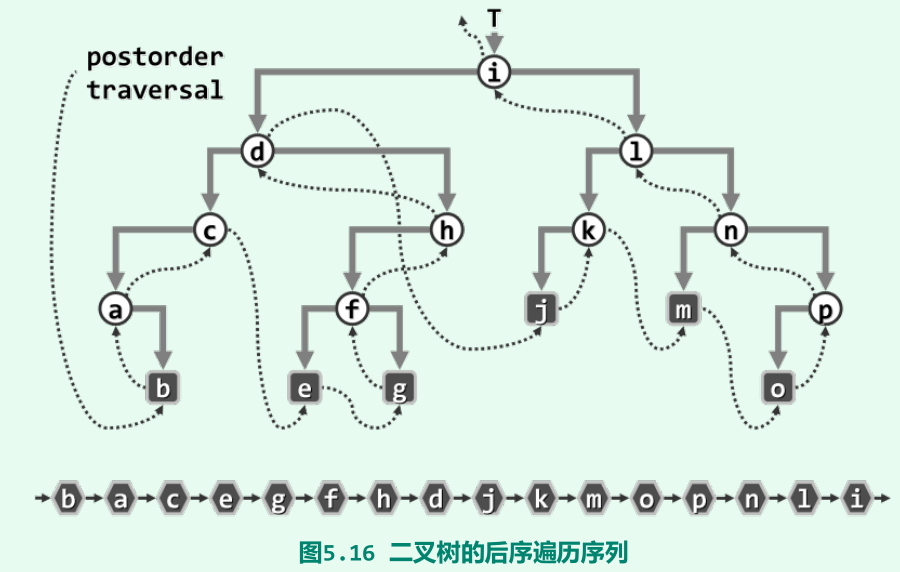
-
中序遍历(LVR)

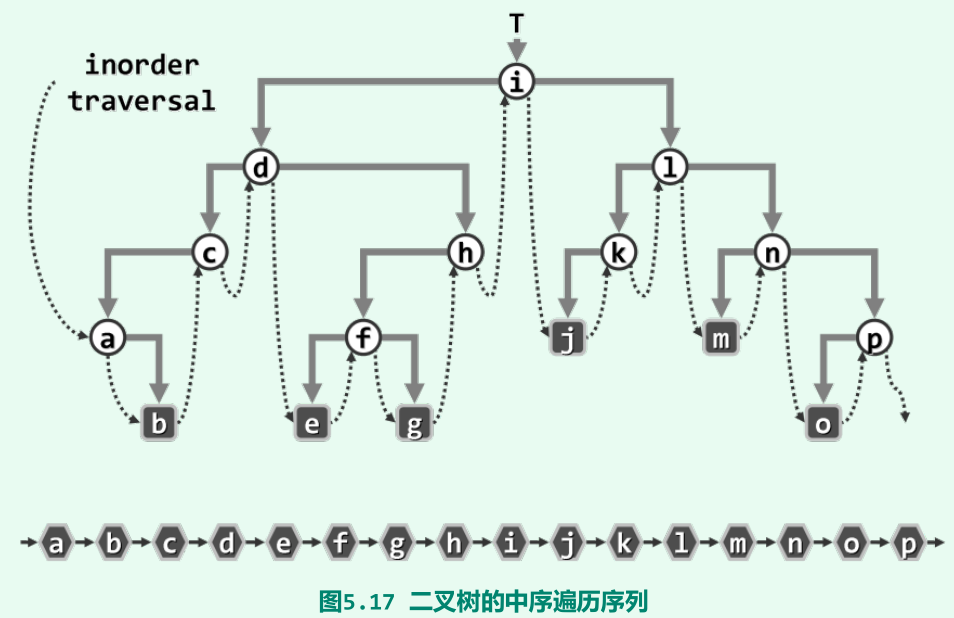
-
-
迭代版先序遍历
-
沿最左侧通路自顶而下访问各节点(将对应右孩子存入辅助栈),再自底而上遍历的对应右子树。
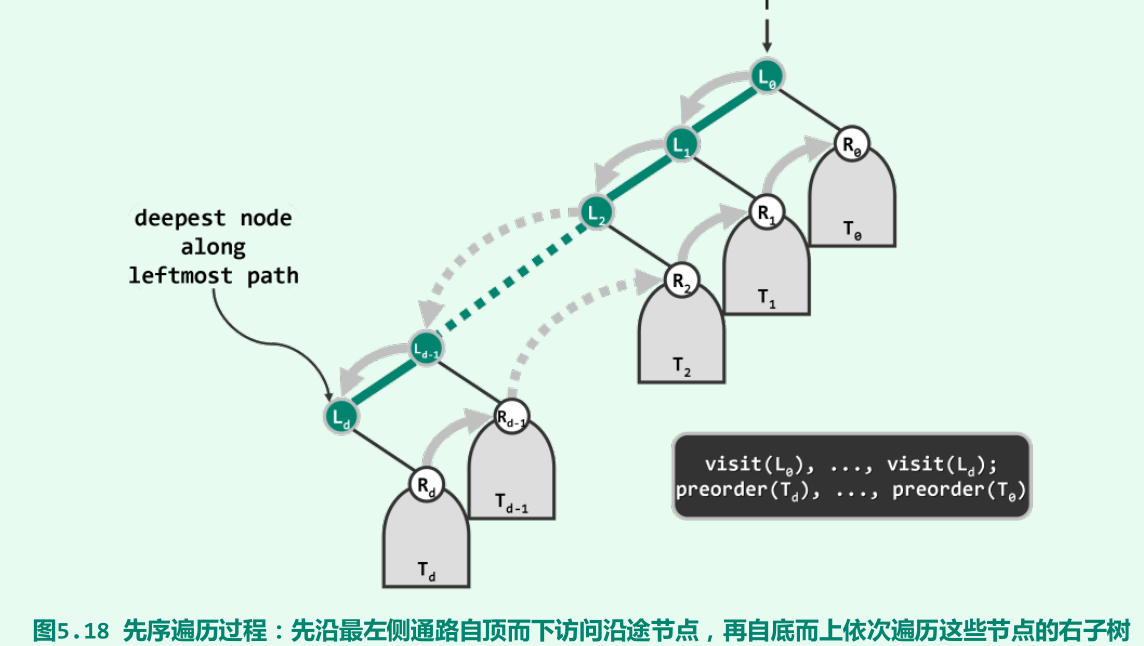


-
-
迭代版中序遍历
-
沿最左侧通路先到最底(将沿途经过的节点存入辅助栈),然后自底而上,以沿途各节点为界分解为d + 1段。各段均包括访问来自最左侧通路的某一节点L_k ,遍历其右子树T_k,最后访问L_k-1。
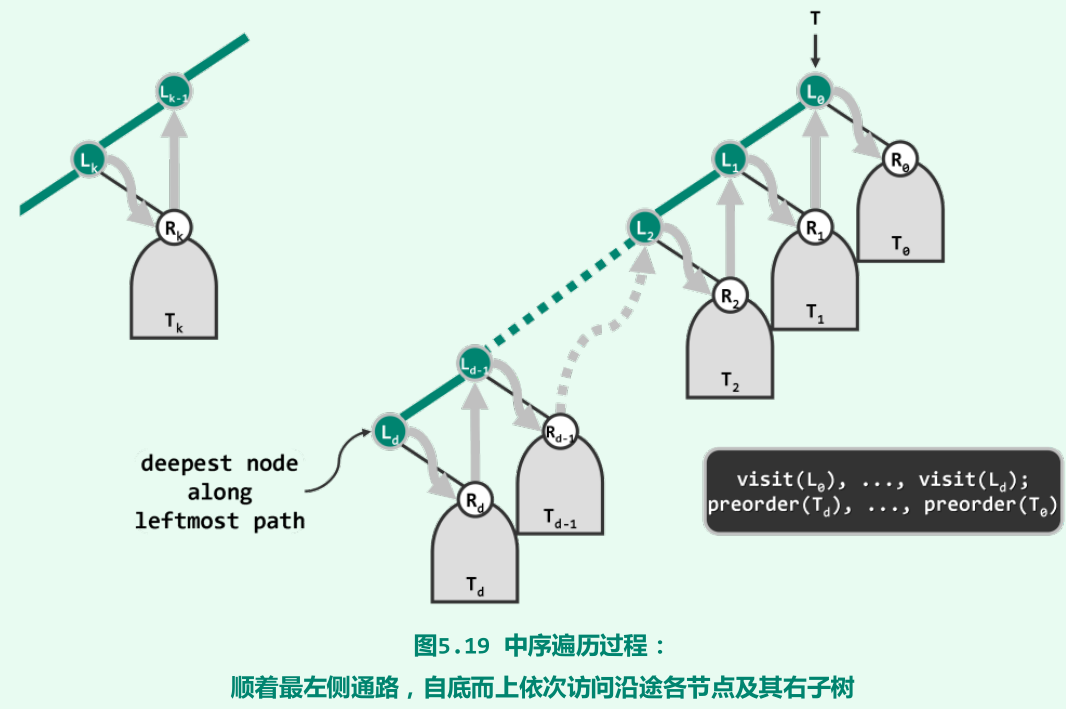

-
-
迭代版后序遍历
-
沿最左侧通路先到最底(将沿途经过的节点存入辅助栈),自底而上地沿着该通路,分解为若干个片段。每一片段起始于通路上的一个节点,并包括三步:访问当前节点,遍历以其右兄弟(若存在)为根的子树,以及向上回溯至其父节点(若存在)并转入下一片段。
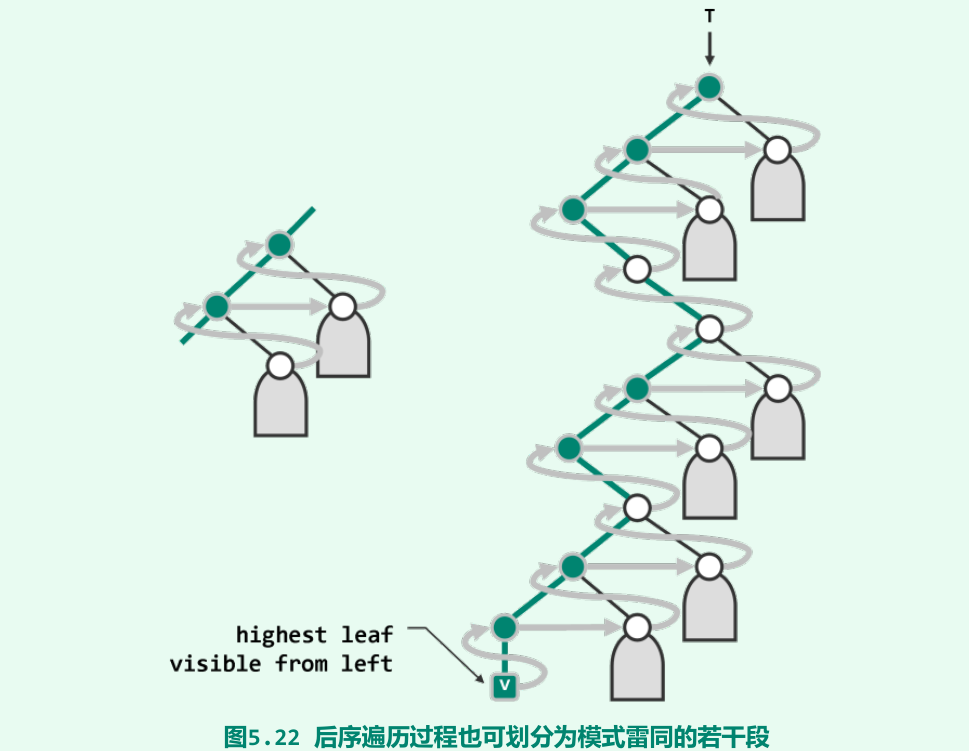


-
-
层次遍历
-
先上后下、先左后右;
-
迭代式层次遍历需要使用与栈对称的队列结构;

-
-
完全二叉树
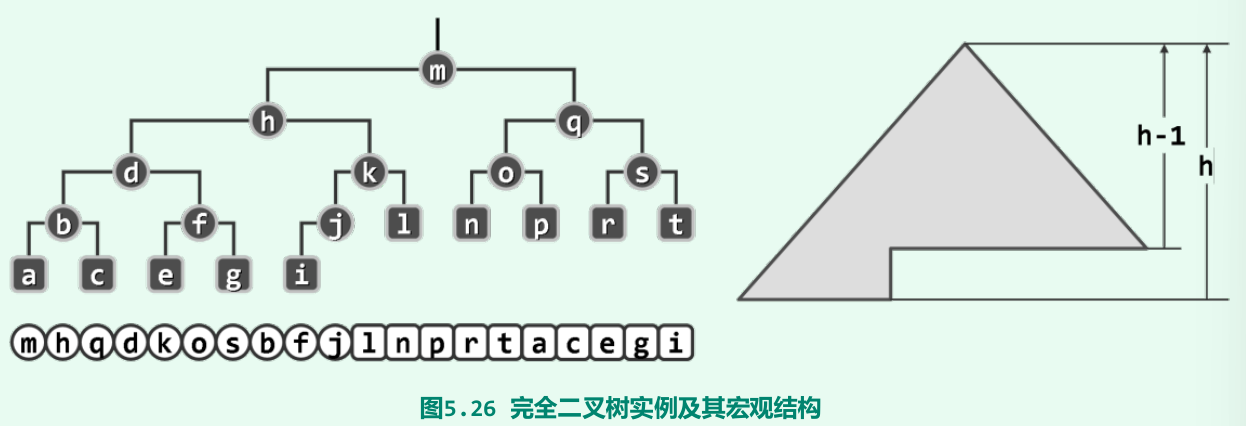
- 叶节点只能出现在最底部的两层,且最底层叶节点均处于次底层叶节点的左侧;
- 高度为h的完全二叉树,规模应该介于2^h 至2^(h+1) - 1之间;
- 规模为n的完全二叉树,高度h = O(logn)。
-
满二叉树
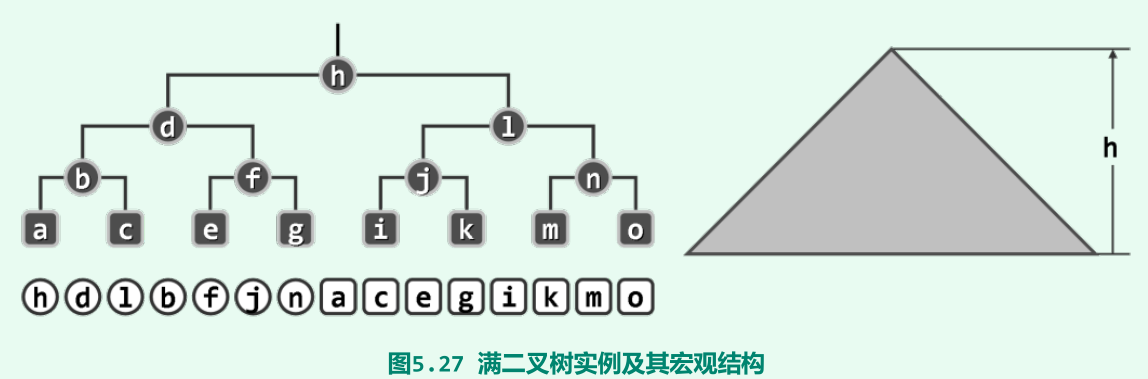
- 每一层的节点数都应达到饱和;
- 高度为h的满二叉树由2^(h+1) - 1个节点组成,叶节点总是恰好比内部
节点多出一个。
第六章 图
- 从数据结构的角度分类,图属于非线性结构(non-linear structure);
- 通过遍历将其转化为半线性结构,进而借助树结构已有的处理方法和技巧,最终解决问题。
概述
- 无向图、有向图及混合图;
- 度、入边、出边、入度及出度;
- 通路与环路:简单通路、有向无环、欧拉环路、哈密尔顿环路;
- 带权网络。
图的表示
-
Graph模板类


邻接矩阵
- 基于向量实现;
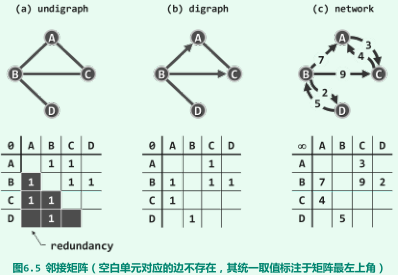
-
继承图模板类,加入顶点对象和边对象;

-
顶点基本操作:查询某个顶点的相关信息、插入删除等;
-
边的基本操作:确认是否存在、插入删除等。
-
复杂度
- 时间性能:所有静态操作(查找)为O(1)、边的动态操作为O(1)、顶点的动态操作为O(n);
- 空间性能:主要消耗于邻接矩阵,即其中的二维边集向量
E[][],因此,复杂度渐进地不超过O(n^2 )。
邻接表
-
基于列表实现
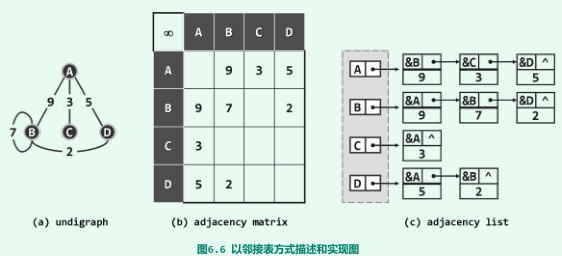
-
复杂度
- 空间总量为O(n + e);
- 空间性能的改进以某些方面时间性能的降低为代价:顺序查找需O(n)、顶点删除需O(e)等。
图遍历算法
- 图的遍历可理解为,将非线性结构转化为半线性结构的过程;
- 经遍历而确定的边类型中,最重要的即树边,它们与所有顶点共同构成了原图的一棵支撑树(森林),称作遍历树(traversal tree)。
广度优先搜索(BFS)
-
策略:越早被访问到的顶点,其邻居越优先被选用;
-
注意:区分被发现与被访问;
-
重点:借助队列Q,来保存已被发现但尚未访问完毕的顶点;
-
实现

-
实例
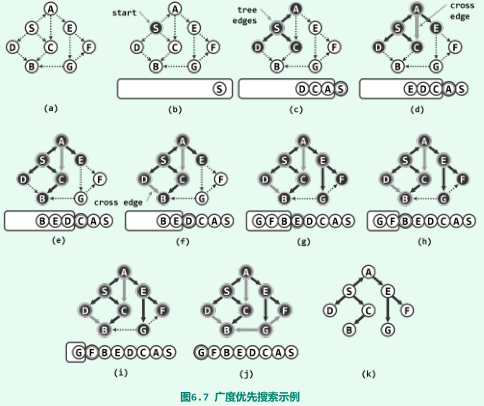
-
空间及时间复杂度均为O(n+e)。
深度优先搜索(DFS)
-
策略:优先选取 最后一个被访问到的顶点的邻居;
- 各顶点被发现的次序,类似于树的先序遍历;
- 各顶点被访问完毕的次序,则类似于树的后序遍历。
-
实现

-
实例
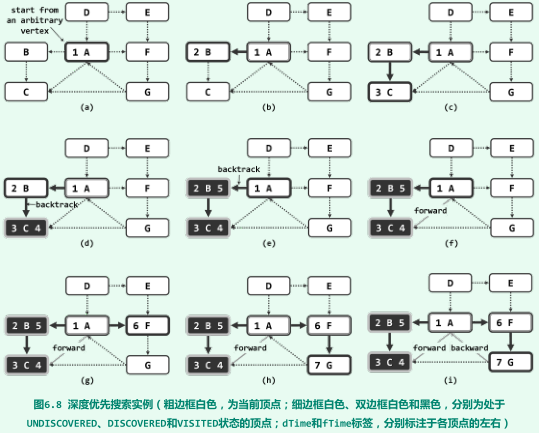

-
复杂度
- 空间及时间复杂度均为O(n+e)。
最小支撑树
-
支撑树(spanning tree)
- 连通图G的某一无环连通子图T若覆盖G中所有的顶点,则称作G的一棵支撑树或生成树(spanning tree);
- “禁止环路”前提下的极大子图,“保持连通”前提下的最小子图。
-
最小支撑树(minimum spanning tree, MST)
-
图G为带权网络,每一棵支撑树的成本(cost)为其所采用各边权重的总和。在G的所有支撑树中,成本最低者为最小支撑树;
-
不唯一性
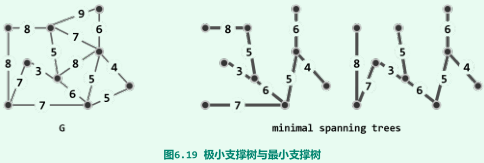
-
-
Prim算法
-
基于贪心策略导出的迭代式算法;
-
任意选择顶点作为初始子树T_1 = ({A}; Φ),每次找到该割中对应最短(权重最小)的跨越边,然后扩展该割(如T_2 = ({A, B}),如此反复,直到所有节点都加入割集。
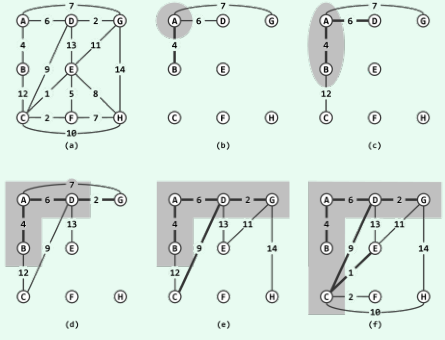
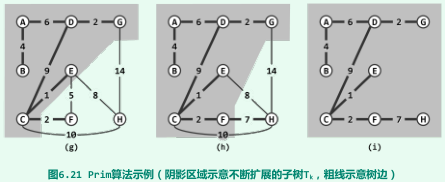
-
最短路径
-
最短路径树:限制权重均为正,且路径无环;
-
Dijkstra算法
-
贪心迭代策略;
-
每次将u加入T并将其拓展,需要且只需要更新那些仍在T 之外,且与T关联的顶点的优先级数;
-
与Prim算法的差异:考虑u到s的距离,而不是其到T的距离。

-
其他应用
- 拓扑排序
- 双连通域分解
- 优先级搜索















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









