







前沿&前言
在人工智能领域,模型的大小往往与性能成正比,而模型的开放程度则决定了其应用范围和影响力。今天,云计算巨头Snowflake携其AI研究团队,发布了一款名为Arctic的的开源企业级大型语言模型,该模型以128位专家和惊人的4800亿参数,成功刷新了全球最大开源模型的纪录,为AI的未来发展描绘出了一幅崭新的蓝图。

Arctic介绍
Arctic的诞生,无疑为人工智能领域注入了新的活力。这款由Snowflake精心打造的大型语言模型,不仅在参数规模上达到了前所未有的高度,更在成本效益、训练效率和推理效率方面展现出显著优势。Arctic采用混合专家(MoE)模型架构,结合了密集变换器(Dense Transformer)和128个专家的MoE模型,每个专家拥有3.66亿参数。这种设计使得Arctic在保持强大性能的同时,能够更高效地利用计算资源,从而实现了在较少训练开销下获得高性能模型的目标。
值得一提的是,Arctic的不仅参数规模庞大,而且在实际运行过程中表现出了高度的稀疏性。在生成过程中,仅有170亿参数处于活跃状态,这极大地提高了模型的推理效率。此外,Arctic的还专注于企业任务,如SQL生成、编程和指令遵循等,这使得它在实际应用中具有更高的实用价值。
传统上,使用LLM构建顶级企业级智能的成本高得令人望而却步,而且资源匮乏,通常需要花费数千万至数亿美元。作为研究人员,我们多年来一直在努力解决有效训练和推理LLM的制约因素。Snowflake AI研究团队的成员开创了ZeRO和DeepSpeed、PagedAttention/vLLM和LLM360等系统的先河,这些系统显著降低了LLM训练和推理的成本,并将其开源,使LLM更易于社区访问,更具成本效益。
今天,Snowflake AI研究团队很高兴地介绍Snowflake-Arctic,这是一家专注于企业的顶级LLM,它推动了成本效益高的培训和开放的前沿。北极是高效的智能和真正的开放。
高效智能:Arctic擅长于SQL生成、编码和指令遵循基准测试等企业任务,即使与使用高得多的计算预算训练的开源模型相比也是如此。事实上,它为成本效益高的培训设定了一个新的基准,使Snowflake客户能够以低成本为其企业需求创建高质量的定制模型。
真正开放:Apache 2.0许可证提供了对权重和代码的无限制访问。此外,我们还开放所有数据配方和研究见解。
Snowflake Arctic今天可从Hugging Face、NVIDIA API目录和Replicate获得,也可通过您的模型花园或选择的目录获得,包括Snowflake-Cortex、Amazon Web Services(AWS)、Microsoft Azure、Lamini、Perplexity和Together。
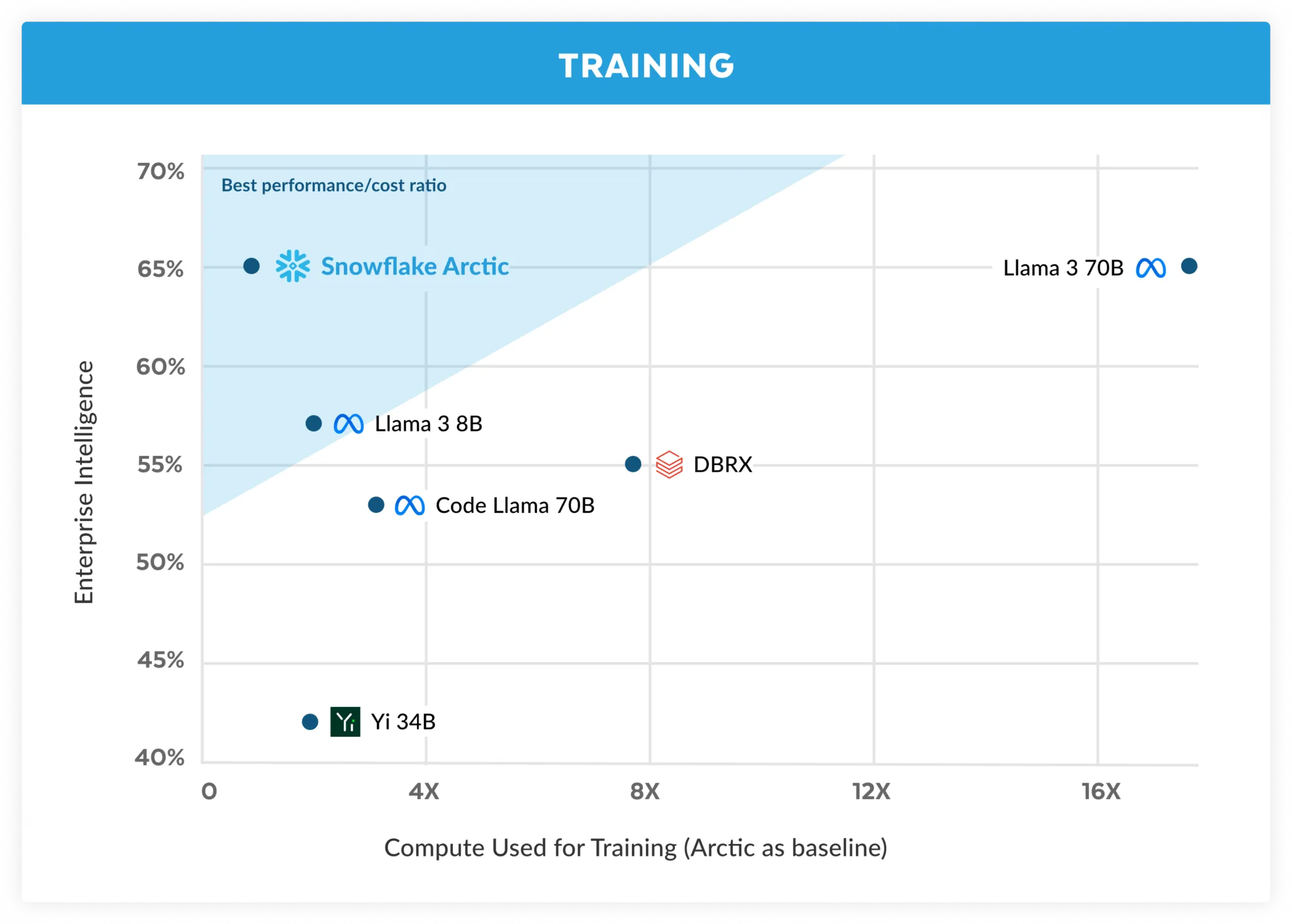
Fig 1. Enterprise intelligence – average of Coding (HumanEval+ and MBPP+), SQL Generation (Spider), and Instruction following (IFEval) – vs. Training cost
以极低的训练成本实现顶级企业智能
在Snowflake,我们从企业客户那里看到了人工智能需求和用例的一致模式。企业希望使用LLM来构建会话式SQL数据副本、代码副本和RAG聊天机器人。从度量的角度来看,这意味着LLM擅长SQL、代码、复杂的指令遵循以及生成有根据的答案的能力。我们通过取编码(HumanEval+和MBPP+)、SQL生成(Spider)和指令跟随(IFEval)的平均值,将这些能力捕获到一个我们称为企业智能的单一指标中。
Arctic在开源LLM中提供顶级企业智能,其训练计算预算约低于200万美元(不到3K GPU周)。这意味着Arctic比其他使用类似计算预算训练的开源模型更有能力。更重要的是,它擅长于企业智能,即使与那些用高得多的计算预算训练的人相比也是如此。Arctic的高训练效率也意味着Snowflake的客户和整个人工智能社区可以以更实惠的方式训练定制模型。
如图1所示,Arctic在企业指标上与LLAMA 3 8B和LLAMA 2 70B不相上下或更好,同时使用的培训计算预算不到一半。同样,尽管使用的计算预算减少了17倍,但Arctic在企业指标方面与Llama3 70B不相上下,如编码(HumanEval+和MBPP+)、SQL(Spider)和指令跟随(IFEval)。它在保持整体性能竞争力的同时做到了这一点。例如,尽管使用的计算量比DBRX少7倍,但它在语言理解和推理(11个指标的集合)方面仍然具有竞争力,同时在数学(GSM8K)方面表现更好。有关按单个基准对结果的详细细分,请参阅度量部分。
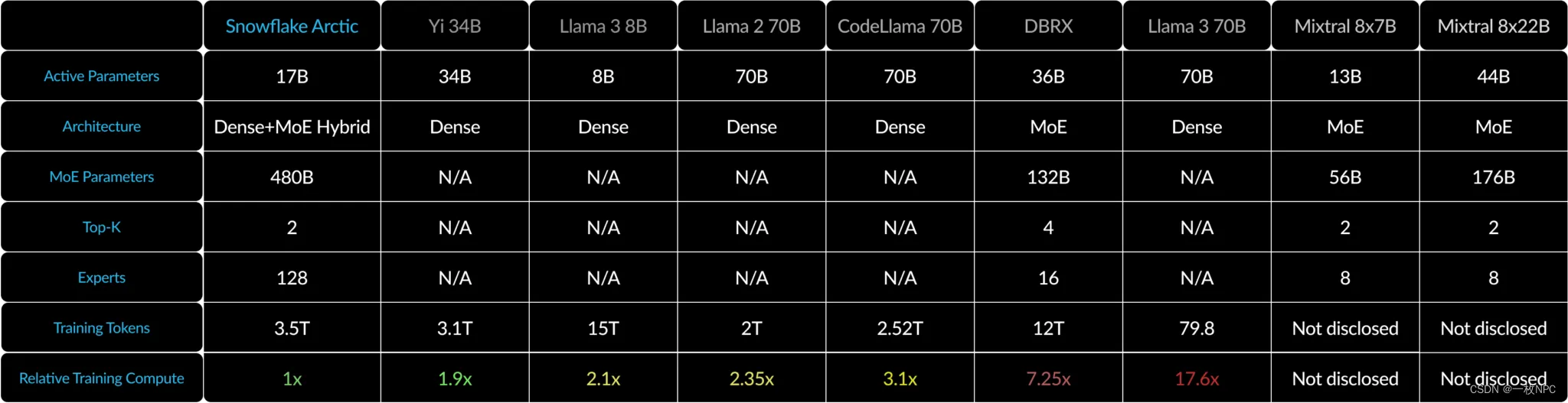
Table 1 Model architecture and training compute for Arctic, Llama-2 70B, DBRX and Mixtral 8x22B. Training compute is proportional to the product of active parameters and training tokens.
Training efficiency
为了实现这一级别的训练效率,Arctic采用了独特的密集MoE混合变压器架构。它将10B密集变压器模型与残余128×3.66B MoE MLP相结合,使用前2个门控选择480B总参数和17B有源参数。它的设计和培训使用了以下三个关键见解和创新:
1) 许多专家都有更多的专家选择:2021年末,DeepSpeed团队证明了MoE可以应用于自回归LLM,在不增加计算成本的情况下显著提高模型质量。
在设计Arctic时,我们注意到,基于上述内容,模型质量的提高主要取决于MoE模型中专家的数量和参数的总数,以及这些专家可以组合在一起的方式的数量。
基于这一见解,Arctic被设计为具有480B的参数,分布在128个细粒度专家中,并使用前2个门控来选择17B的活动参数。相比之下,如表2所示,最近的MoE模型是由更少的专家构建的。直观地说,Arctic利用大量的总参数和许多专家来扩大顶级智能的模型容量,同时它在众多但精简的专家中进行明智的选择,并使用适量的活跃参数进行资源高效的训练和推理。
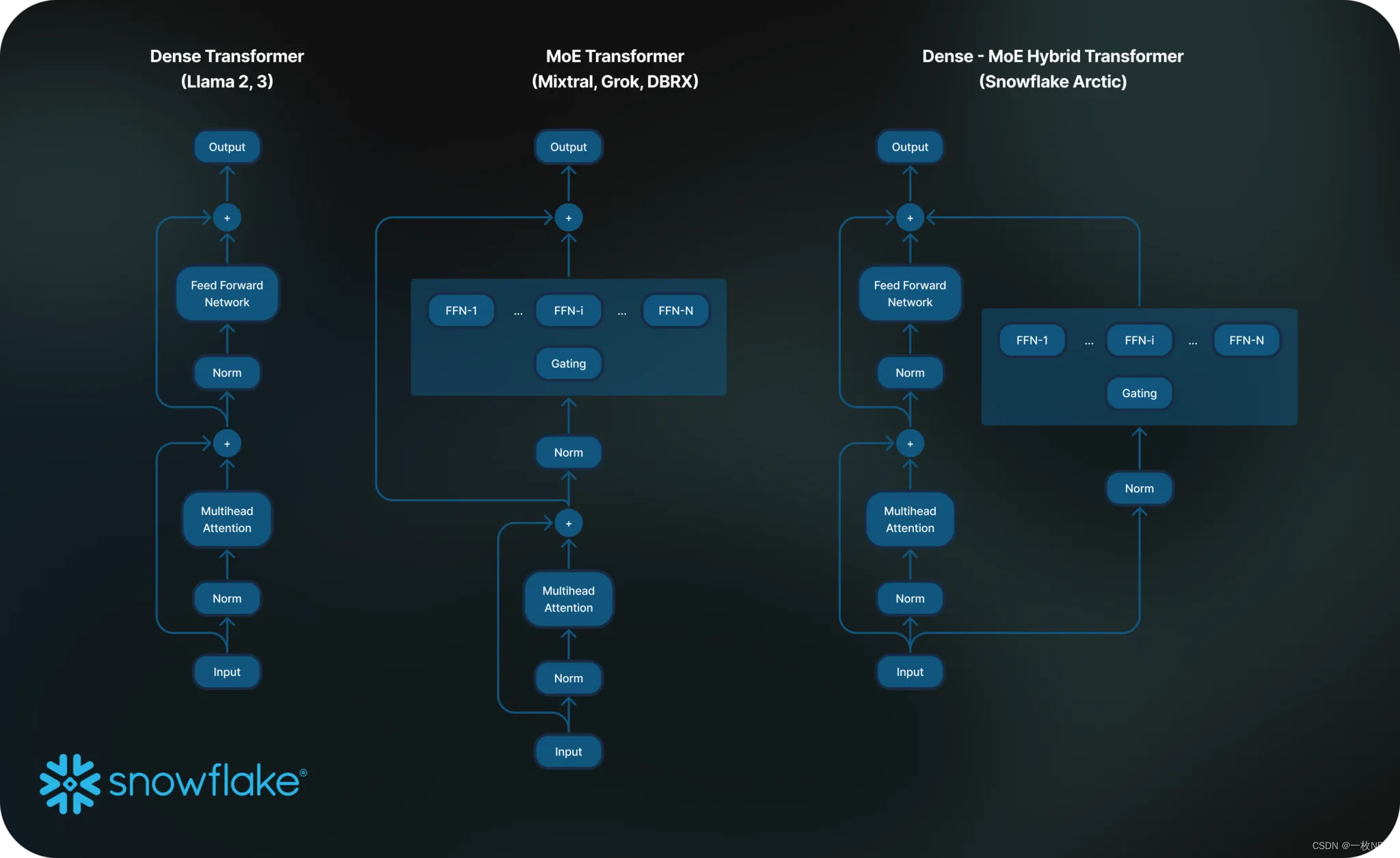
Figure 2. Standard MoE Architecture vs. Arctic
2) 架构和系统协同设计:与大量专家一起训练普通的MoE架构,即使在最强大的人工智能训练硬件上也是非常低效的,因为专家之间的全方位通信开销很高。然而,如果通信可以与计算重叠,则可以隐藏这种开销。
我们的第二个见解是,将北极架构中的密集变压器与残余MoE组件(图2)相结合,使我们的训练系统能够通过通信计算重叠实现良好的训练效率,从而隐藏了很大一部分通信开销。
3) 以企业为中心的数据课程:在代码生成和SQL等企业指标方面表现出色,需要与通用指标的培训模型截然不同的数据课程。在数百次小规模的消融中,我们了解到,常识推理等通用技能可以在一开始就学会,而编码、数学和SQL等更复杂的指标可以在训练的后期有效地学会。人们可以将其比作人类的生活和教育,在那里我们从简单到困难地获得能力。因此,Arctic接受了三阶段课程的培训,每个课程都有不同的数据组成,第一阶段侧重于通用技能(1T代币),后两个阶段侧重于企业技能(1.5T和1T令牌)。这里展示了我们动态课程的高级总结。
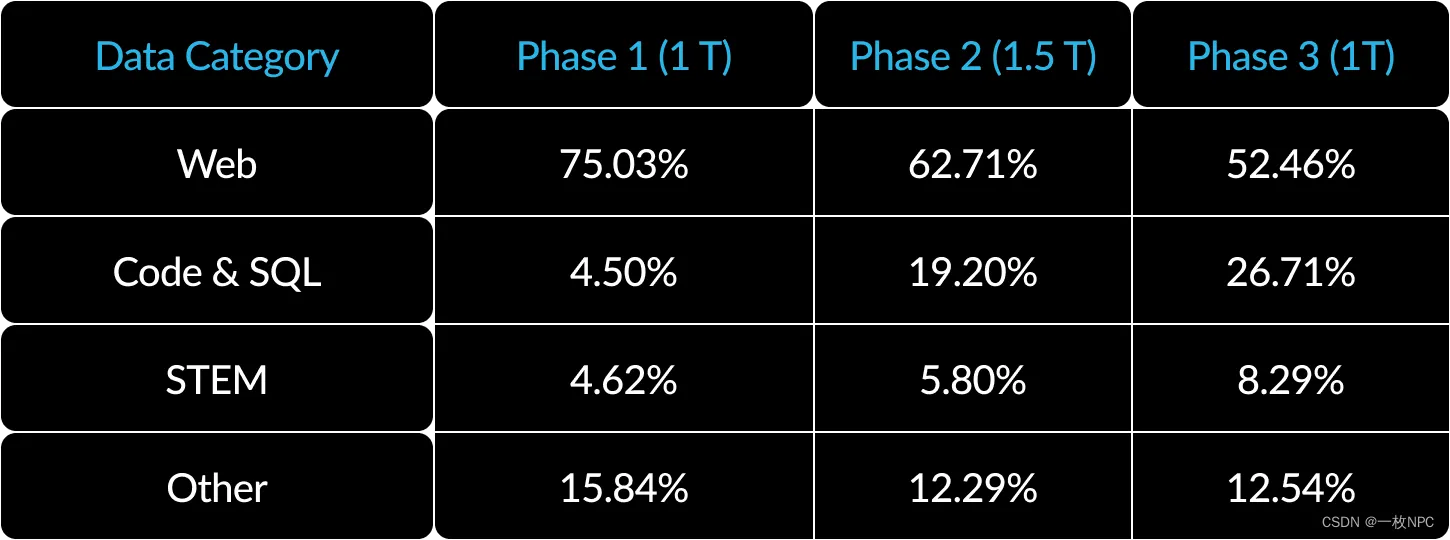
Table 2. Dynamic data composition for three-phase training of Arctic with emphasis on enterprise intelligence.
Inference efficiency
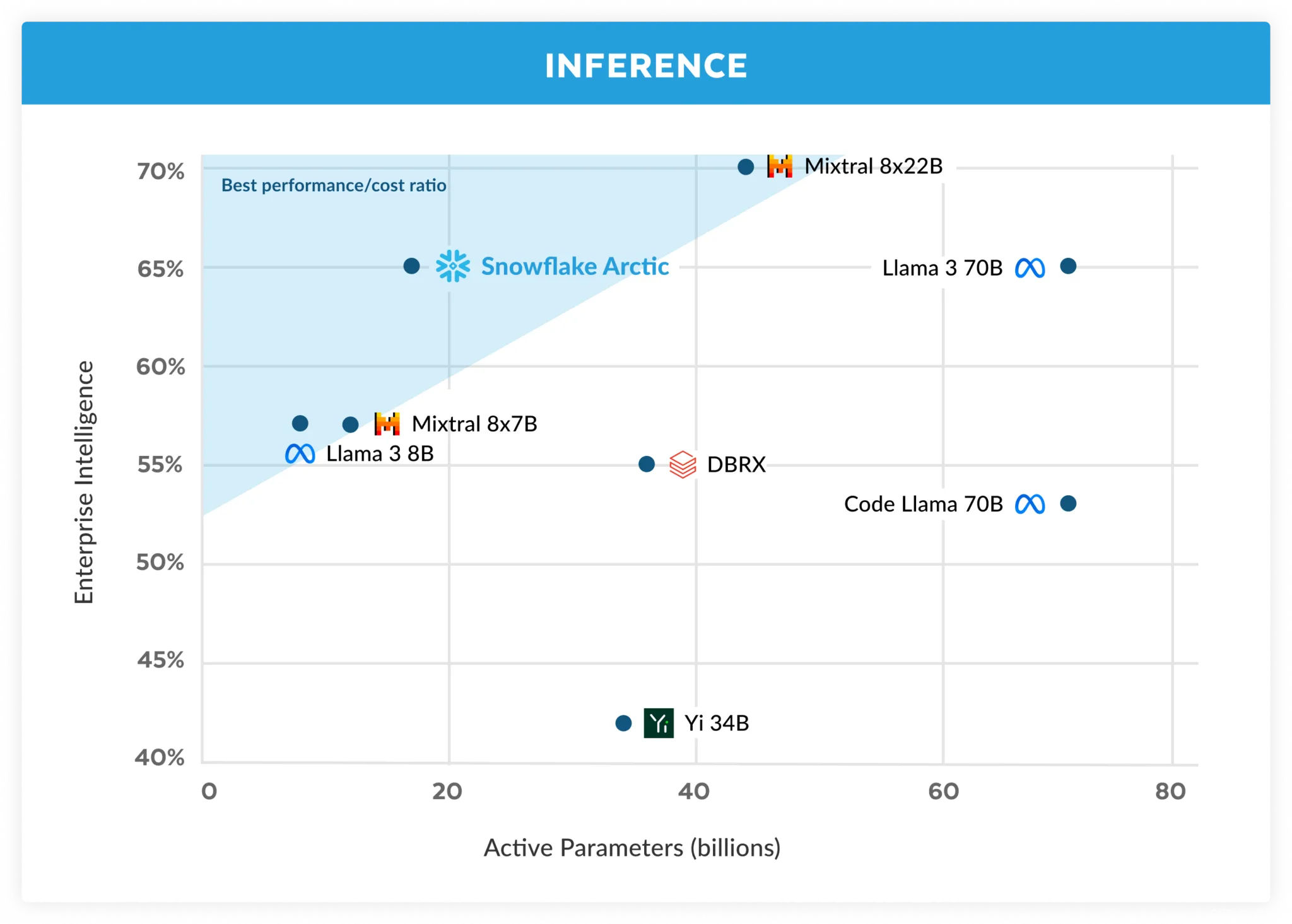
Figure 3. Enterprise intelligence – average of Coding (HumanEval+ and MBPP+), SQL Generation (Spider), and Instruction following (IFEval) vs. Active Parameters during Inference
训练效率只是北极高效情报的一个方面。推理效率对于以低成本实现模型的实际部署同样至关重要。Arctic代表了MoE模型规模的飞跃,使用的专家和总参数比任何其他开源自回归MoE模型都多。因此,为了有效地对北极进行推理,需要几个系统见解和创新:
a) 在小批量大小(例如,批量大小为1)的交互式推理中,MoE模型的推理延迟受到读取所有活动参数所需时间的限制,其中推理是有内存带宽限制的。在这种批量大小下,Arctic(17B活动参数)的内存读取量可以比Code Llama 70B少4倍,比Mixtral 8x22B(44B活跃参数)少2.5倍,从而提高推理性能。
我们与NVIDIA合作,并与NVIDIATensorRTLLM和vLLM团队合作,为交互式推理提供了Arctic的初步实现。使用FP8量化,我们可以在单个GPU节点中拟合Arctic。虽然远未完全优化,但在1的批量大小下,Arctic的吞吐量超过70多个代币/秒,可实现有效的交互式服务。
b) 随着批量大小的显著增加,例如,每次前向传递数千个令牌,Arctic从内存带宽绑定切换到计算绑定,其中推理受到每个令牌的活动参数的限制。在这一点上,Arctic的计算量比CodeLlama 70B和Llama 3 70B少4倍。
为了实现与北极地区少量活跃参数相对应的计算约束推理和高相对吞吐量(如图3所示),需要大批量。要实现这一点,需要有足够的KV高速缓存来支持大批量,同时也有足够的内存来存储模型的近500B参数。尽管具有挑战性,但这可以通过两个节点的推理来实现,该推理使用系统优化的组合,如FP8权重、分裂融合和连续批处理、节点内的张量并行性和跨节点的流水线并行性。
我们与NVIDIA密切合作,为TensorRT LLM提供的NVIDIA NIM微服务优化推理。与此同时,我们正在与vLLM社区合作,我们的内部开发团队也在未来几周内为企业用例实现Arctic的高效推理。
Truly open
Arctic是建立在我们多元化团队的集体经验以及社区的主要见解和学习的基础上的。开放的合作是创新的关键,如果没有来自社区的开源代码和开放的研究见解,Arctic就不可能实现。我们感谢社区,并渴望回馈我们自己的学习,丰富集体知识,赋予他人成功的力量。
我们对一个真正开放的生态系统的承诺不仅限于开放的权重和代码,还包括开放的研究见解和开源食谱。
Open research insights
通过这次发布,我们不仅仅是揭开模型的面纱;我们还通过一本全面的“食谱”分享我们的研究见解,这本书揭示了我们在艰难道路上的发现。该食谱旨在加快任何想要构建世界级MoE模型的人的学习过程。在制作类似于Arctic的LLM时,它提供了高层次的见解和精细的技术细节,这样你就可以在开放的道路而不是艰难的道路上高效、经济地构建你想要的智力。
这本食谱涵盖了广泛的主题,包括预训练、微调、推理和评估,还深入研究了建模、数据、系统和基础设施。您可以预览目录,其中概述了20多个主题。我们将在下个月每天发布相应的Medium.com博客文章。例如,我们将在“使用什么数据?”中披露我们的网络数据来源和提炼策略。我们将在《如何组成数据》中讨论我们的数据组成和课程。我们对国防部架构变化的探索将在“高级国防部架构”中详细介绍,讨论模型架构和系统性能的联合设计。对于那些对LLM评估感兴趣的人来说,我们的“如何评估和比较模型质量——没有你想象的那么简单”将揭示我们遇到的意想不到的复杂性。
通过这一举措,我们渴望为一个开放的社区做出贡献,在这个社区中,集体学习和进步是进一步推动这一领域界限的规范。
Here is a comparison of Arctic with multiple open source models across enterprise and academic metrics:
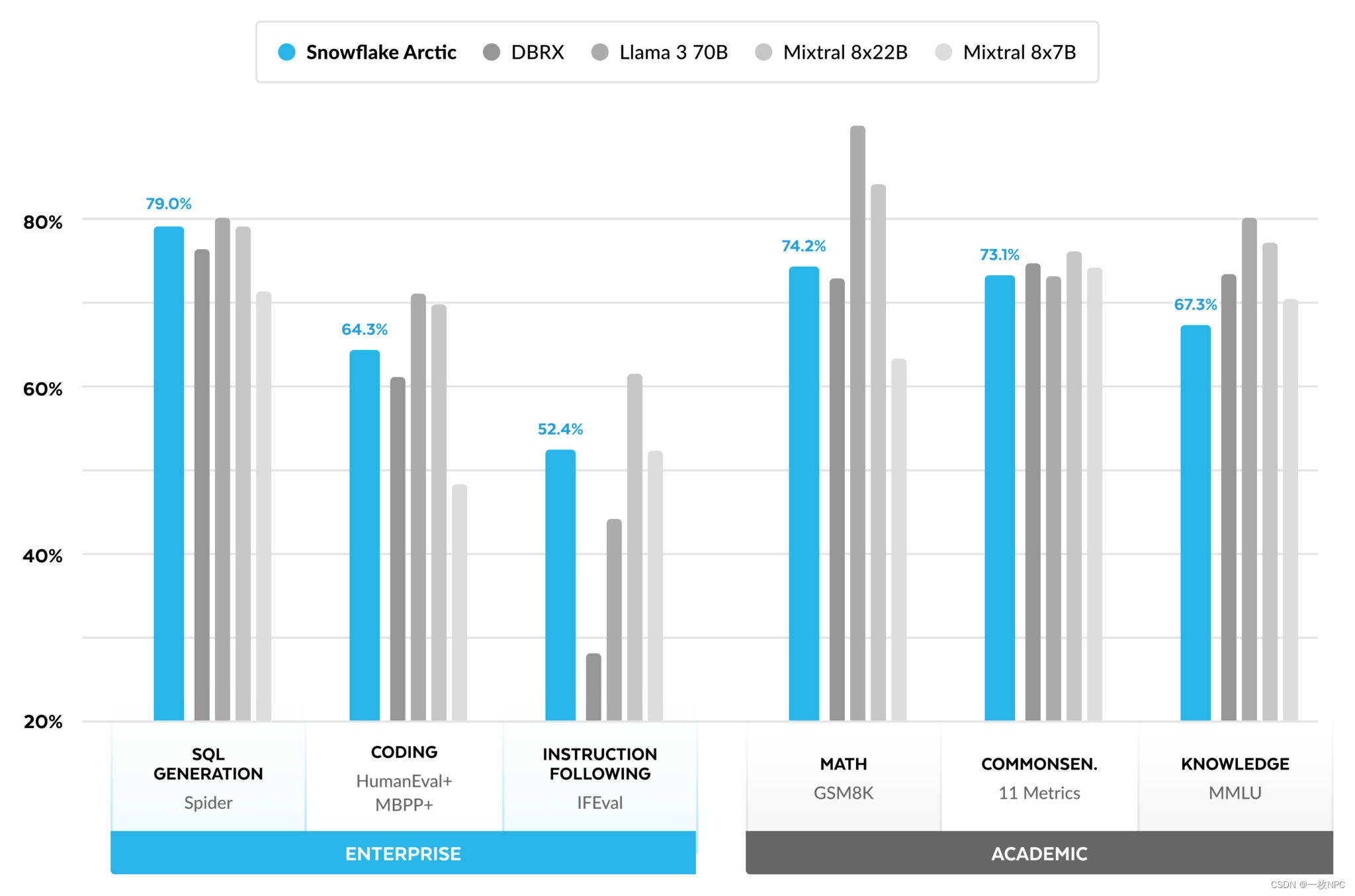
就企业指标而言,与所有其他开源模型相比,无论计算类别如何,Arctic都表现出了顶级性能。对于其他指标,它在其计算级别上实现了顶级性能,甚至与使用更高计算预算训练的模型保持竞争力。Snowflake Arctic是现成企业用例的最佳开源模型。如果您希望以最低的总体拥有成本(TCO)从头开始培训自己的模型,我们的烹饪书中的培训基础设施和系统优化描述应该会引起极大的兴趣。
对于学术基准,人们一直关注世界知识指标,如MMLU,以表示模型性能。有了高质量的网络和STEM数据,MMLU作为训练FLOPS的函数单调上升。由于Arctic的一个目标是优化训练效率,同时保持较小的训练预算,因此与最近的顶级模型相比,MMLU性能较低是一个自然的结果。根据这一见解,我们预计我们正在进行的训练计算预算高于Arctic,将超过Arctic的MMLU性能。我们注意到,MMLU世界知识的性能与我们对企业智能的关注并不一定相关。
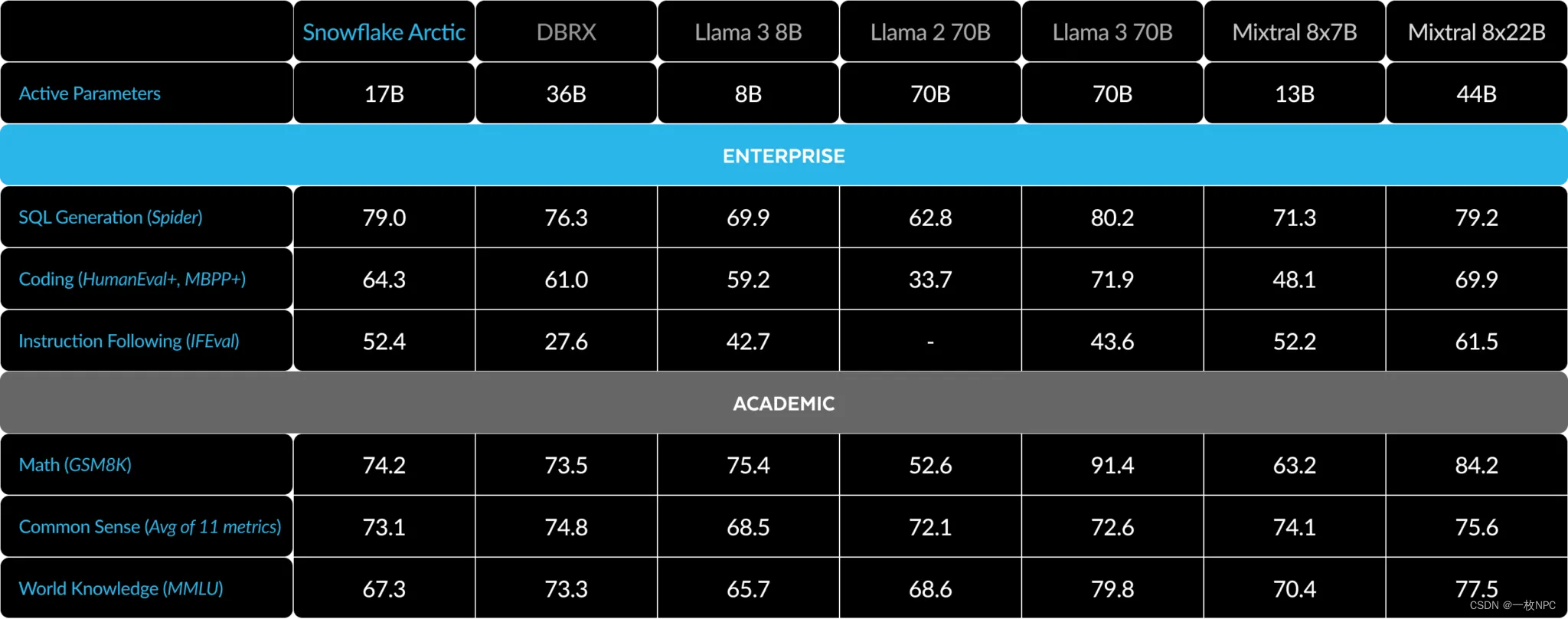
Table 3. Full Metrics Table. Comparing Snowflake Arctic with DBRX, LLAMA-3 8B, LLAMA-3 70B, Mixtral 8x7B, Mixtral 8x22B (instruction-tuned or chat variants if available).1 2
友情链接
Snowflake Arctic - LLM for Enterprise AI
GitHub - Snowflake-Labs/snowflake-arctic
精彩文章合辑
基于AARRR模型的录音笔在电商平台进行推广的建议-CSDN博客
【附gpt4.0升级秘笈】AutoCoder进化:本地Rag知识库引领智能编码新时代-CSDN博客
【附gpt4.0升级秘笈】OpenAI 重磅官宣免登录用 ChatGPT_openai 4.0 免费-CSDN博客
【附升级gpt4.0方案】探索人工智能在医疗领域的革命-CSDN博客
【文末 附 gpt4.0升级秘笈】超越Sora极限,120秒超长AI视频模型诞生-CSDN博客
【附gpt4.0升级秘笈】身为IT人,你为何一直在“高强度的工作节奏”?-CSDN博客
【文末附gpt升级4.0方案】英特尔AI PC的局限性是什么-CSDN博客
【文末附gpt升级4.0方案】FastGPT详解_fastgpt 文件处理模型-CSDN博客
大模型“说胡话”现象辨析_为什么大语言模型会胡说-CSDN博客
英伟达掀起AI摩尔时代浪潮,Blackwell GPU引领新篇章-CSDN博客
















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











