









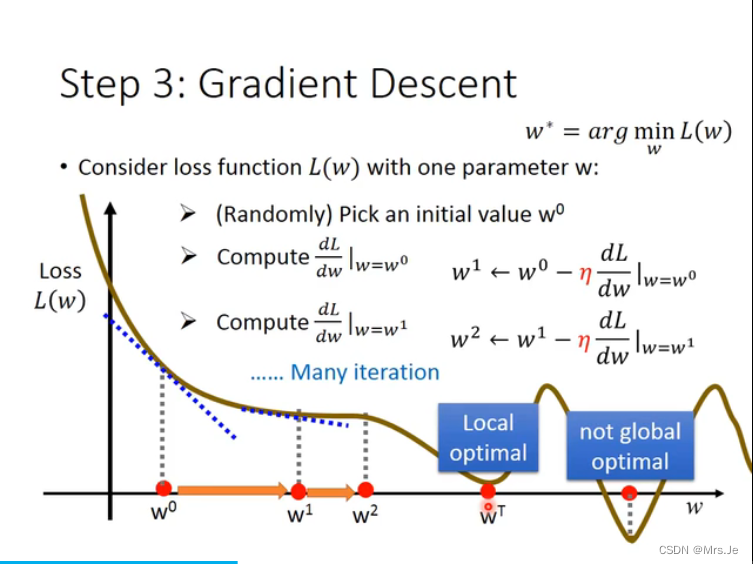


这里没有说到更新每个参数时会用到链式求导法则
视频:
https://www.bilibili.com/video/BV1Ht411g7Ef?p=3
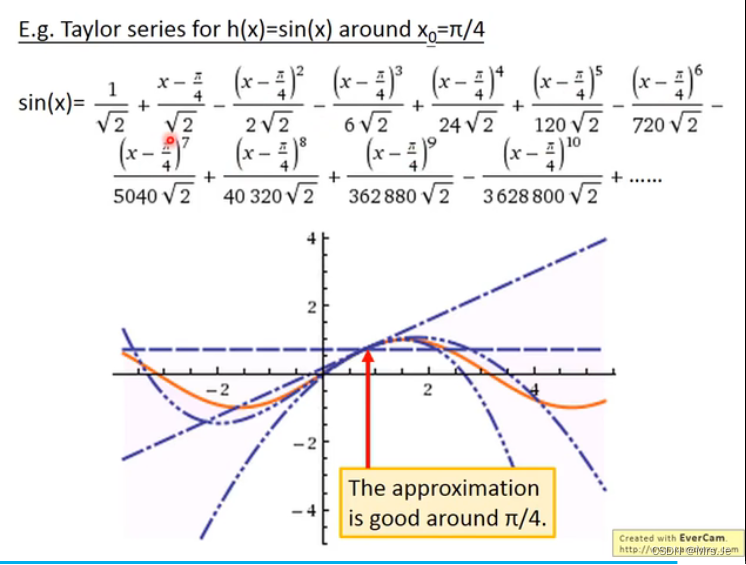
由Taylor Series展开


梯度下降做二次展开:


使得loss最小,

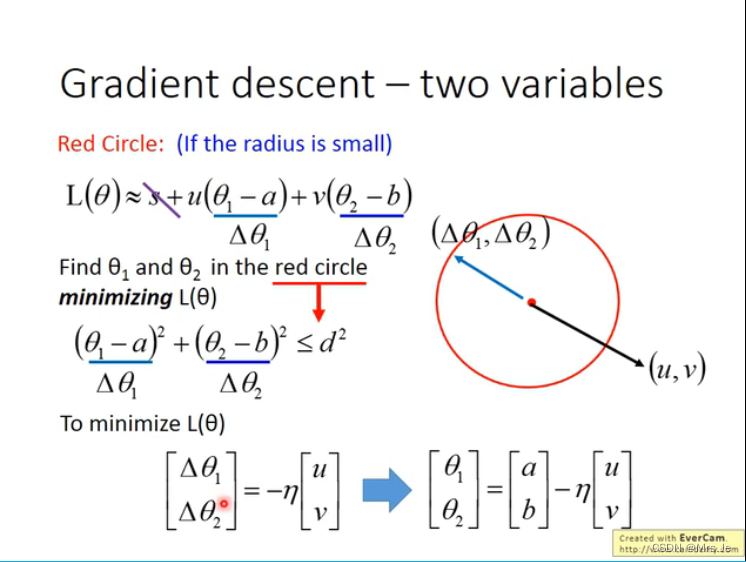

当学习率太大,则loss的泰勒展开的二次项之后的式子不能成立,
当red circle需要很小,半径与学习率成正比,所以理论上learning rate越小越好
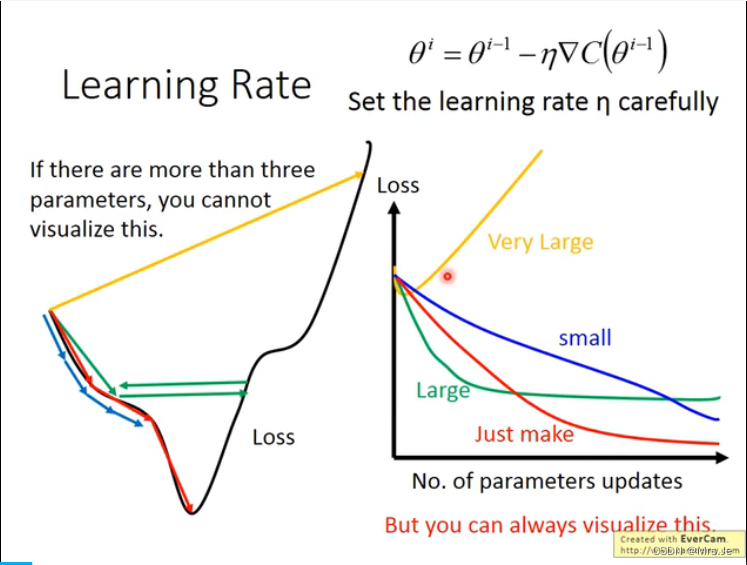
所以有adagrad针对不同的参数w不同的下降步长

Stochastic Gradient Descent,每次只取一个example,update一次参数

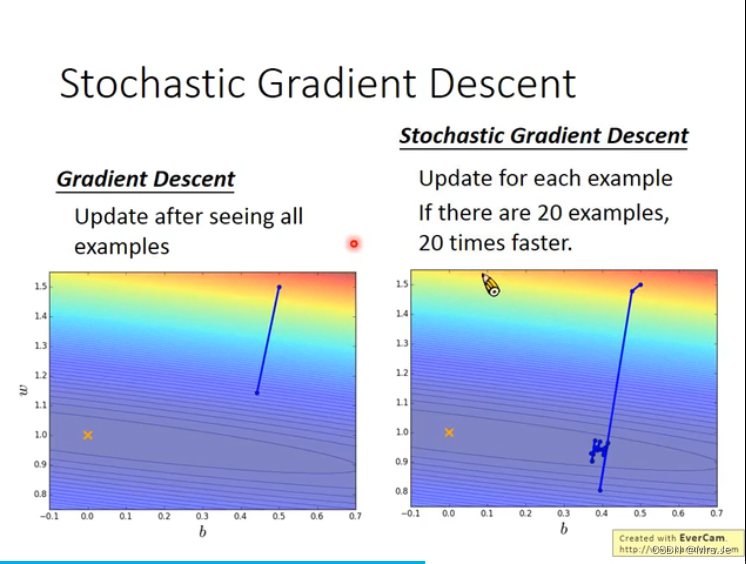
learning rate与更新参数,梯度下降的步长有关;
batch size与更新参数,梯度下降的次数有关
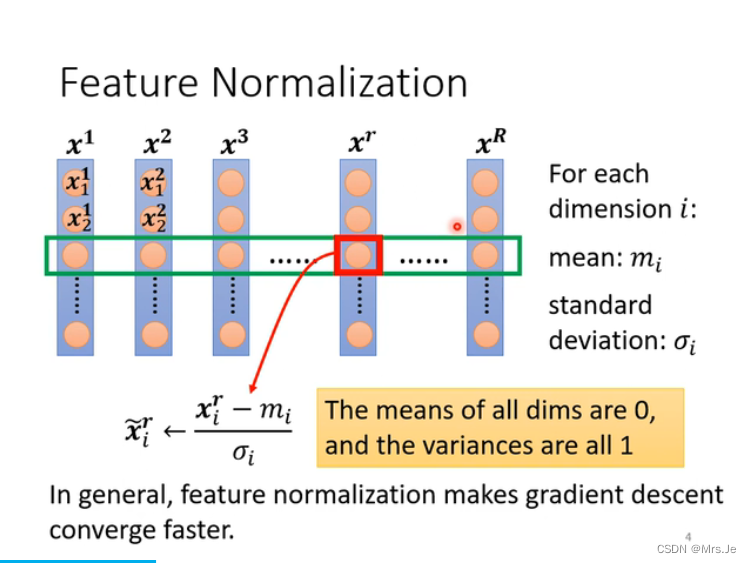
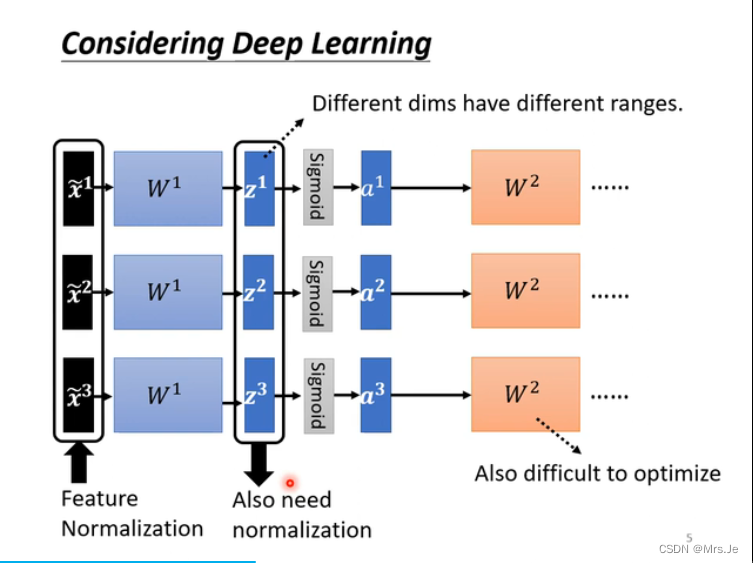
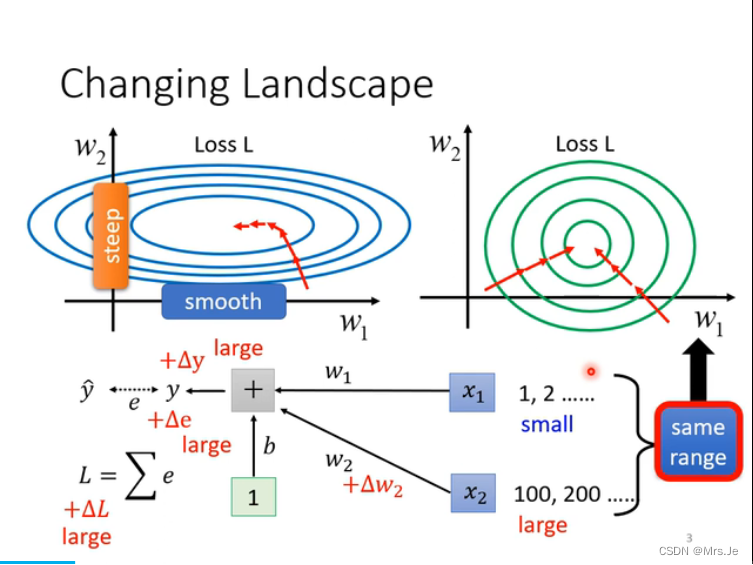
除了feature需要做normalization,
在activation function之前做normalization还是在activation function之后做;
差异不大,
Sigmoid在0处斜率较大,所以可能选择z做normalization比较好
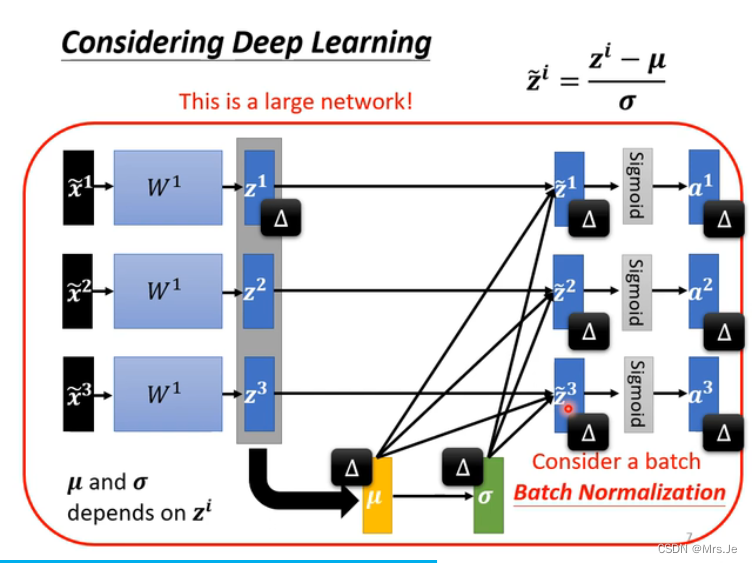
对于z来说,改变其中一个z,会改变normalization之后的所有z
batch normalization适用于比较大的batch,对大的Corp做normalization可以改为对batch做normalization
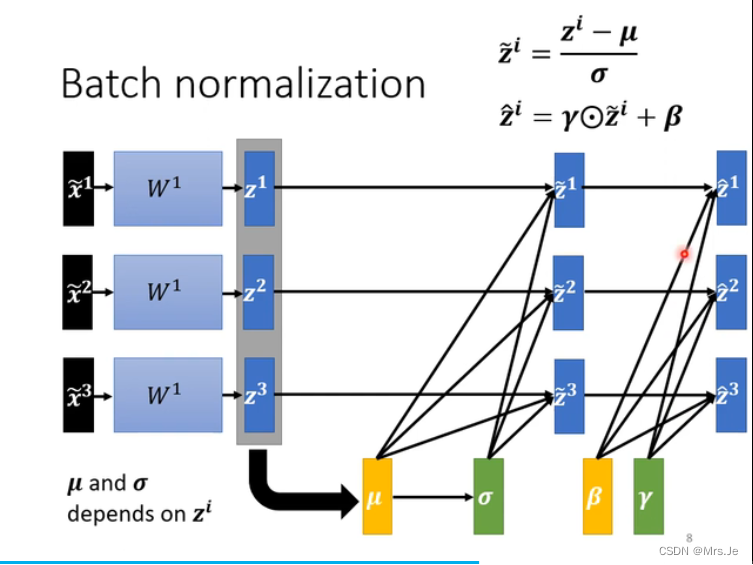
bata、gamma使得normalization后的z的u不为0
在开始bata=0,gamma=1,dimension的分布接近,训练到error surface的critical minima或者saddle point时,再加入
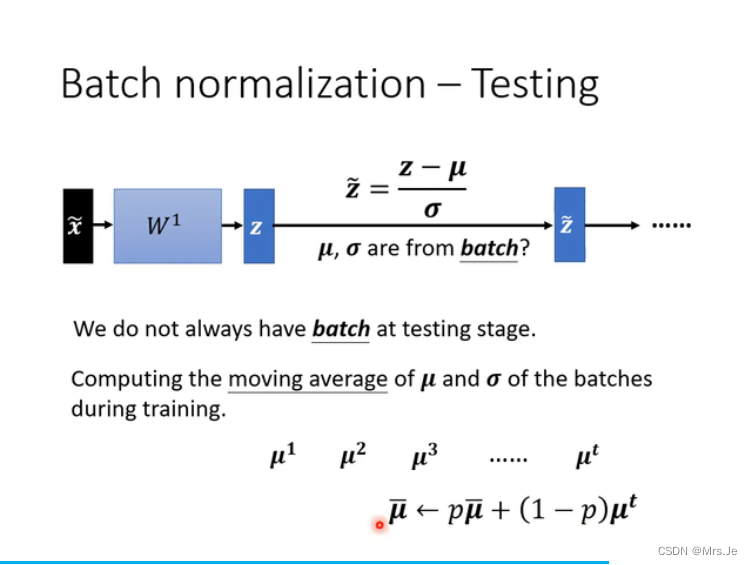
batch normalization,随着资料加进来,做normalization,u和sigama一直在变化
但实际上:
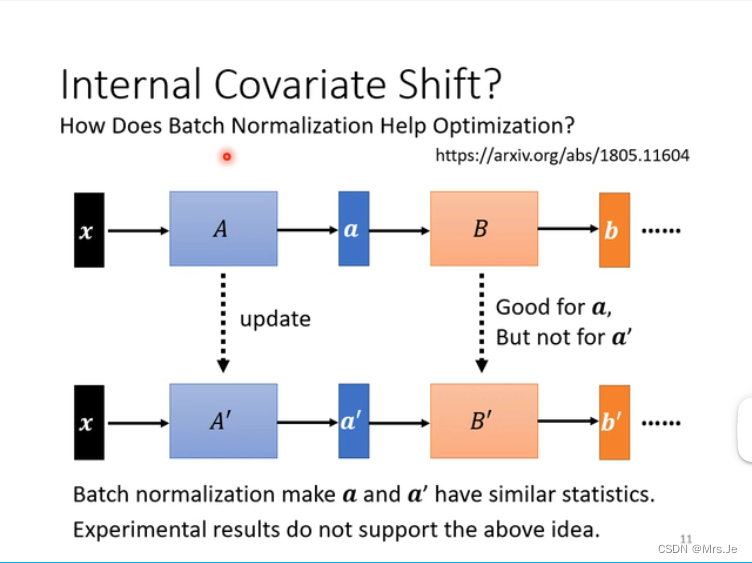
internal covariate shift不一定training network最主要的问题,也不是batch normalization会好的关键

batch normalization只是一种能提高optimization的方法















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









