







对于选择性不高的列甚至可以不创建索引。如果选择性不高,极端性情况下可能会扫描全部或者大多数索引,然后再回表,这样反而增加了io 的消耗,这个过程可能不如直接走主键索引性能高。
索引列的选择往往需要根据具体的业务场景来选择;
但是需要注意的是索引的区分度越高则价值就越高,意味着对于检索的性价比就高。
索引的区分度等于count(distinct 具体的列) / count(*),表示字段不重复的比例。
唯一键的区分度是1,而对于一些状态值,性别等字段区分度往往比较低,在数据量比较大的情况下,甚至有无限接近0。
假设一张表中用status来表示数据的状态,1-有效,2-删除,则数据的区分度为 1/500000。如果100万条数据中只有1条被删除,并且在查询数据时查找status = 0 的数据时,需要进行全表扫描。由于索引也是需要占用内存的,所以在内存较为有限的环境下或者为了提高性能的情况下,区分度不高的索引几乎没有意义。
可通过下图是一个区分度不高的索引查询数据的过程来理解下
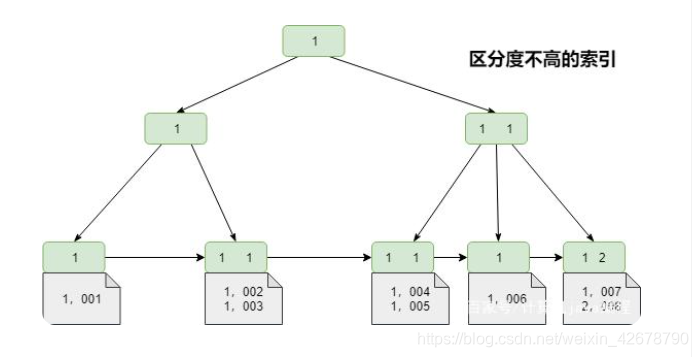

















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









