






一、简介
NoSQL数据库为了解决大规模数据集合多重数据种类的问题、大数据应用的难题。
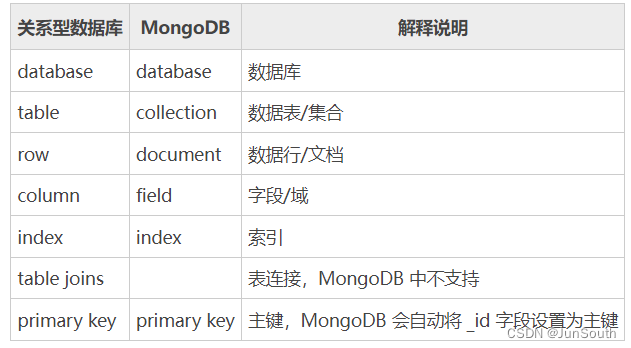
RDBMS(关系型数据库):常见的关系型数据库有 Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL;
NoSQL(非关系型数据库):常见的非关系型数据库有 MongoDB、Redis、Voldemort、Cassandra、Riak、Couchbase、CouchDB 等。
1.1、NoSQL体系框架
1、数据持久层
定义数据的存储形式,包括基于内存、硬盘、内存与硬盘相结合、订制可插拔四种形式。
2、数据分布层
定义数据的分布形式,主要有三种形。
CAP 支持:可用于水平扩展;
多数据中心支持:可保证在横跨多数据中心时也能平稳运行;
动态部署支持:可以在运行着的集群中动态地添加或删除节点。
3、数据逻辑层
数据的逻辑表现形式,主要有四种形式:
键值模型:表现形式上比较单一,却有很强的扩展性;
列式模型:相比于键值模型能够支持较为复杂的数据,但扩展性相对较差;
文档模型:对于复杂数据的支持和扩展性都有很大优势;
图模型:使用场景不多,通常基于图数据结构的数据定制的。
4、接口层
为上层应用提供了方便的数据调用接口,提供了五种选择:Rest、Thrift、Map/Reduce、Get/Put 和特定语言 API。
1.2、NoSQL适用场景
1.数据模型较简单;
2.灵活性要求很强;
3.对数据库性能要求较高;
4.不需要高度的数据一致性;
5.对于给定 key,较容易映射复杂值。
1.3、MongDB适用场景
1、易扩展性
能自动分片、自动转移分片里面的数据块,数据之间没有关系。每个服务器里面存储的数据都是一样大小。
2、网站数据具有高性能
非常适合实时的插入,保留了关系型数据库即时查询的能力,并具备网站实时数据存储所需的复制及高度伸缩性。
3、具有高伸缩性的场景
MongoDB 内置了 MapReduce 引擎,非常适合由数十或数百台服务器组成的数据库。
4、存储动态性
面向文档的形式可以使其属性值轻意的增加和删除。
5、速度与持久性
通过驱动调用写入时,可立即得到返回得到成功的结果(即使是报错),这样让写入的速度更快。
1.4、MongoDB特性
存储性
面向集合:数据被分组存储在数据集中也被称为集合。每个集合在数据库中都有一个唯一的标识名,并且可以包含多个的文档。
面向文档:存储在集合中的文档,被存储为key-values键对值的形式。键用于唯一标识一个文档,为字符串类型,而值可以是各种的文件类型。
高效二进制数据存储:包括大型对象,例如视频,MongoDB使用二进制格式存储数据,可以保存任何类型的数据对象
操作性
完全索引: 可在任意属性上建立索引,包含内部对象。
强大的聚合工具:如count、group等,支持使用MapReduce完成复杂的聚合任务。
支持Perl、PHP、Java、Python等现在主流开发语言的驱动程序
可用性
支持复制和数据恢复:支持主从复制机制,可以实现数据备份、故障恢复、读扩展等功能,MongoDB数据库的主从复制主挂了从会代替主。
自动处理分片:支持集群自动切分数据,对数据进行分片可以使集群存储更多的数据,实现更大的负载,也可以保证存储的负载均衡。
二、MongoDB的属性和常用语法
2.1、数据模型
文档具动态字段,同一集合(表)中的文档(行数据)无需字段一致。
简单的文档结构:
{
_id: ObjectId(601e288aaa203cc89f2d31a7),
title: 'MongoDB Concept',
description: 'MongoDB is no sql database',
by: '编程帮',
url: 'http://www.biancheng.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}2.1.1、规范化模型
相同格式的信息归类到同个文档中,通过ID关联。
Employee:
{
_id: ObjectId("601f4be6e646844cd045c8a4"),
Emp_ID: "10025AE336"
}
Personal_details:
{
_id: ObjectId("601f50bae646844cd045c8a5"),
empDocID: ObjectId("601f4be6e646844cd045c8a4"),
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
}
Contact:
{
_id: ObjectId("601f50bae646844cd045c8a6"),
empDocID: ObjectId("601f4be6e646844cd045c8a4"),
e-mail: "biancheng.net@gmail.com",
phone: "9848022338"
}
Address:
{
_id: ObjectId("601f50bae646844cd045c8a7"),
empDocID: ObjectId("601f4be6e646844cd045c8a4"),
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}2.1.2、嵌入式模型
不同格式的信息整合到一个文档中
{
_id: ObjectId("601f4be6e646844cd045c8a4"),
Emp_ID: "10025AE336",
Personal_details:{
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
},
Contact: {
e-mail: "biancheng.net@gmail.com",
phone: "9848022338"
},
Address: {
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}
}2.2、数据类型
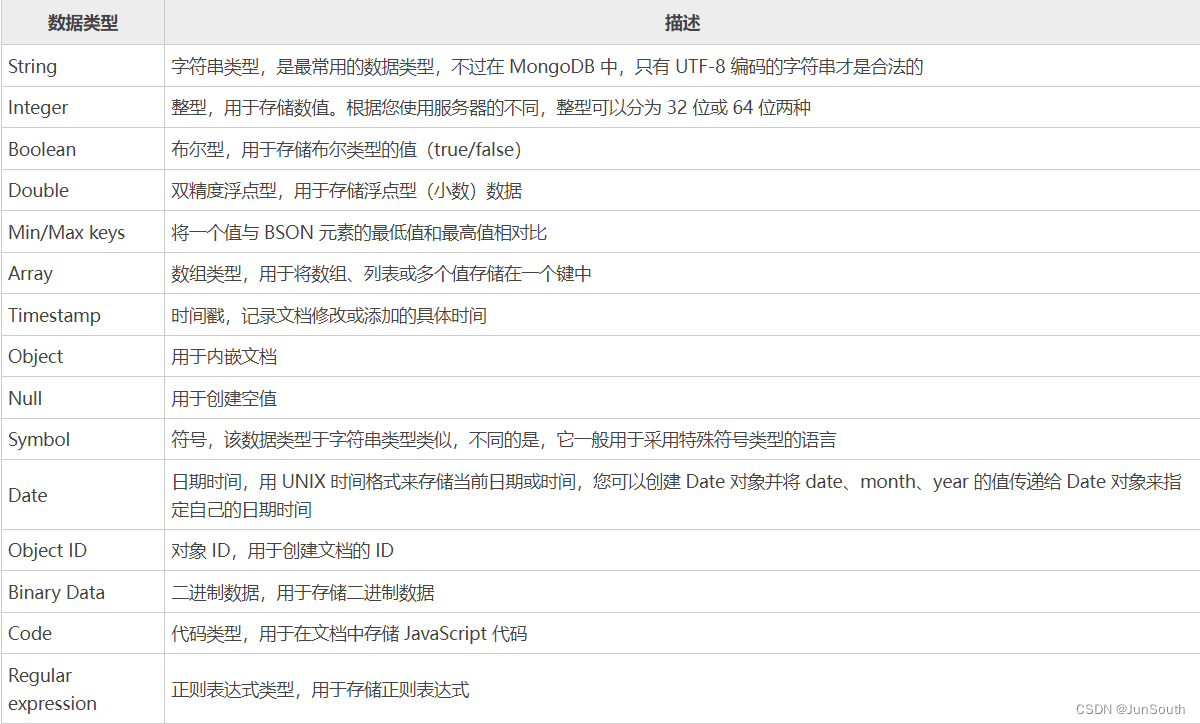
2.2.1、 常用数据类型
2.2.2、特殊数据类型
Object ID 类似于关系型数据库中的主键 ID,在 MongoDB 中 Object ID 由 12 字节的字符组成,
601e2b6b aa203c c89f 2d31aa
↑ ↑ ↑ ↑
时间戳 机器码 进程id 计数器Timestamps(时间戳)
与 Date 类型不同,Timestamps 由一个 64 位的值构成,其中:
前 32 位是一个 Unix 时间戳(由 Unix 纪元(1970.1.1)开始到现在经过的秒数);
后 32 位是一秒内的操作序数。Date
是一个 64 位的对象,其中存放了从 Unix 纪元(1970.1.1)开始到现在经历的毫秒数,Date 类型是有符号的,负值则表示 1970.1.1 之前的时间。
2.3、 内置角色
1.数据库用户角色:read、readWrite;
2.数据库管理角色:dbAdmin、dbOwner、userAdmin;
3.集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
4.备份恢复角色:backup、restore;
5.所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
6.超级用户角色:root
提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)
3、MongoDB默认四个数据库
admin: 保存用户信息、权限的数据库;
config: 集群中使用的,分片数据库;
local: local的数据只存在于本地数据,不会被同步到其他数据库;
test: test为MongoDB默认登录的数据库。
2.4、常用语句
查看 MongoDB 中所有的数据库,
show dbs
删除数据库:tete0001
db.dropDatabase({ "dropped" : "tete0001", "ok" : 1 })
查看集合
show collections
创建集合 myCollection 并插入数据
db.myCollection.insert(
{name:"fff", address:"fff",age:18}
)
删除集合 myCollection
db.myCollection.drop()
插入数据
db.myCollection.insert({name:"ccc", address:"ccc"})
批量插入
db.myCollection.insert([
{name:"ccc", address:"ccc"},
{name:"kkk", address:"ccc"},
{name:"ooo", address:"ccc"}
])
查询集合下所有数据
db.myCollection.find()
条件查询 and
db.myCollection.find({$and:[{name:"aa"}]}).pretty()
条件查询 or
db.myCollection.find({$or:[{name: "aa"},{address:"ccc"}]})
查询 根据name字段 顺序
db.myCollection.find().sort({name:1})
查询 根据name字段 降序
db.myCollection.find().sort({name:-1})
更新文档 通过字段
db.myCollection.update({name:"aa"},{$set:{address:"aaaaaaaa"}})
更新文档 通过ID
db.myCollection.update({_id:ObjectId("655715b7cd7fd1d8c6e32b55")},{$set:{address:"aaaaaaaa"}})
修改嵌套List
db.myCollection.update({_id:ObjectId("655ac5b56dfadf24156ee69b")},{$set:{dialogues: [{
"ask": "今天是礼拜天?",
"answer": "是的",
"createTime": 1697356990966
}, {
"ask": "你也要加油哈",
"answer": "奥利给!",
"position": "middle",
"createTime": 1697378011483
}, {
"ask": "下周见",
"answer": "拜拜!",
"length": "100mb",
"createTime": 1697378072063
}]}}
)
修改字段名
db.getCollection('集合名').updateMany( {}, { $rename: { "老字段名": "新字段名" } } )
多字段修改
db.manong.updateMany({},{$rename:{"name":"studentName", "age":"studentAge"}});
删除文档
db.myCollection.remove({name:'ccc'})
查看索引
db.myCollection.getIndexes()
根据 name字段 创建索引
db.myCollection.createIndex({name:1})
删除 name字段索引
db.myCollection.dropIndex({name:1})索引的属性

三、Spring整合MongoDB
1、 配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>spring:
data:
mongodb:
host: 127.0.0.1
database: test
port: 27017
# 也可用uri mongodb://127.0.0.1:27017/test2、JPA 方式
1.创建实体类
public class MyUser {
@Id
private String id;
private String name;
private Integer age;
public MyUser() {}
public MyUser(String id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "MyUser{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}2.接口和测试类
/**
* 继承 MongoRepository 即可,不要实现
*/
public interface MyUserRepository extends MongoRepository<MyUser, String> {
}
@SpringBootTest
public class MyUserRepositoryTest {
@Autowired
private MyUserRepository myUserRepository;
/**
* 插入单条数据
*/
@Test
public void insertOne() {
MyUser user = new MyUser("11", "tom", 18);
myUserRepository.insert(user);
}
/**
* 插入多条数据
*/
@Test
public void insertMany() {
MyUser user01 = new MyUser("11", "tom", 18);
MyUser user02 = new MyUser("22", "jake", 22);
List<MyUser> list = new ArrayList<>();
list.add(user01);
list.add(user02);
myUserRepository.insert(list);
}
/**
* 删除操作
*/
@Test
public void remove() {
//根据id删除单个对象
myUserRepository.deleteById("11");
//根据字段删除
Student student = new Student();
student.setAge(22);
myUserRepository.delete(student);
//根据字段删除多个
MyUser user02 = new Student();
user02.setName("jerry");
List<MyUser> list = new ArrayList<>();
list.add(user02);
myUserRepository.deleteAll(list);
//删除所有
myUserRepository.deleteAll();
}
/**
* 修改数据
*/
@Test
public void update() {
Optional<MyUser> op = myUserRepository.findById("11");
MyUser user = op.get();
user.setAge(22);
myUserRepository.save(user);
}
/**
* 查询数据
*/
@Test
public void query() {
//根据Id查询单个对象
Optional<MyUser> stuOp = myUserRepository.findById("01");
System.out.println(stuOp.get());
//根据字段查询单个对象
MyUser user = new MyUser();
user.setAge(19);
Optional<MyUser> stuOp1 = myUserRepository.findOne(Example.of(user));
System.out.println(stuOp1.get());
//根据id列表查询多个对象
Iterable<MyUser> itStu = myUserRepository.findAllById(Arrays.asList(new String[]{"001", "002"}));
Iterator<MyUser> itor = itStu.iterator();
while (itor.hasNext())
System.out.println(itor.next());
//查询所有
List<MyUser> all = myUserRepository.findAll();
//查询所有并排序
List<MyUser> all1 = myUserRepository.findAll(Sort.by(Sort.Order.desc("studentId"), Sort.Order.asc("studentName")));
for (MyUser use : all1)
System.out.println(use);
//根据条件查询所有并排序
MyUser user01 = new MyUser();
user01.setName("tom");
List<MyUser> all2 = myUserRepository.findAll(Example.of(user01), Sort.by(Sort.Order.desc("studentId"), Sort.Order.asc("studentName")));
for (MyUser use : all2)
System.out.println(use);
//根据条件查询所有并排序,且分页
Pageable pageable = PageRequest.of(0, 2);
Page<MyUser> all3 = myUserRepository.findAll(pageable);
List<MyUser> content = all3.getContent();
for (MyUser use : content)
System.out.println(use);
}
/**
* 其他操作
*/
@Test
public void other() {
//count
long count = myUserRepository.count();
System.out.println(count);
MyUser user = new MyUser();
user.setAge(18);
long count1 = myUserRepository.count(Example.of(user));
System.out.println(count1);
//exists
boolean exists = myUserRepository.exists(Example.of(user));
System.out.println(exists);
boolean b = myUserRepository.existsById("001");
System.out.println(b);
}
}3、MongoTemplate 方式
1.接口
public interface UserDao {
//插入单个对象
void addOne(MyUser user);
//根据id删除单个对象
void deleteOneById(String studentId);
//修改单个对象
void updateOne(MyUser user);
//根据id获取单个对象
MyUser findOneById(String studentId);
//获取全部学生
List<MyUser> findAll();
}2.实现类
public class UserDaoImpl implements UserDao {
@Autowired
private MongoTemplate mongoTemplate;
@Override
public void addOne(MyUser user) {
mongoTemplate.save(user);
}
@Override
public void deleteOneById(String studentId) {
MyUser stu = mongoTemplate.findById(studentId, MyUser.class);
if (stu != null)
mongoTemplate.remove(stu);
}
@Override
public void updateOne(MyUser user) {
mongoTemplate.save(user);
}
@Override
public MyUser findOneById(String id) {
return mongoTemplate.findById(id, MyUser.class);
}
@Override
public List<MyUser> findAll() {
return mongoTemplate.findAll(MyUser.class);
}
}3.MongoTemplate的其它用法
Criteria
eq:等于,第一个参数是对象属性,第二个参数是值
allEq:参数为一个Map对象,相当于多个eq的叠加
gt:大于
ge:大于等于
lt:小于
le:小于等于
between:在两个值之间Expression.between('age',new Integer(10),new Integer(20));
like:like查询
in:in查询
is查询:
Query query = new Query();
// where...is... 相当于 where ? = ?
query.addCriteria(Criteria.where("数据库字段名").is("你的参数"));
// findOne 返回的是一个对象 Class代表你的表对应的映射类
mongoTemplate.findOne(query, Class.class);
// find 返回的是数组
mongoTemplate.find(query, Class.class);
in查询:
ArrayList<String> list = new ArrayList<>();
// list代表你的数据
Query query = Query.query(Criteria.where("数据库字段").in(list));
mongoTemplate.find(query, Class.class);
// 如果想要查询指定的数据是否在数据库的数组中,可以用以下方法。
Query query = Query.query(Criteria.where("数据库字段(数组)").is("你的数组"));
字符模糊查询:
Query query = Query.query(Criteria.where("name").regex("小"));
指定字段不返回:
query.fields().exclude("field");
数组中添加或删除一条数据:
Query query = Query.query(Criteria.where("_id").is("id"));
Update update = new Update();
// push方法可以在数组中添加一条数据。
// pull方法可以在数组中删除一条数据。
// update.pull()。
update.push("字段名称", "data");
mongoTemplate.updateFirst(query, update, Class.class);
// 分页
query.limit(10);
// 排序
Sort sort=Sort.by(Sort.Direction.DESC,"timestamp");
query.with(sort);四、MongoDB的内部
1、索引
Cassandra、Elasticsearch (Lucene)、Google Bigtable、Apache HBase、LevelDB 和 RocksDB 这些当前比较流行的 NoSQL 数据库存储引擎是基于 LSM 开发的。
MongoDB 存储引擎用的 B+Tree,索引在创建时必须指定顺序(1:升序,-1:降序),所有集合都有一个默认索引 _id,是唯一索引,类似 MySql 的主键。
1.索引类型有
单字段索引:建立在单个字段上的索引,索引创建的排序顺序无所谓,可头/尾开始遍历。
复合索引:建立在多个字段上的索引。
多 key 索引:对数组字段创建索引时,就是多 key 索引,MongoDB 会为数组的每个值创建索引。
Hash 索引:按数据的哈希值索引,用在 hash 分片集群上。
地理位置索引:基于经纬度的索引,适合 2D 和 3D 的位置查询。
文本索引: MongoDB 虽然支持全文索引,但性能低下。
2、集群
1.MongDB 复制集群
MongoDB 高可用的基础是复制集群,一份数据多处备份。
一个主节点(Primary):负责整个集群的写操作入口,主节点挂掉之后会自动选出新的主节点。
多个从节点(Secondary):一般是 2 个或以上,从主节点同步数据,在主节点挂掉之后选举新节点。
2.保证数据一致
Journal日志: MongoDB 的预写日志 WAL,类似 MySQL 的 redo log,然后100ms一次将Journal 日子刷盘。
Oplog日志: 做主从复制,类似 MySql 里的 binlog。MongoDB 的写操作都由 Primary 节点负责,Primary 节点会在写数据时会将操作记录在 Oplog 中,Secondary 节点通过拉取 oplog 信息,回放操作实现数据同步的。
Checkpoint节点:MongoDB 每60s一次将内存中的变更刷盘,并记录当前持久化点(checkpoint),以便数据库在重启后能快速恢复数据。
3.结论
1.MongoDB 宕机重启后可通过 checkpoint 快速恢复上一个 60s 之前的数据。
2.MongoDB 最后一个 checkpoint 到宕机期间的数据可以通过 Journal日志回放恢复。
3.Journal日志因为是 100ms 刷盘一次,因此至多会丢失 100ms 的数据(可通过 WriteConcern 的参数控制)
4.如果在写数据开启了多数写,那么就算 Primary 宕机了也是至多丢失 100ms 数据(可避免,同上)
3、分片架构
Config:存储集群的各种元数据和配置,如分片地址、chunks 等。
Mongos:路由服务,不存具体数据。
Mongod:单个分片。
1.数据均衡的实现方式
1.分片集群上数据管理单元叫 chunk,一个 chunk 默认 64M,可选范围 1 ~ 1024M。
2.集群的 chunk数量, chunk大小,chunk 在哪个分片上,都是存在 Config 上。
3.MongoDB 在运行时会自定检测不同分片上的 chunk 数,通过chunk 迁移,使每个分片上的 chunk 均衡。
4.chunk 迁移过程叫 rebalance,比较耗资源,一般要把它的执行时间设置到业务低峰期。
2.分片算法
区间分片:可以按 shardkey 做区间查询的分片算法,直接按照 shardkey 的值来分片。
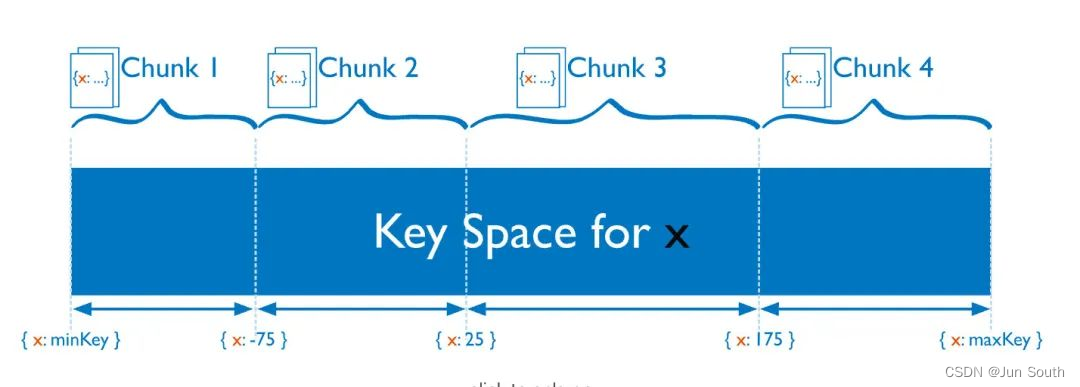
hash分片:用的最多的分片算法,按 shardkey 的 hash 值来分片。hash 分片可以看作一种特殊的区间分片。

分片的本质是将 shardkey 按一定的函数变换 f(x) 之后的空间划分为一个个连续的段,每一段就是一个 chunk。
区间分片 f(x) = x;hash 分片 f(x) = hash(x)
每个 chunk 在空间中起始值是存在 Config 里面的。
当请求到 Mongos 的时候,根据 shardkey 的值算出 f(x) 的具体值为 f(shardkey),找到包含该值的 chunk,然后就能定位到数据的实际位置了。
4、其它特性
1.数据压缩
MongoDB 会自动把数据压缩之后再落盘。
Snappy:默认的压缩算法,压缩比 3 ~ 5 倍
Zlib:高度压缩算法,压缩比 5 ~ 7 倍
前缀压缩:索引用的压缩算法,简单理解就是丢掉重复的前缀
zstd:MongoDB 4.2 之后新增的压缩算法,拥有更好的压缩率
2.执行计划 explain
和 MySql 的 explain 功能相同 queryPlanner:MongoDB 运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划。 exectionStats:mongoDB 运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划进行执行。在执行完毕后返回这个最佳执行计划执行完成时的相关统计信息。 allPlansExecution:即按照最佳的执行计划执行以及列出统计信息,如果有多个查询计划,还会列出这些非最佳执行计划部分的统计信息。。















 1770
1770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









