






本文借助 transformer 易于解释的特点提出了基于token embedding 重要性的 weighted adaptation的方法。
关于SAM跨模态知识蒸馏的最新工作:Segment Any Events via Weighted Adaptation of Pivotal Tokens。(Arxiv Github)
我们都看到这几个月关于SAM,Large Pretrained Model等的工作层出不穷,但是他们大部分是基于常见模态的数据,比如图像,文本等。但是对于其他缺少大量标注数据的模态,这时如何有效的进行有效的pretrained知识迁移就变成了一个重要问题。在本文,为了解决这个问题,我们借助 transformer 易于解释的特点提出了基于token embedding 重要性的 weighted adaptation的方法。
1. 方法
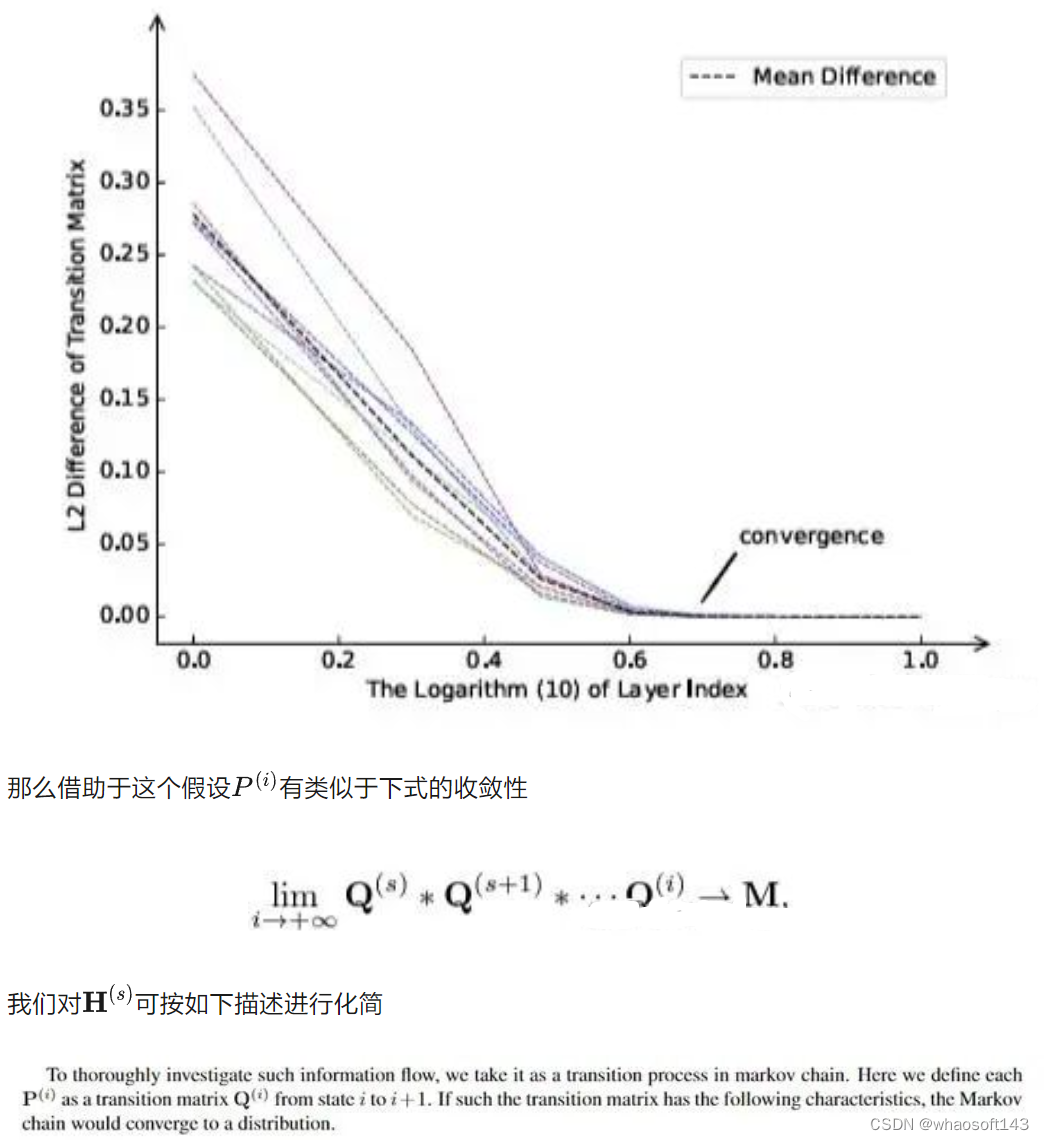
具体的来说,我们的方法首先建立在一个理性的假设上。虽然我们期望network尽量减小不同modalities的分布差异,但是由于不同模态的内在的差异,我们是无法完全对齐一个模态的输入到令一个模态。这时,我们自然而然的想到一个问题就是不同的token embedding 对于最终的任务是否有重要性的区别?网络可解释性的论文能够对不同区域的feature 重要性给出支持,但是大多数工作需要借助反向传播的梯度进行解释。本来蒸馏需要我们同时跑两个网络,如果还要求对两个网络进行反向传播将会让训练开销大大增加。如果我们能够以比较低的代价(无需对teacher 进行反向传播)进行token重要性的评价的话,我们相信将对训练效率较大的帮助。
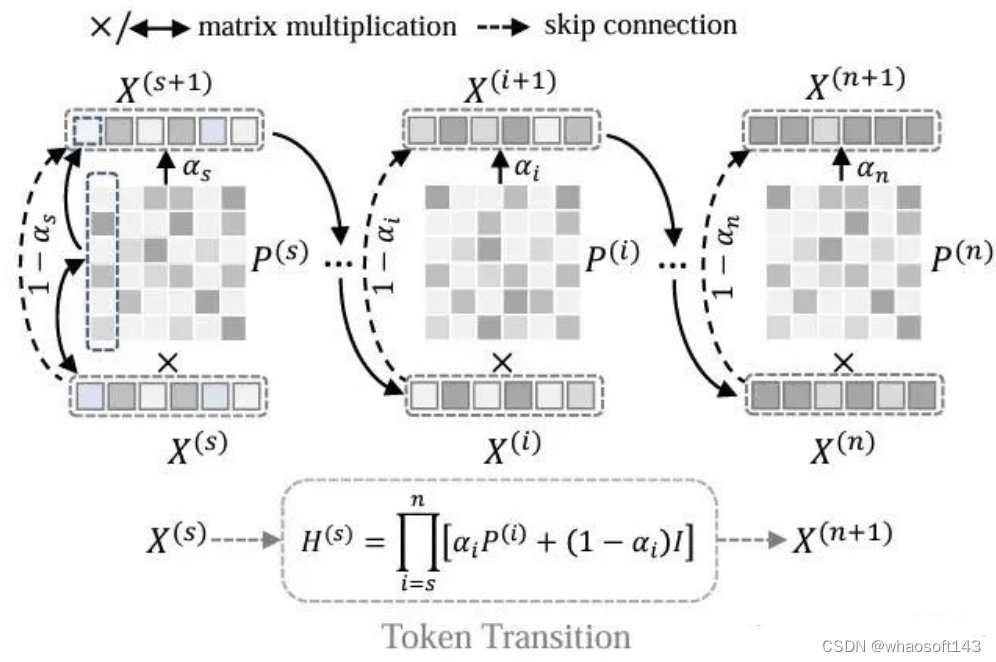
图1. 我们对transformer 整个过程进行了"超大量"的化简,其信息流动过程变成了如图所示


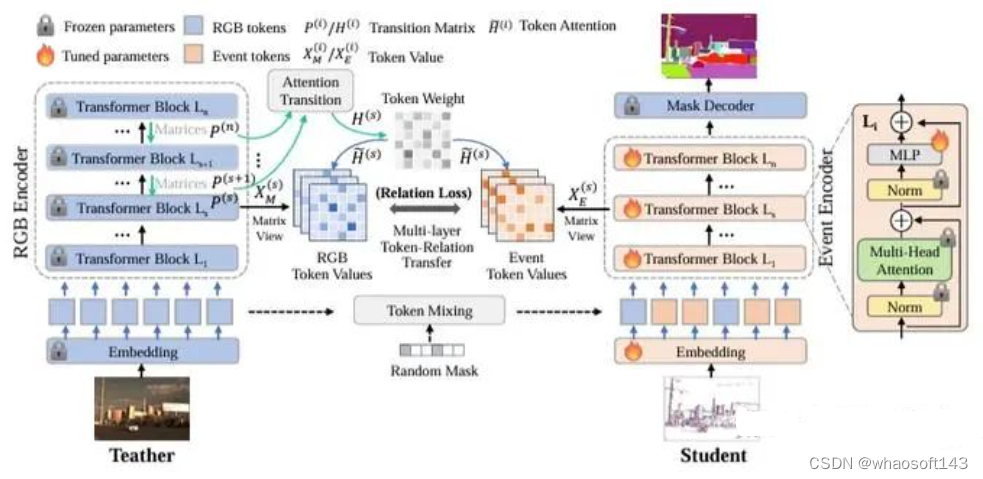
整体training flow 如下
2. 结果
实验结果如下所示,领先其他方法。

实验视觉结果
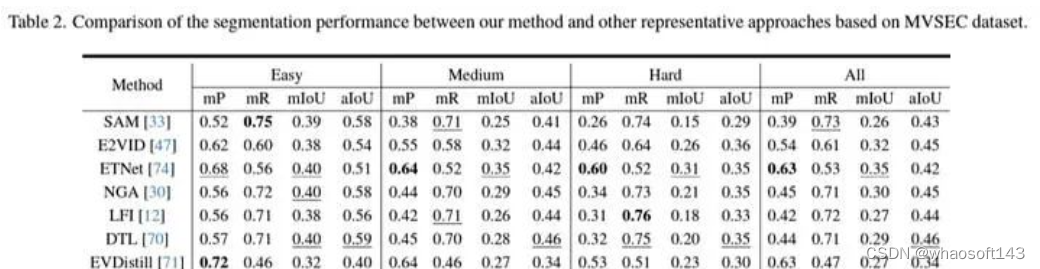
实验结果
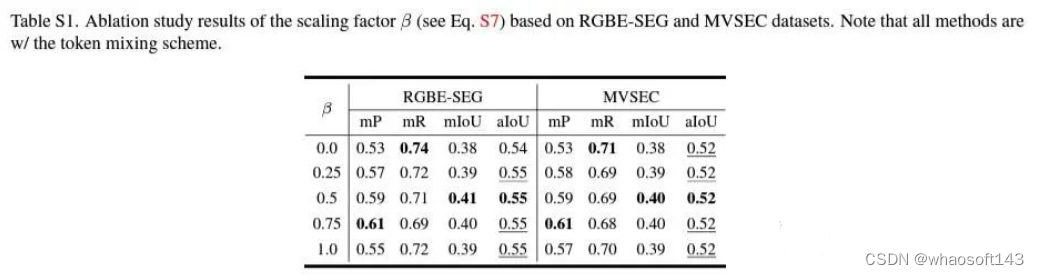
不同β的效果
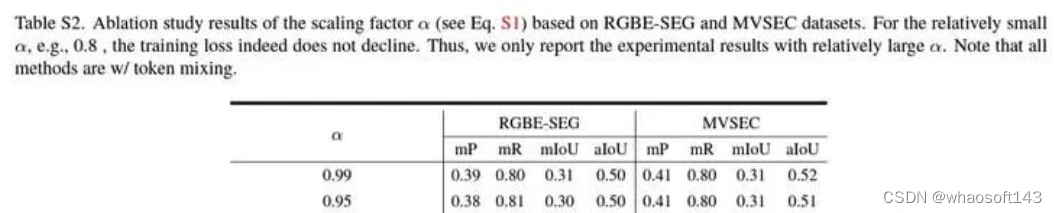
不同α的结果
我们同时嵌入adapted sam 到LLM-SAM 联合的方法,效果如下。






详情请见:
Arxiv:https://arxiv.org/abs/2312.16222
Github:https://github.com/happychenpipi/EventSAM















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









