







 Spark是一个高效、通用的分布式计算框架,以其内存计算和低延迟的优势,尤其适合迭代计算和交互式数据挖掘。它通过RDD(弹性分布式数据集)实现数据的容错性和内存管理,对比Hadoop,Spark在速度和通用性上更具优势。Spark支持丰富的Scala、Java、Python API和交互式Shell,提供灵活的MapReduce操作,并具备良好的容错性和可用性。
Spark是一个高效、通用的分布式计算框架,以其内存计算和低延迟的优势,尤其适合迭代计算和交互式数据挖掘。它通过RDD(弹性分布式数据集)实现数据的容错性和内存管理,对比Hadoop,Spark在速度和通用性上更具优势。Spark支持丰富的Scala、Java、Python API和交互式Shell,提供灵活的MapReduce操作,并具备良好的容错性和可用性。
目标Scope(解决什么问题)
在大规模的特定数据集上的迭代运算或重复查询检索
官方定义:
a MapReduce-like cluster computing framework designed for low-latency interativejobs and interactive use from an interpreter
首先,MapReduce-like是说架构上和多数分布式计算框架类似,Spark有分配任务的主节点(Driver)和执行计算的工作节点(Worker)
其次,Low-latency基本上应该是源于Worker进程较长的生命周期,可以在一个Job过程中长驻内存执行Task,减少额外的开销
然后对interative重复迭代类查询运算的高效支持,是Spark的出发点了。最后它提供了一个基于Scala的Shell方便交互式的解释执行任务
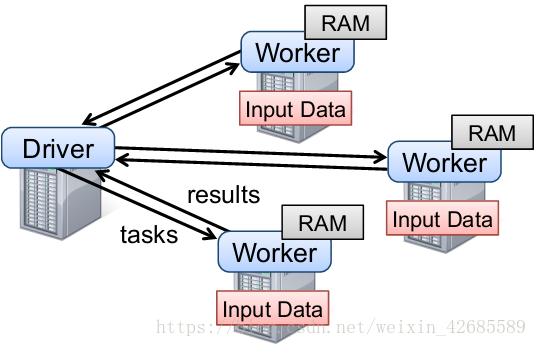
核心思路或架构:
RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
RDD--分布式弹性数据集可以把数据集保持在内存中,而不是在磁盘中,这样每次计算只需要从内存中读取数据,而不是通过IO读取磁盘,跨过了系统IO瓶颈,大大节省了数据传输时间.
Scala语言的简洁的特点,所以,Spark非常合适做机器学习的工作中频繁的迭代计算.RDD可以从本地数据集中通过输入转换产生,也可以使用已保存的RDD,也可以从别的RDD转换而来,需要使用时,可以把RDD缓存在内存中(如果内存不够大,会自动保存到本地).
RDD通过血统来实现容错机制,每一次转换,系统会保存转换日志,如果RDD出现故障,系统会根据转换日志重建RDD.
Lineage:利用内存加快数据加载在众多的其它的In-Memory类数据库或Cache类系统中也有实现,Spark的主要区别在于它处理分布式运算环境下的数据容错性(节点实效/数据丢失)问题时采用的方案。为了保证RDD中数据的鲁棒性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。
相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据变换(Transformation)操作(filter, map, join etc.)行为。
当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
总之,Spark的核心思路就是将数据集缓存在内存中加快读取速度,同时用lineage关联的RDD以较小的性能代价保证数据的鲁棒性。
正如其目标scope,Spark适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。
快在哪里?
使用内存缓存数据集快在以下几个方面:首先是磁盘IO,其次数据的序列化和反序列化的开销也节省了,最后相对其它内存数据库系统,粗颗粒度的内存管理机制减小了数据容错的代价(如典型的数据备份复制机制)--------------------前面也有提到!
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









