




 本文介绍了如何使用Python、PyCharm和Scrapy框架搭建爬虫项目。详细阐述了Scrapy的组件及其工作流程,包括引擎、调度器、下载器、爬虫和管道等。接着,讲解了搭建爬虫的步骤,如安装Python和Scrapy,创建项目,定义items、中间件、pipelines和spiders,并展示了运行爬虫的命令。
本文介绍了如何使用Python、PyCharm和Scrapy框架搭建爬虫项目。详细阐述了Scrapy的组件及其工作流程,包括引擎、调度器、下载器、爬虫和管道等。接着,讲解了搭建爬虫的步骤,如安装Python和Scrapy,创建项目,定义items、中间件、pipelines和spiders,并展示了运行爬虫的命令。
Python+Pycharm +Scrapy搭建爬虫项目
Scrapy简介:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
Scrapy框架的工作流程图如下:
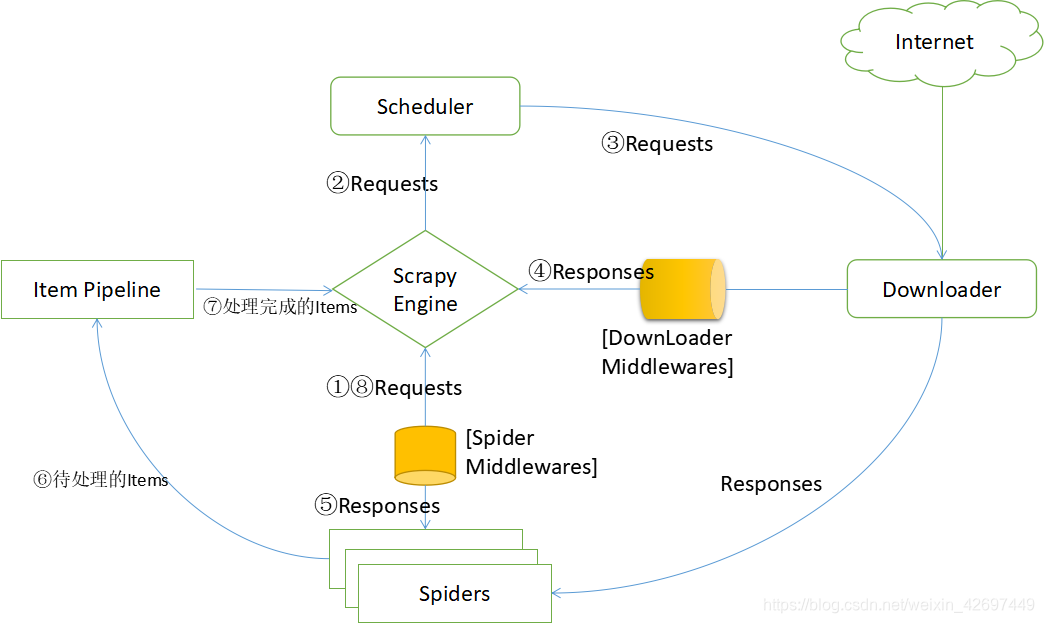
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
Scheduler(调度器):负责接收engine发送过来的Request请求并按照一定的方式进行整理排列,入队,当engine需要时,交还给engine
Downloader(下载器):负责下载engine 发送的所有Requests请求,并将其获取到的Responses交还给Engine,由Engine交给Spider处理
Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给engine,将URL提交给engine,再次进入Scheduler
Item Pipeline(管道):负责处理Spider中获取的Item,并经行后期处理(详细分析、过滤、存储等)的地方
Downloader Middlewares(下载中间件):自定义扩展下载功能组件,可以进行服务器代理等设置
Spider Middlewares(Spider中间件):可以自定义扩展和操作engine和Spider中间 通信的功能组件(比如进入Spider 的Responses,和从Spider出去的Requests)
一、准备工作
1.安装python3.x
2.下载PyCharm Community
3.安装Scrapy:安装好Python后,在cmd中输入以下命令 pip install scrapy
二、搭建步骤
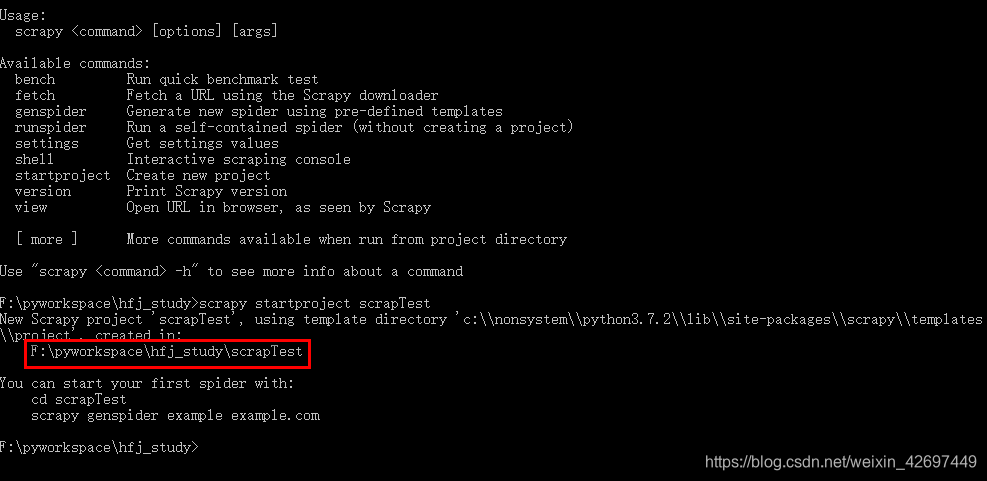
1.创建一个爬虫项目:通过scrapy startproject命令创建
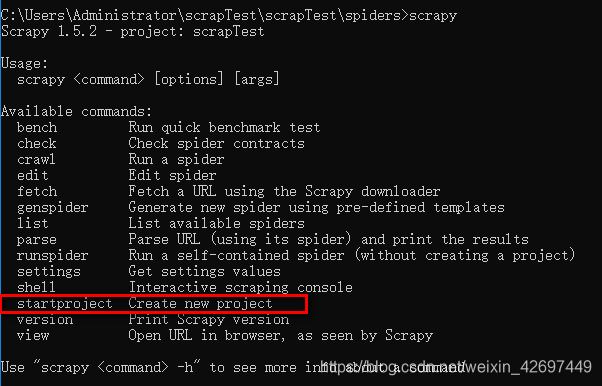
在cmd中运行命令:scrapy, 出现下图命令说明
执行 scrapy startproject [项目名],会在当前目录创建一个Scrapy项目
查看创建的scrapy项目的目录结构如下(拿以下项目举例):
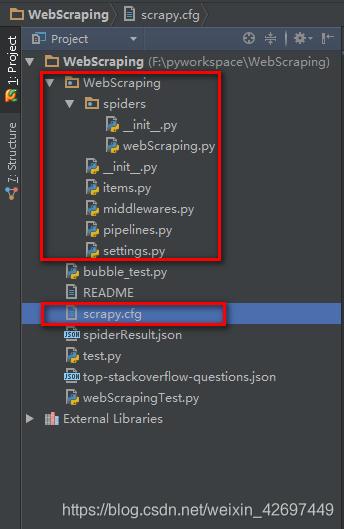
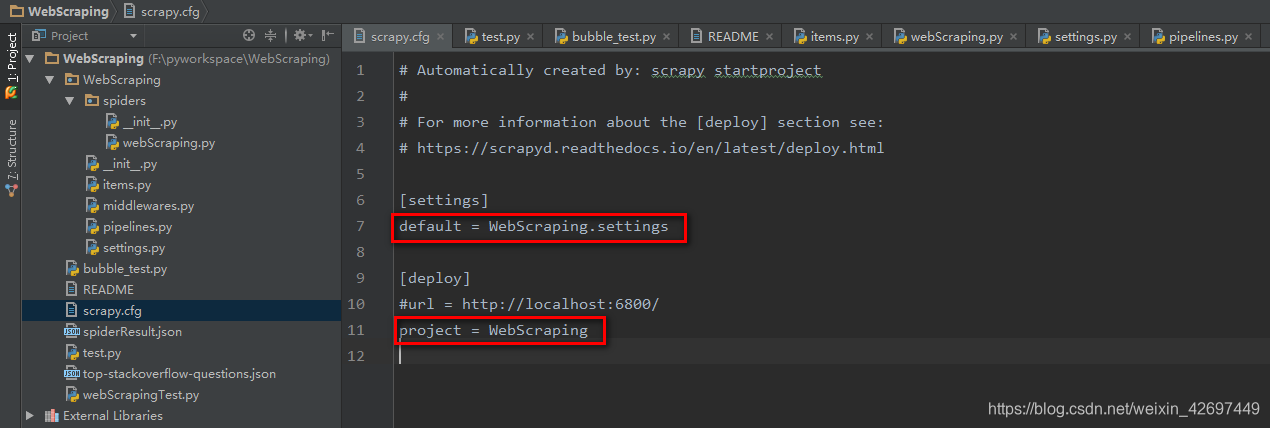
①WebScraping项目根目录下包括一个同名的WebScraping包和一个scrapy.cfg配置文件;其中scrapy.cfg配置文件内容如下:
指定该scrapy项目的setting文件为WebScraping包下的settings.py文件
②scrapTest模块下又包含了items、middlewares、pipelines、settings模块以及spider包
(1) items模块中定义了items类,各items类必须继承scrapy.Item;通过scrapy.Field()定义各Item类中的类变量
import scrapy
class StockQuotationItem(scrapy.Item):
'''
'''
order=scrapy.Field()
symbol = scrapy.Field()
instrument_name = scrapy.Field()
price=scrapy.Field()
pchg = scrapy.Field()
chg = scrapy.Field()
speed_up = scrapy.Field()
turnover = scrapy.Field()
QR = scrapy.Field()
swing = scrapy.Field()
vol = scrapy.Field()
floating_shares = scrapy.Field()
floating__net_value=scrapy.Field()
PE = scrapy.Field()
(2) middlewares模块中定义了各中间件类,包括SpiderMiddleWares、DownloadMiddleWares等
(3) pipelines模块,用于处理spider中获取的items(将获取的items保存至文件或者数据库等):
Pipeline类必须实现process_item()方法
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class WebScrapingPipeline(object):
def __init__(self):
self.f= open('spiderResult.json','wb')
def process_item(self, item, spider):
result=json.dumps 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4790
4790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









