







Python 内存管理机制
python 作为一门高级语言,自带内存管理机制,调用相关变量时,无需实现声明,变量无需指定类型,python 解释器会帮你自动回收,这一切都由python内存管理器承担了复杂的内存管理工作。
Python中的内存管理机制——Pymalloc
主要实现方式:
- 针对小对象,就是大小小于256kb时,pymalloc会在内存池中申请内存空间
- 针对大于256kb,会执行new/malloc行为来申请新的内存空间
python 内存池(memory pool)
特点:
-
内存池的作用就是预先在内存中申请一定数量的,大小相等的内存块留作备用,当有新的内存需求时,就优先从内存池中分配给这个需求。
-
减少内存碎片化,提升效率
当创建大量消耗小内存的对象时,频繁调用new/malloc 会导致大量的内存碎片,导致效率降低。
工作机制:
结构图:
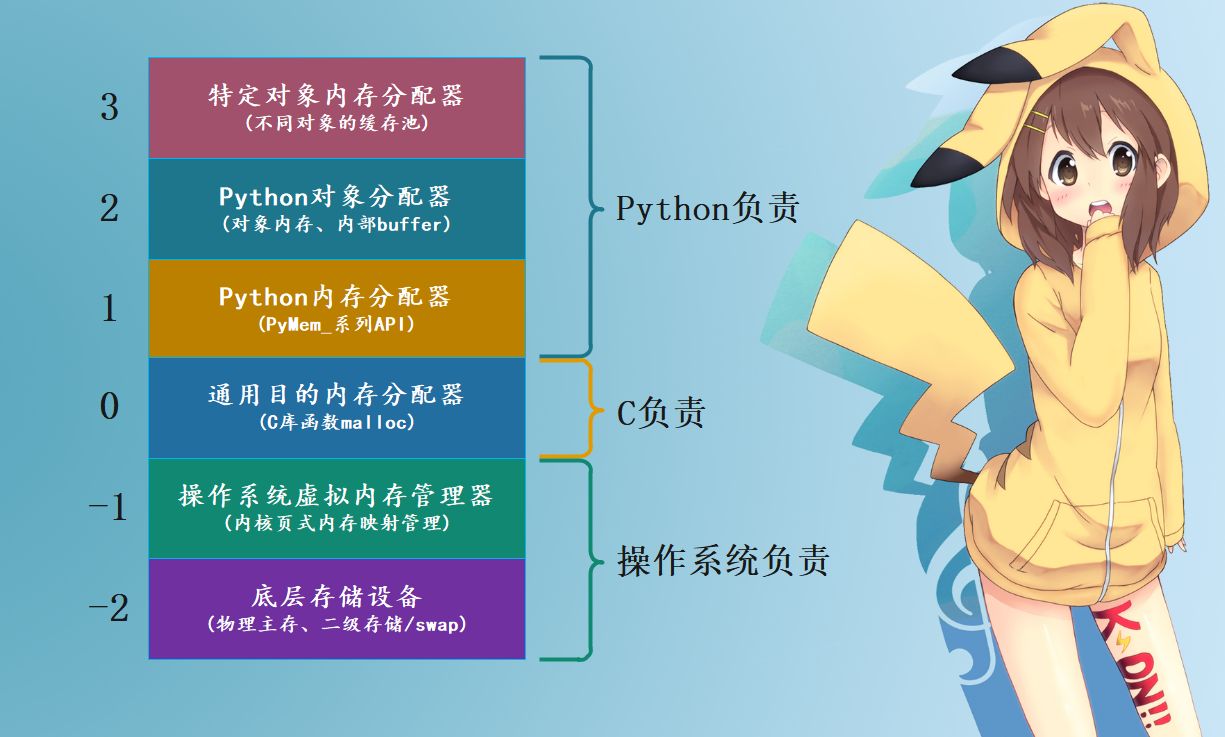
-
python 的对象管理主要位于 Level + 1 ~ Level +3 层
-
Level + 3 特定对象内存分配器:对于python内置的对象(int,dict)都有独立的私有内存池,对象之间的内存池不共享,即int释放的内存,不会被分配给float使用
-
Level + 2层 python 对象分配器:当申请的内存大小小于256KB时,内存分配主要由Python对象分配器(python’s object allocator)实施
-
Level + 1层 Python内存分配器 :当申请的内存大小大于256KB时,由Python 原生的内存分配器进行分配,本质上是调用C标准库中的malloc/readlloc等函数
关于释放内存方面,当一个对象的应用计数变为0时,Python 就会调用它的析构函数(
__del__)。调用析构函数并不意味着最终一定会调用free来释放内存空间,会导致频繁地申请、释放内存空间会使得Python的执行效率大打折扣。因此在析构时也采用了内存池机制,从内存池申请到的内存会被归还到内存池中,以避免频繁地申请和释放动作。
垃圾回收机制
Python的垃圾回收机制采用引用计数机制为主,标记-清除和分代回收机制为辅的策略。
-
引用计数
每个对象都会维护一个ob_ref——用来记录当前对象被引用的次数,也就是来追踪到底有多少应用指向了这个对象,
对象的引用计数器+1
- 对象被创建 a = [1,23,4]
- 对象被引用 b = a
- 对象被作为参数,传到函数中 func(a)
- 对象作为一个元素,存储到容器中list = [1,a,2]
对象的引用计数-1
- 对象的应用被显示销毁时,del a
- 对象的引用别名被赋予新的对象,a=26
- 一个对象离开它的作用域,例如func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(全局变量不变)
- 将该元素从容器中删除时,或者容器被销毁
当指向对象的内存的引用计数为0时,该内存会被Python虚拟机销毁
优点:1. 高效 2. 实时性,一旦没有引用,内存就直接释放了 3. 对象有确定的生命周期 4. 易于实现。
缺点:1. 维护引用计数消耗资源。2. 无法解决循环引用问题-
-
标记清除
针对循环引用的情况,这些对象的引用计数都是1而不是0 ,python的引用计数的算法不能够处理互相指向自己的对象。事实上,当你的python程序运行的时候它将建立一定数量的”浮点数垃圾“,Python 的GC不能够处理未使用的对象因为引用计数的值不会到零。
关于python 引用Generational GC 算法
[标记清除(Mark-Sweep)] 算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。主要针对一些容器对象,比如list、dict、tuple、instance等,对于字符串和数值对象是不可能造成循环引用的问题的。python对象都分为两部分: PyObject_HEAD + 对象本身数据
其分为两个阶段:1. 第一阶段是标记阶段,GC会把所有的[活动对象]打上标记,第二阶段是把那些没有标记的对象[非活动对象]进行回收。
活动对象和非活动对象的判定:
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
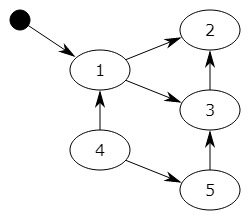
其中:1,2,3 为活动对象,4,5为非活动对象,会被回收
关于引用计数和标记清除的底层可以参考:https://blog.csdn.net/xiongchengluo1129/article/details/80462651















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









