







DAT
title: Vision Transformer with Deformable Attention
论文:https://arxiv.org/abs/2201.00520
代码:https://github.com/LeapLabTHU/DAT
Introduction
在ViT中使用密集的注意力会导致内存和计算成本过高,特征会受到超出兴趣区域的不相关部分的影响。另一方面,在PVT或Swin Transformer 中采用的稀疏注意里力是数据不可知的,可能会限制建模长期关系的能力。
为了缓解这些问题,**本文提出了一种新的可变形的自注意力模块,该模块以数据依赖的方式选择了自注意力中的key和value对的位置。**这种灵活的方案使自注意力模块能够聚焦于相关区域并捕获更多信息。在此基础上,提出了一种可变形注意力Transformer(Deformable Attention Transformer)模型,该模型具有可变形注意力,适用于图像分类和密集预测任务。大量的实验表明,本文的模型在综合基准上取得了持续改进的结果。
本文提出了一种简单有效的可变形的自注意力模块,并在此模块上构造了一个强大的Pyramid Backbone,即可变形的注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集的预测任务。
标榜DCN能够应用再Transformer中,作者采用了SWIN+offset卷积的结合。
**不同于DCN,在整个特征图上针对不同像素学习不同的offset,作者建议学习几组query无关的offset,将key和value移到重要区域,这是针对不同query的全局注意力通常会导致几乎相同的注意力模式的观察结果。**这种设计既保留了线性空间的复杂性,又为Transformer的主干引入了可变形的注意力模式。
具体来说:
- 对于每个注意力模块,首先将参考点生成为统一的网格,这些网格在输入数据中是相同的;
- 然后,offset网络将query特征作为输入,并为所有参考点生成相应的offset。这样一来,候选的key /value被转移到重要的区域,从而增强了原有的自注意力模块的灵活性和效率,从而捕获更多的信息特征。

Deformable Attention Transformer

Preliminaries
首先在最近的Vision Transformer中回顾了注意力机制。以Flatten特征图 x ∈ R N × C x\in R^{N\times C} x∈RN×C为输入,M头自注意力(MHSA)块表示为:

其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅)表示softmax函数, d = C / M d=C/M d=C/M为每个Head的尺寸。 z ( m ) z(m) z(m)表示第 m m m个注意力头的嵌入输出, q ( m ) , k ( m ) , v ( m ) ∈ R N × d q(m),k(m),v(m)\in R^{N\times d} q(m),k(m),v(m)∈RN×d分别表示query,key,value嵌入。
W q , W k , W v , W o ∈ R C × C W_{q},W_{k},W_{v},W_{o}\in R ^{C \times C} Wq,Wk,Wv,Wo∈RC×C是投影矩阵。为了建立一个Transformer Block。通常采用一个具有2个线性变换和一个GELU激活的MLP块来提供非线性激活。
通过归一化层和shortcuts,第一个Transformer Block被表示为:

其中LN表示归一化层。
Deformable Attention
在DCN中,特征图上的每个元素分别学习其offset,其中H×W×C特征图上的3×3可变形卷积的空间复杂度为 9 H W C 9HWC 9HWC。如果直接在自注意力模块应用相同的机制,空间复杂度将急剧上升到 N q N k C N_{q}N_{k}C NqNkC, N q N_{q} Nq、 N k N_{k} Nk为query和key的数量,通常有相同的尺度特征图大小 H W HW HW,带来近似双二次复杂度。
虽然Deformable DETR通过在每个检测头设置更少的key( N k = 4 N_{k}=4 Nk=4)来减少这个计算开销,但是,在Backbone中,这样少的key是次要的,因为这样的信息丢失是不可接受的。
同时,在先前的工作中的观察显示,不同的query在视觉注意力模型中具有相似的注意力图。因此,选择了一个更简单的解决方案,为每个query共享移动的key和value以实现有效的权衡。
具体来说,本文提出了Deformable Attention,在特征映射中重要区域的引导下,有效地建模Token之间的关系。这些集中的regions由offset网络从query中学习到的多组Deformable sampling点确定。采用双线性插值对特征映射中的特征进行采样,然后将采样后的特征输入key投影得到Deformable Key。
Deformable attention module

给定输入特征图 x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C,**生成一个点 p ∈ R H c × W G × 2 p\in R^{H_{c}\times W_{G} \times 2} p∈RHc×WG×2的统一网格作为参考。具体来说,网格大小从输入的特征图大小降采样一个系数 r r r, H G = H / r H_{G} =H/r HG=H/r, W G = W / r W_{G}=W/r WG=W/r。**参考点的值为线性间隔的2D坐标 ( 0 , 0 ) , . . . , ( H G − 1 , W G − 1 ) (0,0),...,(H_{G}-1,W_{G}-1) (0,0),...,(HG−1,WG−1),然后根据网格形状 H G × W G H_{G}\times W_{G} HG×WG将其归一化为范围 [ − 1 , 1 ] [-1,1] [−1,1],其中 ( − 1 , 1 ) (-1,1) (−1,1)表示左上角, ( + 1 , + 1 ) (+1,+1) (+1,+1)表示右下角。
为了获得每个参考点的offset,将特征映射线性投影到query token q = x W q q=xW_{q} q=xWq ,然后输入一个轻量子网络 θ o f f e s t ( ⋅ ) \theta_{offest(\cdot)} θoffest(⋅),生成偏移量 Δ p = θ o f f e s t ( ⋅ ) \Delta_{p}=\theta_{offest(\cdot)} Δp=θoffest(⋅)。为了稳定训练过程,这里用一些预定义的因子 s s s来衡量的振幅 Δ p \Delta p Δp,以防止太大的offset.然后在变形点的位置进行特征采样,作为key和value,然后是投影矩阵:

k ~ \tilde {k} k~和 v ~ \tilde v v~分别表示deformed key嵌入和value嵌入。具体来说,将采样函数 φ ( ⋅ , ⋅ ) φ(\cdot,\cdot) φ(⋅,⋅)设置为双线性插值,使其可微:

其中 g ( a , b ) = m a x ( 0 , 1 − ∣ a − b ∣ ) g(a,b)=max(0,1-|a-b|) g(a,b)=max(0,1−∣a−b∣)和 ( r x , r y ) (r_{x},r_{y}) (rx,ry)索引了 z ∈ R H × W × C z\in R^{H\times W\times C} z∈RH×W×C的所有位置。由于 g g g只在最接近 ( p x , p y ) (p_{x},p_{y}) (px,py)的4个积分点上不为零。

Offset generation
采用一个子网络进行Offset的生成,它分别消耗query特征和输出参考点的offset值。考虑到每个参考点覆盖一个局部的 s × s s×s s×s区域(×是偏移的最大值),生成网络也应该有对局部特征的感知,以学习合理的offset。

因此,将子网络实现为2个具有非线性激活的卷积模块。所示输入特征首先通过一个5×5的深度卷积来捕获局部特征。然后,采用GELU激活和1×1卷积得到二维偏移量。同样值得注意的是,1×1卷积中的偏差被降低,以缓解所有位置的强迫性偏移。
Offset groups
为了促进变形点的多样性,在MHSA中遵循类似的范式,并将特征通道划分为G组。每个组的特征分别使用共享的子网络来生成相应的偏移量。在实际应用中,注意力模块的Head数M被设置为偏移组G大小的倍数,确保多个注意力头被分配给一组deformed keys 和 values 。
Deformable relative position bias
相对位置偏差对每对query和key之间的相对位置进行编码,通过空间信息增强了普通的注意力。考虑到一个形状为 H × W H×W H×W的特征图,其相对坐标位移分别位于二维空间的 [ − H , H ] [−H,H] [−H,H]和 [ − W , W ] [−W,W] [−W,W]的范围内。在Swin Transformer中,构造了相对位置偏置表 B ^ ∈ R ( 2 H − 1 ) × ( 2 W − 1 ) \hat B\in R^{(2H-1)\times (2W-1)} B^∈R(2H−1)×(2W−1),通过对表的相对位移进行索引,得到相对位置偏置 B B B。由于可变形注意力具有连续的key位置,计算在归一化范围内的相对位移 [ − 1 , + 1 ] [−1,+1] [−1,+1],然后在连续的相对偏置表 B ^ \hat B B^中插值 ϕ ( B ^ , R ) \phi(\hat B,R) ϕ(B^,R),以覆盖所有可能的偏移值。
Model Architectures

在网络架构方面,模型“可变形注意变换器”与PVT等具有相似的金字塔结构,广泛适用于需要多尺度特征图的各种视觉任务。首先对形状为 H × W × 3 H×W×3 H×W×3的输入图像进行 4 × 4 4×4 4×4不重叠的卷积嵌入,然后进行归一化层,得到 H / 4 × W / 4 × C H/4×W/4×C H/4×W/4×C 的patch嵌入。为了构建一个层次特征金字塔,Backbone包括4个阶段,stride逐渐增加。在2个连续的阶段之间,有一个不重叠的2×2卷积与stride=2来向下采样特征图,使空间尺寸减半,并使特征尺寸翻倍。
- 在分类任务中,首先对最后一阶段输出的特征图进行归一化处理,然后采用具有合并特征的线性分类器来预测logits。
- 在目标检测、实例分割和语义分割任务中,DAT扮演着Backbone的作用,以提取多尺度特征。
这里为每个阶段的特征添加一个归一化层,然后将它们输入以下模块,如目标检测中的FPN或语义分割中的解码器。
在DAT的第三和第四阶段引入了连续的Local Attention和Deformable Attention Block。特征图首先通过基于Window的Local Attention进行处理,以局部聚合信息,然后通过Deformable Attention Block对局部增强token之间的全局关系进行建模。这种带有局部和全局感受野的注意力块的替代设计有助于模型学习强表征
由于前两个阶段主要是学习局部特征,因此在这些早期阶段的Deformable Attention不太适合。
此外,前两个阶段的key和value具有较大的空间大小,大大增加了Deformable Attention的点积和双线性插值的计算开销。因此,为了实现模型容量和计算负担之间的权衡,这里只在第三和第四阶段放置Deformable Attention,并在Swin Transformer中采用Shift Window Attention,以便在早期阶段有更好的表示。

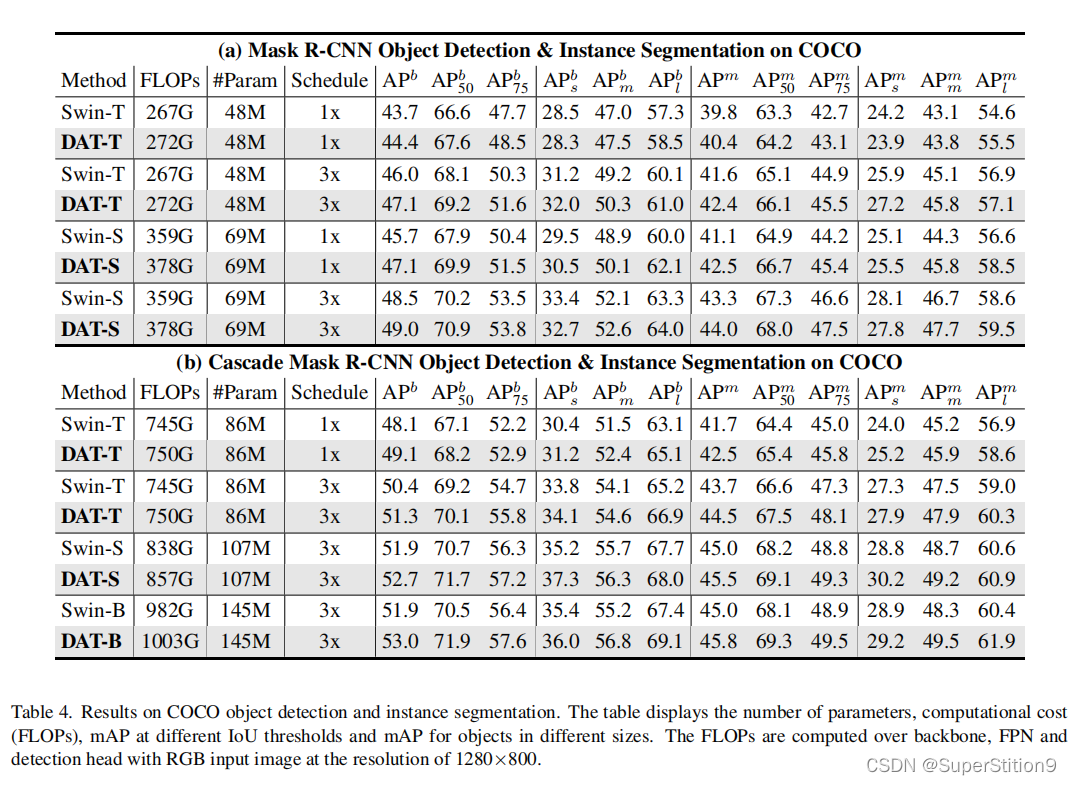
Experiment

















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









