






1.首先我们拿一幅8*8的图,window size(窗口大小)设置为4*4,本文中每个不同的颜色对应不同的区域块。
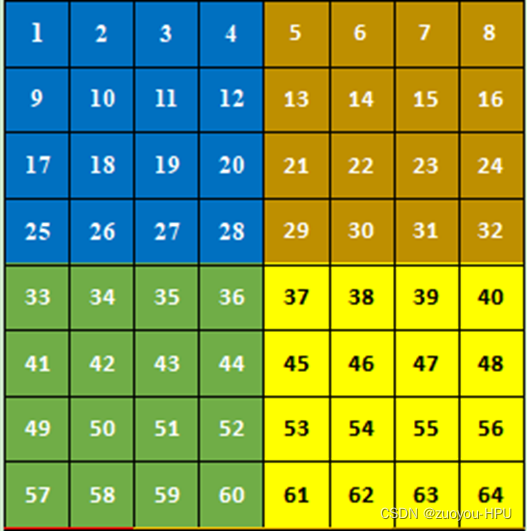
将一幅8*8的图片,运用4*4的window size 分为四个窗口,在swin transformer第一层的W-MSA即上图的四块自身进行MSA(Multi head self attention),这个比较好理解,重点是在第二层的SW-MSA。
2.SW-MSA(shift window Multi head self attention)
当运用window size = 4*4 ,siift window = 2*2时,window窗口向左移位2个像素的同时向下移位2个像素,图像分块将从原本的4块,变成了9块,如下图所示,为了减少快增多从而导致计算量的增大,本文运用了可谓是非常大的一个亮点,SW-MSA。
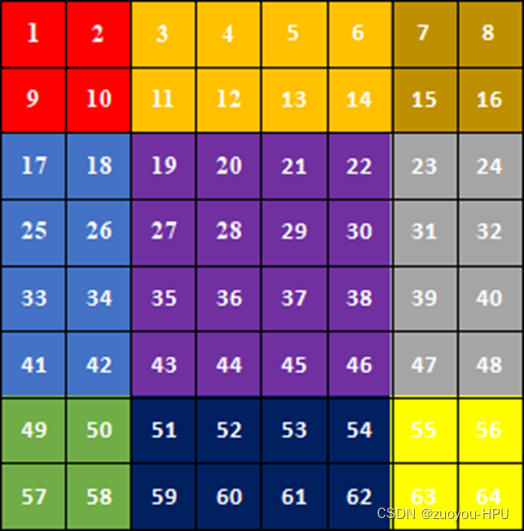
可以看到此时图像被分成了9块,为了恢复成4块,文章运用torch.roll函数将第0维和第1维的前两维数据进行移位。
torch.roll(x, (-1 , -1),(1 , 1))#将第一维数据向前移动两个维度
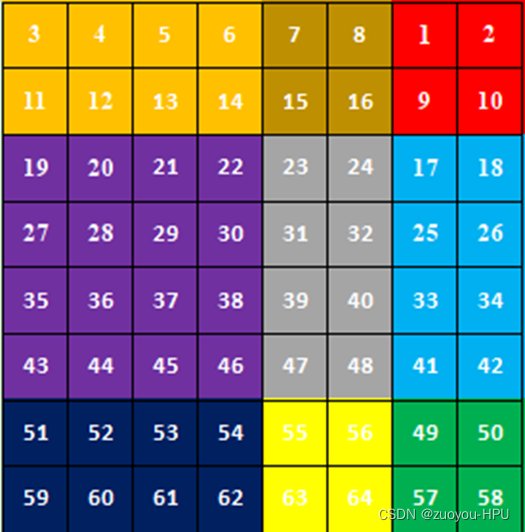
torch.roll(x, (-1 , -1),(0 , 0))#第0维数据向前移位两个维度
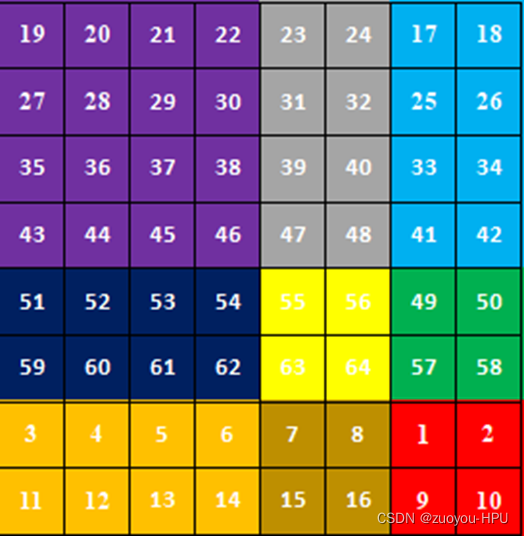
此时将移位后的再当作4块,

1是一个窗口,2和3组合成一个窗口,4和7组合成一个窗口,5、6、8、9组合成一个窗口,分别进行四个窗口的自注意力计算。
3.新生成的四个窗口,在每个窗口再做自己窗口的自注意力机制。
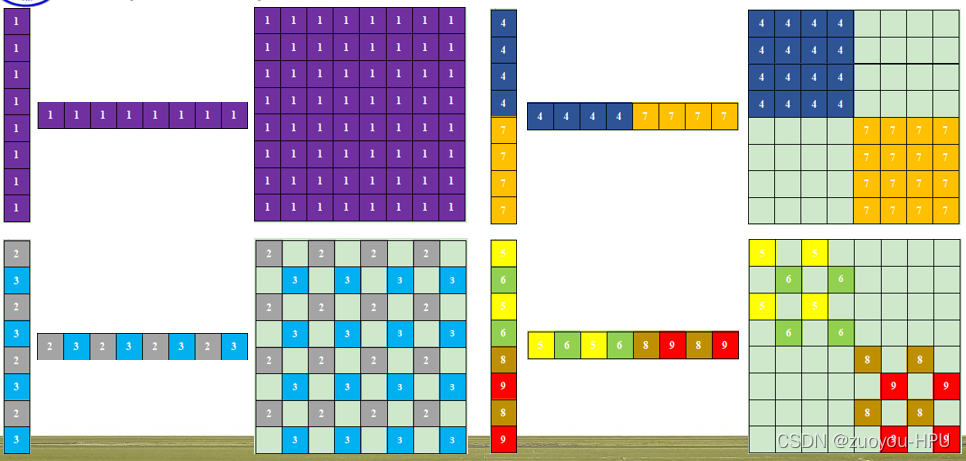
第一个窗口对1做自注意力机制,第二个窗口的4和7只对自己做自注意力机制,填充的是对应自注意力,未填充的是4和7,7和4的注意力机制,我们将它mask掉,不进行向下计算,剩余两个模块类似的作用,填充的代表自注意力,未填充的是不同模块的注意力,选择mask掉。
至此,这就是W-MSA和SW-MSA的区别注意力机制。
感谢大家,多多交流。


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











