






特征选择问题
特征选择,就是选择数据中能够具有分类能力的特征,在决策树中是重要的理论基础。本文章侧重于考虑决策树中的特征选择准则,并且进行手算几个准则,如信息增益,信息增益比和Gini系数。特征选择方法是,对于训练数据集D,计算其每个特征的准测系数,并且比较大小,选择最优的特征。
熵(entropy)
熵,来源于热力学。在信息论和概率统计中,熵是表示随机变量不确定性的度量。
假设X是一个取有限个值得离散随机变量,其概率分布为: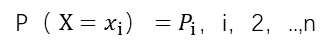
则随机变量X的熵定义为:
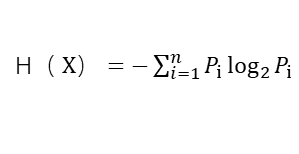
熵只依赖于X分布,而与X的取值无关。当熵取最大值时,随机变量不确定性最大。
条件熵
条件熵表示在已知随机变量X的条件下随机变量Y的不确定性,定义为X给定条件下Y的条件概率分布的熵对X的数学期望。看公式比较容易理解,
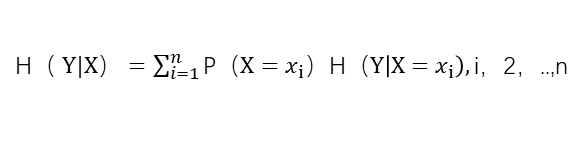
注意,当熵和条件熵的概率由数据中统计出来的,所对应的熵和条件熵分别称为经验熵和条件经验熵(empirical conditional entropy)
信息增益
信息增益(information gain)表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。信息增益大的特征具有更强的分类能力。
如特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D),与特征A给定条件下D的经验条件熵H(D|A)之差,如下:
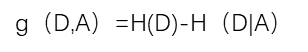
信息增益比
上述信息增益熵存在偏向于取值较多的特征问题,使用信息增益比可以对这个问题进行校正。信息增益比公式为:
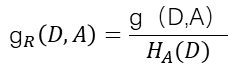
其中,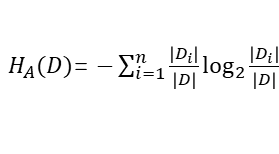
n是特征A取值个数
信息增益和信息增益比区别
首先,从公式上,我们很明显可以发现是不一样的。从理论上,很多资料说,以信息增益作为划分数据集的特征,存在偏向于选择取值较多的特征的问题,所以使用信息增益比。
这里,按照个人的理解也补充一下,如果一个特征取值过多,那么当每个特征取值对应的样本都是选择了一个类别,(比如,下面我做的手算中,信贷情况,非常好都归属于“是”,这样在计算信息增益时会发现,条件熵都变成0 了,那么信息增益肯定就会高。最后的结果,决策树会选择这个特征作为节点,但是这种切分没有意义,这个节点很可能成为叶节点。因此利用信息增益/数据关于特征A的熵,防止这种切分的出现。这里再解释一下,就是说,如果特征A取值过多,A的不确定性越大,那么A的经验熵就会大,就可以中和上述的情况发生了。
基尼指数(Gini)
对于给定样本集合D,其基尼指数为:
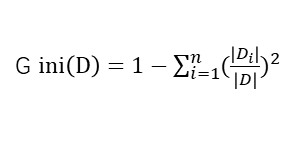
其中,Di为D中属于第i类的样本子集,N为类的个数。公式的推导和利用照例看手算推导过程。
小结
1、在决策树算法中,最优特征选择准测,ID3使用信息增益,C4.5使用信息增益率,CART使用Gini。
2、在选择最优特征计算中,选取信息增益最大值的特征作为最优特征节点,选取信息增益率最大值的特征作为最优特征节点,选取Gini系数最小值的特征作为最优特征节点。
手算过程
手算环节中,包括了信息增益的计算以及信息增益率的计算,数据参考了李航版统计学中的例题。
题目
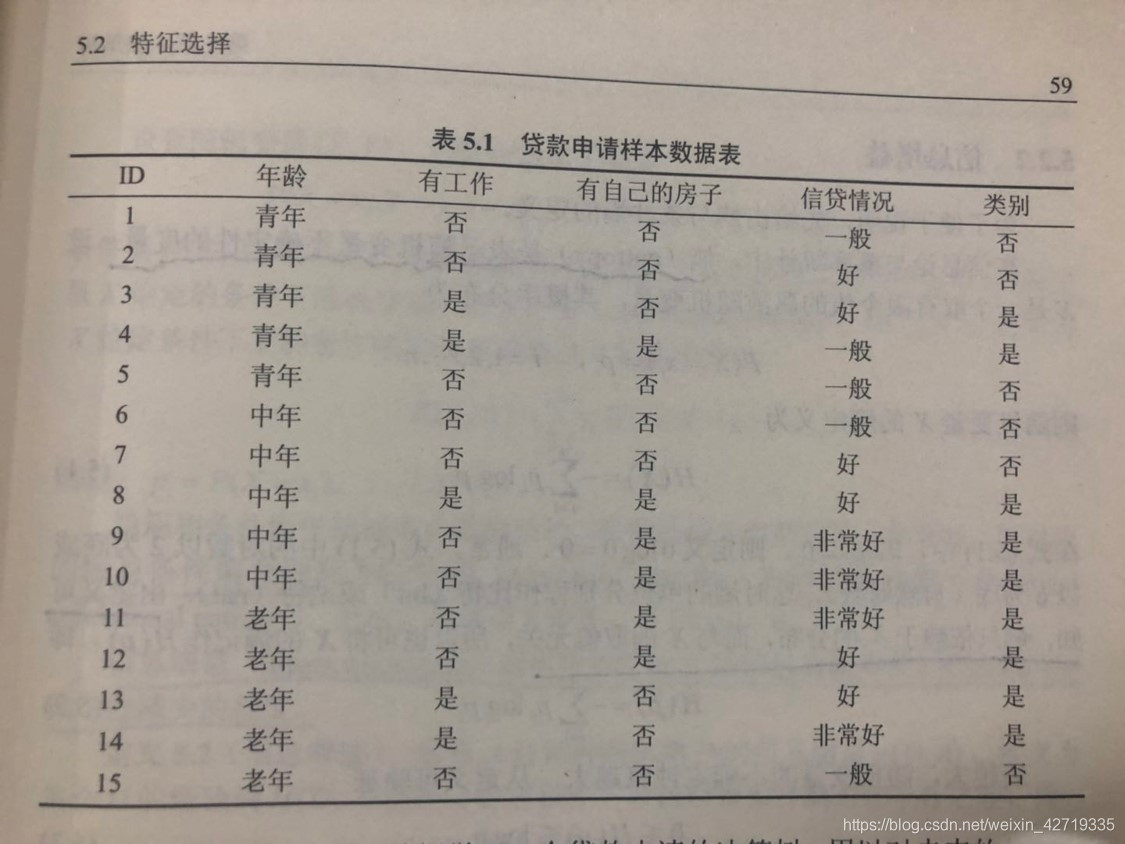
求解:
在求解过程中,信息增益率我省略了结果的计算,Gini系数中我只计算了一个特征的Gini系数。不过可以参考进行剩下的计算了。




最后,如果大家发现有不正确的地方记得联系我修正哈,互相学习,互相学习。
参考书籍:
李航版统计学习方法;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









