






 本文提出CodeRetriever模型,采用单峰和双峰对比学习方案,通过最小化对比损失优化编码器。利用CodeSearchNet语料库训练,构建代码 - 文档、代码 - 注释、代码 - 代码正样本对。实验表明,该模型在多个代码搜索任务上达先进水平,在低资源和跨语言场景表现良好。
本文提出CodeRetriever模型,采用单峰和双峰对比学习方案,通过最小化对比损失优化编码器。利用CodeSearchNet语料库训练,构建代码 - 文档、代码 - 注释、代码 - 代码正样本对。实验表明,该模型在多个代码搜索任务上达先进水平,在低资源和跨语言场景表现良好。
CodeRetriever: Large-scale Contrastive Pre-training for Code Search(用于代码搜索的大规模对比预训练)
文章地址:https://arxiv.org/abs/2201.10866
代码仓库:https://github.com/microsoft/ AR2/tree/main/CodeRetriever.
摘要
在本文中,我们提出了CodeRetriever模型,该模型通过大规模的代码——文本对比预训练来学习功能级代码语义表示。我们在CodeRetriever中采用了两种对比学习方案:单峰对比学习和双峰对比学习。对于单峰对比学习,我们设计了一种无监督学习方法,根据文档和函数名构建语义相关的代码对。对于双峰对比学习,我们利用代码的文档和内嵌注释来构建代码——文本对。两个对比目标都可以充分利用大规模代码语料库进行预训练。大量的实验结果表明,CodeRetriever在11个领域/语言特定的代码搜索任务上实现了新的最先进的技术,比现有的代码预训练模型有显著的改进,具有不同代码粒度(函数级、代码片段级和语句级)的6种编程语言。这些结果证明了CodeRetriever的有效性和鲁棒性。
1 前言
代码搜索旨在检索给定自然语言查询的功能相关代码,以提高开发人员的生产力(Parvez et al.,2021;侯赛因等人,2019)。最近的研究表明,代码预训练技术,如CodeBERT(冯等,2020)和GraphCodeBERT(郭等,2021),可以通过使用大规模代码语料库的自我监督预训练来显著提高代码搜索性能(侯赛因等,2019)。然而,现有的代码预训练方法通常采用(屏蔽)语言建模作为训练目标,其目标是学习在给定的代码上下文中预测(屏蔽的)标记(冯等,2020;郭等,2021;艾哈迈德等人,2021;王等,2021b)。然而,由于两个原因,这种基于标记的方法通常会导致糟糕的代码语义表示。**第一个是各向异性表示问题。**如(李等,2020)中所讨论的,令牌级自训练方法导致高频令牌的嵌入聚集并主导表示空间,这极大地限制了长尾低频令牌在预训练模型中的表达能力。因此,各向异性的表示空间导致了较差的函数级代码语义表示(李等人,2020)。在编程语言中,令牌不平衡的问题甚至比自然语言更严重。例如,常见的关键字和运算符,如“=”、“{”和“}”,在Java代码。**第二个是跨语言表征问题。**广泛使用的CodeSearchNet语料库(Husain等人,2019年)包含来自Python、Java等六种不同编程语言的代码。由于具有混合编程语言的代码很难出现在相同的上下文中,因此对于预训练的模型来说,学习具有相同功能但使用不同编程语言的代码的统一语义表示是具有挑战性的。
为了解决这些限制,我们提出了CodeRetriever模型,专注于学习函数级代码表示,特别是针对代码搜索场景。CodeRetriever模型由文本编码器和代码编码器组成,代码编码器将文本/代码编码成单独的密集向量。代码和文本(或代码和代码)之间的语义相关性通过密集向量之间的相似性来衡量(Karpukhin等人,2020b黄等,2013;沈等,2014)。
在CodeRetriever的训练中,通过最小化两种类型的对比损失来优化代码/文本编码器:1。单峰对比损失,鼓励模型将具有相似功能的代码在表示空间中推得更近。为了估计两个代码在语义上是否接近,模型需要基于给定的代码进行推理并理解其语义。2.双峰对比损失,有助于模拟代码和文本之间的相关性。由于文档或注释包含丰富的代码语义信息,它可以鼓励模型从自然语言中学习更好的代码表示。

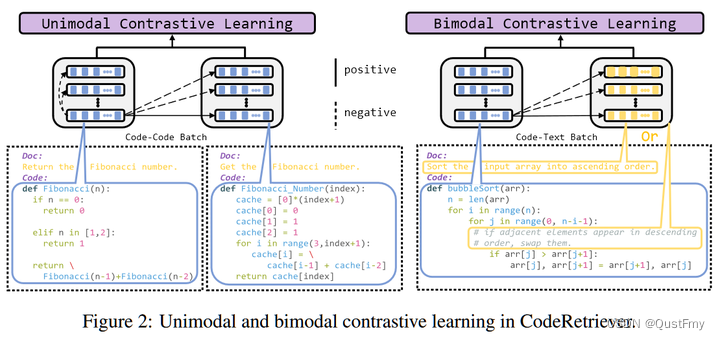
在这项工作中,我们采用常用的CodeSearchNet语料库(Husain等人,2019年)来训练CodeRetreiver。CodeSearchNet主要包含配对数据集(与文档配对的函数)和不成对数据集(只有一个函数)。配对数据集可直接用于双峰对比学习。对于CodeRetriver中的单峰对比学习,我们通过无监督语义引导的方法构建正编解码对。图1(a)显示了一个代码——代码示例:斐波那契数算法的两个实现。此外,生成的代码——代码对可以使用不同的编程语言,这可以减轻跨语言表示问题。为了进一步利用不成对数据和成对数据中的大规模代码,我们提取代码和内嵌注释对来增强CodeRetriever中的双峰对比学习。图1(b)显示了一个例子,表明内联注释(简称注释)也可以反映代码的语义和内部逻辑。具体来说,“如果相邻元素按降序出现,则交换它们”的底层逻辑对应于按升序对输入数组进行排序,这种细粒度的语义信息也有助于学习更好的代码表示。
通过对这些单峰和双峰对的对比,CodeRetriever可以1。更好地学习函数级代码语义表示,这可以缓解各向异性表示问题(高等,2021b颜等,2021);2.明确建模代码与不同编程语言的相关性,并将统一自然语言作为支点,以缓解跨语言表示问题。我们在11个代码搜索数据集上评估了CodeRetriever,这些数据集涵盖了6种编程语言、真实世界场景和不同粒度(函数级、代码片段级和语句级)的代码,结果表明CodeRetriever实现了新的最先进的性能。
2 相关工作
CodeSearchNet语料库(Husain等人,2019年)是最大的公开可用的代码数据集。语料库是从开源的非fork GitHub存储库中收集的,其中包含210万个配对数据(与文档配对的函数)和640万个不成对数据(仅函数)。
在文献中,代码搜索方法(Husain等人,2019;贾恩等人,2020;冯等,2020;郭等,2021)利用CodeSearchNet语料库中的成对codedocument数据集来训练用于语言到代码检索的连体编码器模型。然而,丰富的未标记代码语料库要么被简单地抛弃,要么被切断作为代码预训练语料库(冯等,2020;郭等,2021)。我们认为令牌级代码预训练目标没有显式学习函数级代码表示。因此,现有的代码预训练模型(Jain等人,2020;冯等,2020;郭等人,2021)对于代码搜索来说是次优的。
在这项工作中,我们提出了CodeRetriever来学习函数级代码语义表示。CodeRetriever用代码预训练模型(即GraphCodeBERT)初始化。双峰对比学习采用代码文档和代码注释配对数据,单峰对比学习采用代码代码配对数据。经过CodeRetriever的预训练,它可以服务于下游领域/语言指定的数据集。
2.1token级代码预训练
令牌级预训练模型已经广泛应用于编程语言中。Karampatsis和Sutton(2020)在JavaScript语料库上为程序修复任务预训练ELMo。卡纳德等人。(2020)使用大规模Python语料库对BERT进行预训练模型。C-BERT(Buratti et al.,2020)在C语言的许多存储库上进行了预训练,并在抽象语法树(AST)标记任务方面实现了显著改进。CodeBERT(Feng et al.,2020)通过屏蔽语言模型进行预训练,并在六种编程语言的文本——代码对上替换令牌检测任务。GraphCodeBERT(郭等,2021)介绍了基于CodeBERT的数据流信息。除了这些类似BERT的模型之外,CodeGPT(Svyatkovskiy等人,2020年)、PLBART(Ahmad等人,2021年)、CoTexT(Phan等人,2021年)和CodeT5(王等人,2021年b)分别基于、BART(Lewis等人,2019年)和T5(Raffel等人,2020年)进行代码生成任务的预训练。然而,令牌级目标导致了各向异性问题(郭等人,2022),并且与基于函数级表示的代码搜索存在差距。与这些工作不同,CodeRetriever利用对比学习框架来增强函数级表示。
2.2 代码对比学习
代码的对比学习最近,一些工作尝试在编程语言中使用对比学习,其关键是建立有效的正样本或负样本。ContraCode(Jain等人,2020年)和Corder(Bui等人,2021年)使用语义保留转换,如标识符重命名和死代码插入来构建正对。丁等人。(2021)开发bug注入来构建硬负对。SynCoBERT(王等,2021a)和Code-MVP(王等,2022)通过AST和CFG等程序的编译过程构建正对。然而,他们的方法通常生成与原始代码结构相似或变量名相同的正样本,其自然性和多样性受到手写规则的限制(李等,2022)。在CodeRetriever中,我们从代码-代码、代码-文档和代码-注释中构造正对。对于code-code,我们设计了一种基于真实世界代码的更加自然和多样的正对构造方法。
3 方法
在本节中,我们将介绍CodeRetriever的模型体系结构和训练目标.
CodeRetriever采用连体代码/文本编码器架构,将代码/文本表示为密集向量。设
E
c
o
d
e
(
⋅
;
θ
)
E_{code}(·;\theta)
Ecode(⋅;θ)和
E
t
e
x
t
(
⋅
;
ϕ
)
E_{text}(·;\phi)
Etext(⋅;ϕ)分别表示代码编码器和文本编码器。代码-代码对(c,c+)和文本代码对(t,c+)之间的语义相似性计算如下:
s
(
c
,
c
+
)
=
⟨
E
c
o
d
e
(
c
;
θ
)
,
E
c
o
d
e
(
c
+
;
θ
)
⟩
(
1
)
s
(
t
,
c
+
)
=
⟨
E
t
e
x
t
(
t
;
ϕ
)
,
E
c
o
d
e
(
c
+
;
θ
)
⟩
,
(
2
)
\begin{aligned}s(c,c^+)&=\left\langle E_{\mathsf{code}}(c;\theta),E_{\mathsf{code}}(c^+;\theta)\right\rangle(1)\\s(t,c^+)&=\left\langle E_{\mathsf{text}}(t;\phi),E_{\mathsf{code}}(c^+;\theta)\right\rangle,(2)\end{aligned}
s(c,c+)s(t,c+)=⟨Ecode(c;θ),Ecode(c+;θ)⟩(1)=⟨Etext(t;ϕ),Ecode(c+;θ)⟩,(2)
其中<,>表示余弦相似运算。
3.1 单峰对比学习
给定成对代码——代码训练样本(c,c+),单峰对比损失由以下公式给出:
L
u
n
i
=
−
ln
exp
(
τ
s
(
c
,
c
+
)
)
∑
c
′
∈
C
exp
(
τ
s
(
c
,
c
′
)
)
\mathcal{L}_{\mathrm{uni}}=-\ln\frac{\exp\left(\tau s(c,c^+)\right)}{\sum_{c^{\prime}\in\mathbb{C}}\exp\left(\tau s(c,c^{\prime})\right)}
Luni=−ln∑c′∈Cexp(τs(c,c′))exp(τs(c,c+))
其中τ是温度,为了简单起见,我们设τ=1;集合C由配对代码C+和通过批量负采样获得的N-1个不成对代码样本组成(Karpukhin等人,2020b)。特别是,一批可以由混合编程语言组成,这可以帮助预训练的模型学习具有不同编程语言的代码的统一语义空间。
3.2 双峰对比学习
给定一个成对的文本代码训练实例(t,c+),双峰对比损失定义为相同的方式:
L
b
i
=
−
ln
exp
(
τ
s
(
t
,
c
+
)
)
∑
c
′
∈
C
exp
(
τ
s
(
t
,
c
′
)
)
\mathcal{L}_{\mathrm{bi}}=-\ln\frac{\exp\left(\tau s(t,c^+)\right)}{\sum_{c^{\prime}\in\mathbb{C}}\exp\left(\tau s(t,c^{\prime})\right)}
Lbi=−ln∑c′∈Cexp(τs(t,c′))exp(τs(t,c+))
其中τ和C的定义与等式3中的定义相同。文本-代码批处理的代码还包括混合编程语言,这有助于调整不同编程语言和自然语言的语义空间。由于文档或注释反映了源代码的功能和关键语义信息,这样的正对可以帮助模型更好地理解代码的语义。
3.3 预训练总体目标
如图2所示,CodeRetreiver采用两种类型的文本到代码进行双峰对比训练,即代码文档和代码注释。因此,我们使用$\mathcal{L}_\mathrm{bi}^1$和$\mathcal{L}_\mathrm{bi}^2$分别表示代码文档和代码注释对比损失。CodeRetreiver的总体预培训目标是:
L
(
θ
,
ϕ
)
=
L
u
n
i
+
L
b
i
1
+
L
b
i
2
\mathcal{L}(\theta,\phi)=\mathcal{L}_{\mathrm{uni}}+\mathcal{L}_{\mathrm{bi}}^1+\mathcal{L}_{\mathrm{bi}}^2
L(θ,ϕ)=Luni+Lbi1+Lbi2
4 建立正样本对

4.1 代码-文档
源代码文档通常可以提供丰富的语义信息,高度描述代码的功能。例如,在图1(b)中,文档“按升序对输入数组进行排序。”清楚地总结了代码的目标,这可以帮助模型更好地理解代码。所以我们把代码c和它对应的文档t作为正对。这样,我们不仅可以帮助模型更好地理解代码,而且可以以统一的自然语言描述为支点,协调不同编程语言的表示。
4.2 代码-注释
与文档不同,行内注释广泛存在于不成对的代码中。如图1(b)所示,它可以反映代码的内部逻辑,并包含细粒度的语义信息,尽管有一定的噪声信号。因此,我们将代码注释视为正对,以进一步帮助模型学习更好的代码表示。在本节中,我们将介绍如何构建代码注释对。我们首先利用代码解析器(tree-sitter)将代码块分成两部分:纯代码和相应的行内注释。然后,我们执行如下后处理来过滤噪声配对样本,以获得代码注释语料库:
- 我们将带有连续行的注释合并成一个注释。这是受开发人员通常将一个完整的注释写成多行以使其更容易阅读的现象的启发,如图1(b)所示。
- 信息很少的注释被删除,包括:1)短于四个令牌;2)以“TODO”开头的注释;3)用于自动代码检查的注释,如“Linter”1.4)非文本注释,即注释代码。
- 删除语义信息很少的函数,如名称为“getter”、“setter”等的函数。
清理后,我们收集了大约190万个代码分解对。整个代码——文本语料库的详细统计数据见附录A
4.3 代码-代码
代码-代码配对数据集可以为模型提供明确的训练信号,以学习代码的语义表示。然而,从未标记的语料库中构建大规模和高质量的语义相关的代码对是具有挑战性的。对于一个特定的功能,有很多方法来实现它,并且产生的代码可以充满多样性。它们可以具有完全不同的逻辑、调用的库和标识符名称。即使对于经验丰富的开发人员来说,评估两个代码的语义相似度也是一项挑战和耗时的工作,注释成本高且不可扩展。尽管具有相同功能的两个代码可以有不同的实现,但是它们的文档或函数名可以非常相似,如图1(a)所示。受这一现象的启发,我们提出了以下无监督技术来收集大规模的代码到代码语料库。
第一步。通过处理函数名和文档来收集有噪声的代码-代码对。1)采用最近提出的无监督方法SimCSE(高等,2021b),用函数名语料库训练,得到“NameMatcher”模型;用文档语料库训练得到“DocMatcher”模型;“NameMatcher”和“DocMatcher”都是密集检索模型。例如,给定一个函数名,“NameMatcher”可以检索语料库中的前K个相关函数名。我们请读者参考其原始论文(高等,2021b)了解更多详情。2)对于语料库中的任何给定函数,我们使用“NameMatcher”通过函数名匹配来检索其相关函数。类似的方式也适用于“DocMatcher”,它通过匹配相应的文档来收集代码对。我们表示通过“DocMatcher”收集的代码对作为CDoc,并使用CName表示通过“NameMatcher”收集的代码对。我们只保留代码对,如果它们的检索分数(通过“NameMatcher”和“DocMatcher”)大于thresh老(0.75)。
第二步。用交叉模型去噪代码——代码对。从步骤1中收集的代码集CName和CDoc可能有噪声,尤其是对于CName,因为具有相同函数名的函数可能具有不同的功能。在这一步中,我们训练一个二元分类器模型,交叉模型(Mc),用于过滤噪声码——码对。1)我们将噪声较小的代码——代码对CDoc作为训练集来训练交叉模型Mc。它需要代码-代码对的连接作为输入,对于通过深度令牌交互预测它们的相关分数(范围从0到1)更加强大。在Mc的训练中,我们使用集合CDoc作为正训练实例,同时随机采样编解码对作为负实例。2)如果CDoc和CName的Mc预测分数小于某个阈值,我们删除它们中的代码——代码对。设C∫Name和C∫Doc是CName和CDoc的去噪子集。最终的代码——代码语料库是集合C∫Name和C∫Doc的联合。由于我们以自然语言为锚来获得C∫Name和C∫Doc,代码对可以具有不同的编程语言,并缓解了跨语言表示问题。我们分别在图3(a)和图3(b)中显示了步骤1和步骤2的过程。总体而言,收集的代码——代码语料库包含2340万对。我们在附录b、C和D中提供了关于构建代码——代码语料库的更详细的描述,涉及超参数和代码——代码对的详细跨语言统计。
5. 实验
为了公平比较,CodeRetriever采用了与之前作品相同的模型架构(冯等,2020;郭等,2021)。CodeRetriever共享代码编码器和文本编码器的参数。它包含12层Transformer model,隐藏尺寸为768,注意头为12。为了加速训练过程,我们用GraphCodeBERT发布的参数初始化CodeRetriever(郭等,2021)。我们在附录E中展示了更多的细节。
基准数据集
我们在几个代码搜索基准上评估CodeRetriever,包括CodeSearch(Husain等人,2019;郭等,2021),(陆等,2021),(黄等,2021),(尹等,2018),SO-DS(海曼和卡特塞姆,2020),(姚等,2018)。CodeSearch基准测试包含六个使用不同编程语言的数据集。Adv数据集规范化了开发/测试集中的方法名和变量名,这使得它更具挑战性。CoNaLa、SO-DS和StaQC是从stackoverflow问题中收集的,CoSQA是从网络搜索引擎中收集的。因此,与Adv和代码搜索相比,CoSQA、CoNaLa、SO-DS和StaQC中的查询更接近真实的代码搜索场景。同时,CoNALA、SO-DS和StaQC包含不同粒度的代码,即语句级和代码片段级。这些基准数据集的统计数据列于附录F。继之前的工作(冯等,2020;郭等,2021),我们使用平均倒数秩(MRR)(赫尔,1999)作为所有基准数据集的评估指标。
5.2 实验:微调
在微调实验中,CodeRetriever和其他代码预训练模型在11个特定于语言/领域的代码搜索任务上进行微调,每个任务提供一组标记的查询——代码对用于模型自适应。
5.2.1 微调
以前关于密集文本检索的工作(Karpukhin等人,2020a熊等,2021;曲等,2021)表明,选择负样本的策略可以极大地影响对比学习任务中的模型性能。因此,我们探讨了以下三种代码测量仪微调的方法:1.批内阴性。对于批处理中的<query,code>对,它使用批处理中的其他代码作为负数(Karpukhin等人,2020a)。现有的代码预训练模型以批量负作为默认微调方法(冯等,2020;郭等,2021;王等,2021a)。2.硬否定。它可以挑选“硬”代表性阴性样本,而不是随机阴性样本。与批量否定相比,硬否定训练效率更高(Karpukhin et al.,2020a),广泛应用于文本密集检索。我们跟随高等人。(2021a)用于硬负微调。3.第二次评估报告。这是最近提出的密集检索的训练框架(张等,2021)。它采用对抗训练方法迭代选择“硬”负样本。在本文中,我们重点研究了使用AR2来增强用于代码搜索的暹罗编码器。在微调实验中,我们对{2e-5,1e-5}的学习率和{32,64,128}的批量进行网格搜索。在所有任务中,训练纪元、热身步数和重量衰减分别设置为12、1000和0.01。我们报告了3种不同随机种子下的平均结果。AR2训练的超参数在附录G中列出。我们将CodeRetriever与最先进的预训练模型进行了比较,包括:CodeBERT(冯等,2020),用预训练和替换的令牌检测任务;GraphCodeBERT(郭等,2021),它集成了数据流baesed在代码伯特上。SynCoBERT(王等,2021a),用对比学习对代码-AST对进行预训练;ContraCode(Jain等人,2020年),通过Javascript语料库上的语义保存代码转换进行对比学习预训练。UniXcoder(Guo et al.,2022)由UniLM改编,并对统一的跨模态数据(如代码、AST和文本)进行预训练。
5.2.2 结果
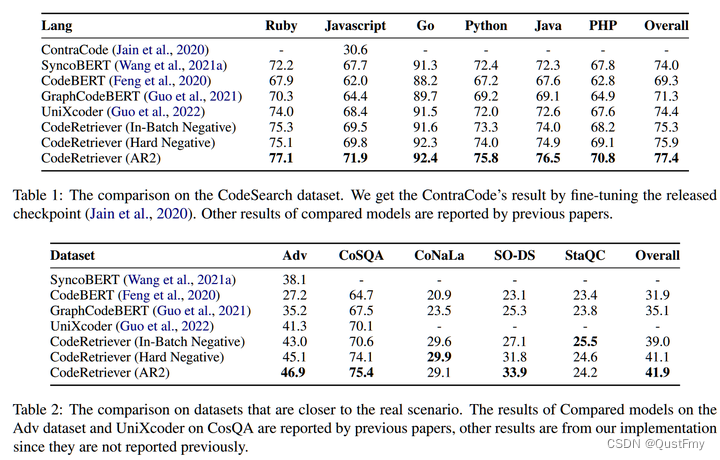
表1和表2显示了所有基准数据集的性能比较。首先,我们报告CodeRetriever(批内阴性)的性能,它使用与其他基线相同的微调方法来确保公平的比较。它表明,与所有其他比较方法相比,CodeRetriever获得了最佳的整体性能。具体来说,CodeRetriever在代码搜索数据集上比GraphCodeBERT提高了4.0个平均绝对点,这证明了CodeRetriever的有效性。与此同时,CodeRetriever在所有有报告结果的任务上都优于以前最先进的模型UniXcoder(郭等人,2022)。在Adv、CoSQA、CoNaLa、SO-DS和StaQC数据集上,CodeRetriever也优于基线模型,这表明CodeRetriever在各种情况下始终优于基线模型。比较不同的微调方法,我们可以看到AR2通常优于批处理底片和硬底片。即,CodeRetriever(AR2)比批处理负片平均提高3.0个绝对点,比硬负片平均提高1.1个绝对点。实验结果表明,选择一个好的微调方法对于下游代码搜索任务也非常重要。从表2中,一个有趣的观察结果是,在StaQC基准测试中,批内负片优于硬负片和AR2。一种可能的解释是,与其他基准相比,StaQC在训练集中包含更多错误的查询代码对,因为它是通过基于规则的方法从stackoverflow收集的,没有任何人工注释,批处理负则比AR2和硬负则更能容忍噪声。
5.3分析
5.3.1 低资源代码搜索
我们评估了CodeRetriever在低资源场景下的性能,即只有几百个成对的查询代码数据用于微调。表显示了CodeRetriever和GraphCodeBERT在CoSQA数据集的低资源设置下的结果,其中训练示例的数量从500到完整(19K)不等。我们可以看到CodeRetriever在低资源设置下可以比GraphCodeBERT达到更合理的性能。
5.3.2 跨语言代码搜索性能

表现
由于构建真实用户查询和代码对是劳动密集型和高成本的,现有的真实世界场景的代码搜索数据集仅覆盖少数编程语言,包括Python(姚等,2018;海曼和卡特塞姆,2020;尹等,2018;黄等,2021),Java(聂等,2017;李等,2019)和SQL(姚等,2018)。在这里,我们引入了一个新的设置,跨语言代码搜索,我们用“a”编程语言微调模型,并在“B”编程语言上测试它。这可以缓解其他编程语言的数据稀缺问题。为了在这种设置下评估我们的方法,我们使用查询Python语料库(CoNaLa(尹等,2018))对模型进行微调,并使用查询Java测试集(李等,2019)对其进行评估。Python语料库和Java语料库中的查询都是从stackoverflow收集的。在表3中,它显示了CodeRetriever中的单峰对比丢失显著地帮助了跨语言代码搜索任务。通过结合双峰对比损耗,CodeRetriever可以获得更好的性能。这个结果表明了CodeRetriever在真实场景中的潜在效用。
可视化

为了进一步分析单峰对比学习的效果,我们通过t-SNE(范德马滕和辛顿,2008)将有或没有单峰对比学习的2D潜在空间表征可视化。在图4(a)中,我们可以看到Java和Python代码的表示出现在没有单峰对比学习(GraphCodeBERT)的模型的两个独立的集群中,而在图4(b)中,它们的表示空间是重叠的。这表明单峰对比学习有助于学习不同编程语言的代码的统一表示空间。
5.3.3 代码到代码搜索结果
我们在代码到代码搜索任务上微调和评估CodeRetriever。在这个任务中,给定一个代码,模型被要求返回一个语义相关的代码。在POJ-104数据集(Mou)上进行实验并使用与先前工作相同的超参数(陆等,2021)。我们通过平均精度(MAP)进行评估,如表5所示。我们看到CodeRetriever优于其他预训练模型,这证明了它的可伸缩性和其他代码理解任务的潜力。
5.3.4 均匀性和对准性
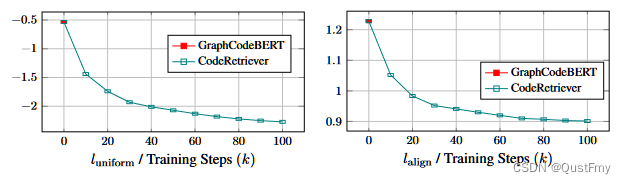
为了研究CodeRetriever对函数级表示空间的影响,我们使用对齐和均匀性度量(Wang和Isola,2020)来查看训练期间函数级表示分布的变化,如图5所示。我们看到,CodeRtriever的均匀性损失逐渐下降,表明各向异性减轻。我们发现对齐损失也有下降的趋势,这表明CodeRetriever的训练有助于对齐代码和自然语言的表示,并更好地理解它们。这两个指标表明,与以前的代码预训练模型相比,CodeRetriever减少了预训练和微调之间的差距。
5.3.5 消融性分析
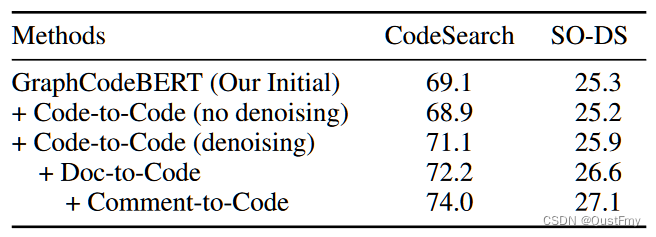
为了了解CodeRetriever中每个组件的作用,我们对CodeSearch Java数据集和SO-DS进行了消融研究。我们从初始模型,并将CodeRetriever的组件逐个添加到其中。我们发现,使用不去噪的编解码对进行单峰对比学习会带来轻微的性能下降,而使用去噪的编解码对会实现显著的性能改善。这证明了去噪步骤的有效性,并表明单峰对比学习依赖于正对构造的质量。在这里,我们验证了一个简单有效的正对构造方法,我们把开发更强大的方法留给了以后的工作。从使用文档代码和注释代码进行双峰对比学习的结果中,我们看到该模型实现了进一步的性能改进,这表明双峰对比学习可以利用文档或注释中的关键语义信息来帮助更好地理解代码。
6.结论
在本文中,我们介绍了结合单峰和双峰对比学习作为代码搜索预训练任务的CodeRetriever。对于单峰对比学习,我们提出了一种语义引导的方法来建立积极的代码对。对于双峰对比学习,我们利用文档和内嵌注释来构建正文本代码对。在几个公开可用的基准上的大量实验结果表明,所提出的CodeRetriever带来了显著的改进,并在所有基准上实现了新的最先进水平。进一步的分析结果表明,CodeRetriever在低资源和跨语言代码搜索任务上也很强大,并证明了单峰和双峰对比学习的有效性。


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









