







一.索引对象
Pandas 相对 Numpy的一大变化就是丰富了数据的索引及其方法
Series 和 DataFrame 的索引----index对象
index对象
每个 Series 对象都有一个 index 属性,通过此属性就能得到 index 对象
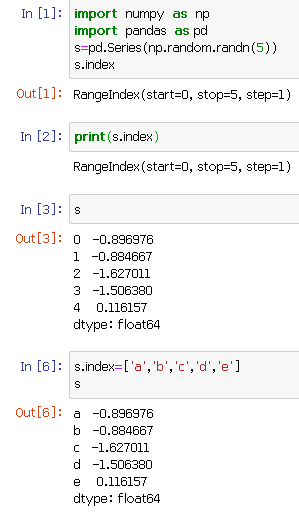
默认索引依旧从0开始,索引值也可以修改
但请注意下面问题
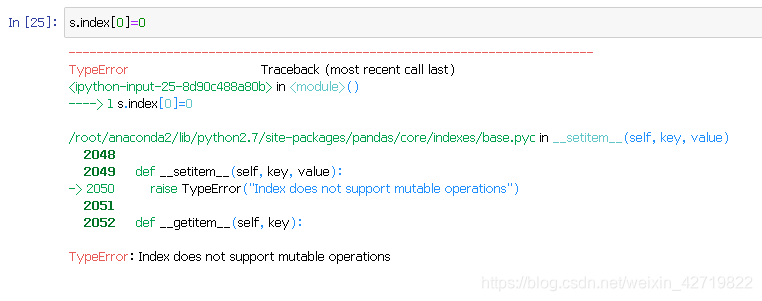
为什么会报错呢,这是因为索引是一个属性,它不支持对 “索引的索引”进行修改,即 index 对象是不可变的
与Python对象相同, index 对象也能通过类创建
pd.Index (data=None, dtype=None, copy=False, name=None, 等)
Index 对象就是 pd.index( )的实例
for example:
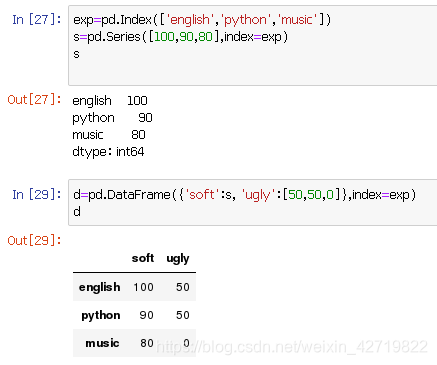
取并集,交集,差集

使用 pd.DataFrame创建多级索引
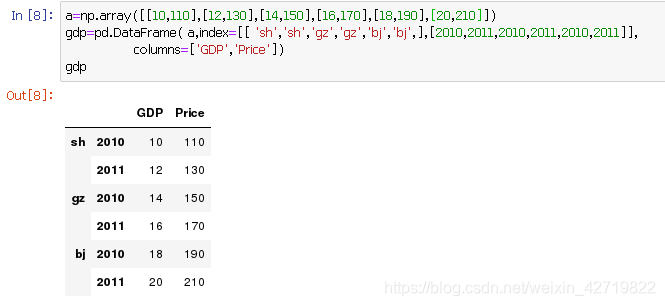
互逆转化,如下,分别是DataFrame处理的一级和多级索引;
相同的数据,不同的表达
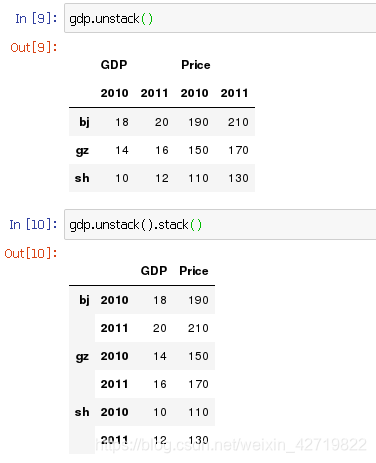
二.数据索引和切片
1.Series对象
这和python的索引方法相同
一些基本方法
'sh' in gdp -----True
gdp.keys( ) 返回gdp的所有索引
gdp.items( ) 返回gdp的所有值
gdp['ss']=2 增加key为‘ss'的一项
gdp.ss 支持.操作,返回是 2;建议少用此方法,有可能和类方法重名
注意:Pandas中的切片,如果使用自己定义的索引值,那么‘前后’都包括,如果使用默认的整数索引,则和python规则相同;Pandas与Numpy不同,没有了 ‘’公用一个视图“概念
实例化一个
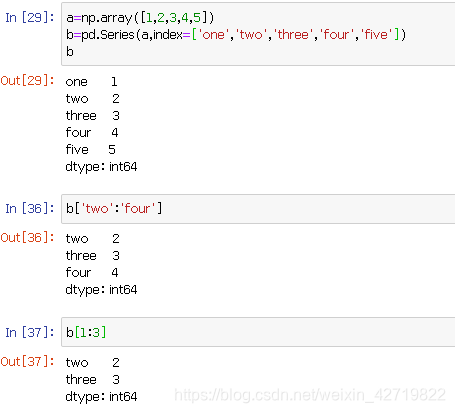
不同之处显而易见
再来看一些特殊情况
当自定义的索引和默认索引重复时,会怎么样呢?没错,会发生一些 “混乱”
所谓兵来将挡,水来土掩,Pandas提供了专门的方法: series.iloc[ ] 和 series.loc[ ]
一个特殊示例如下
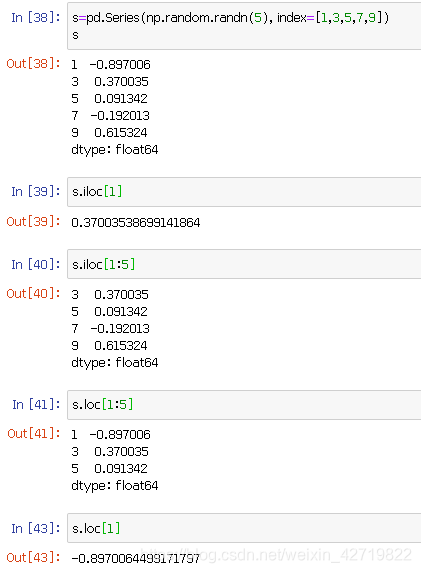
这样就成功避免了 “混乱”
事实上,这个方法也适用于DataFrame 对象

但,它的索引是转化为 Series对象后的索引,即对于DataFrame对象来说,默认读取 列 的索引
a [‘a’]不存在;而对于Series对象来说则不影响
再来看,使用该方法后

显然此方法不受Series对象的限制,能够显示任一索引
如果想要返回第一个数值
采用

默认整数索引

2.DataFrame对象
DataFrame是二维的Pandas数据
借用上面定义过的gdp,这是一个多级索引对象
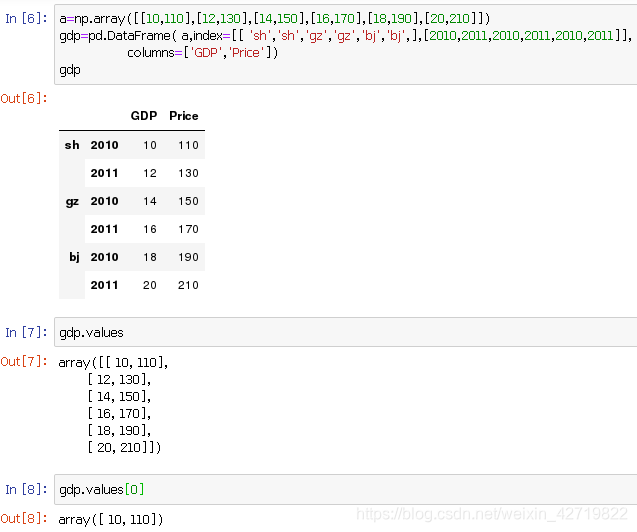
它对应的索引方法
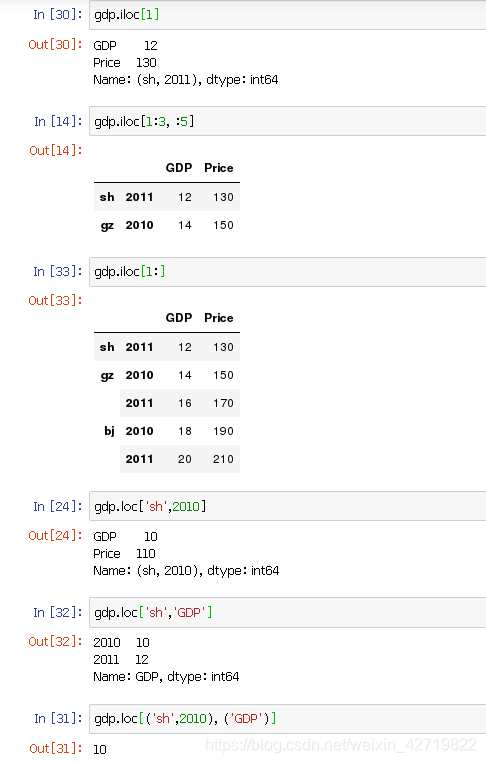
每一行对应一个索引值,支持切片;能完成各种筛选
注意:自定义索引也支持切片,这里未列出,谨记
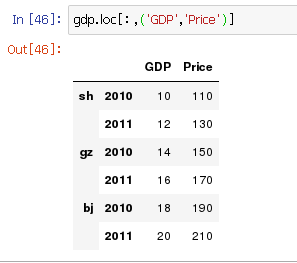
附加一个查看全部的操作
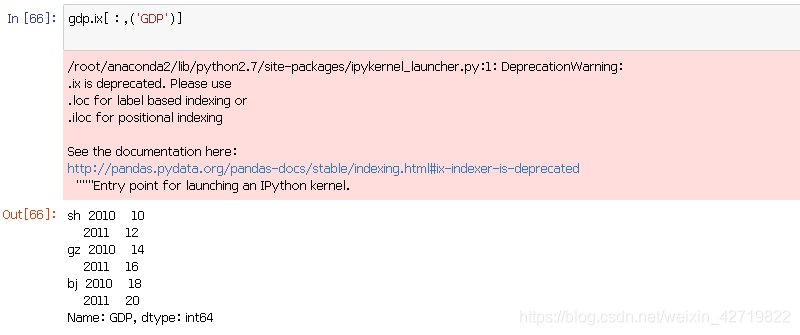
除了这两种方法,还有一个名为 .ix[ ]的获得索引切片的方法,在 [ ] 中可以混合放置默认索引和自定义索引














 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









