







系列文章目录
Chapter 1:创建与探索DF、排序、子集化:Python数据分析——Pandas基础入门+代码(一)
Chapter 2:聚合函数,groupby,统计分析:Python数据分析——Pandas基础入门+代码(二)
Chapter 3:索引和切片:Python数据分析——Pandas基础入门+代码(三)
Chapter 4: 可视化与读写csv文件:Python数据分析——Pandas基础入门+代码(四)
Chapter 5:数据透视表:Python数据分析——Pandas基础入门+代码之数据透视表
文章目录
前言
这一篇主要讲的是:
索引 Indexing 和 切片 Slicing
一开始会从索引开始说起,然后再讲解一下切片,这两部分包看包会。
一、索引
1.1 Index处理

这里主要用到的是两个methods,分别是:
- 设置索引
- 删除索引
# 表示以xxx为索引
set_index('xxx')
# 重置索引,如果又drop表示,会先重置索引再对刚刚索引的那列进行删除
reset_index(drop = True)
1.2 使用 .loc() 进行子集化

这里的翻译是:
- 索引的杀手级功能是 .loc[]:一种接受索引值的子集方法。当您向其传递单个参数时,它将采用行的子集。
- 使用 .loc[] 进行子集化的代码比标准的方括号子集化更容易阅读,这可以减少您的代码维护的负担。
说白了就是最好用.loc[]去找我们要的东西,这不仅方便索引,也方便我们阅读结果。同时,.loc()也能用于切片处理,这会在后面讲解。
For example, 下面的代码做了一个对比,得到的结果是一样的。
首先,给定一个城市的list
然后,利用isin()进行查找返回一个布林值,再要求pandas将布林值为True的找出来并打印
最后一行呢,是直接让loc去定位查找,包含了list中的数据,从而筛选出来并打印
# Make a list of cities to subset on
cities = ["Moscow", "Saint Petersburg"]
# Subset temperatures using square brackets
print(temperatures[temperatures["city"].isin(cities)])
# Subset temperatures_ind using .loc[]
print(temperatures_ind.loc[cities])
1.3 分层索引

分层索引的直接意思就是,可以一次索引多列,不想前面只索引了一列。分层索引的好处就是可以更好的推理嵌套分类变量。图中的例子就说对照组和实验组。
我们可以先看下原数据temperatures_ind 的前几行内容是什么样的:国家、城市、日期、平均温度
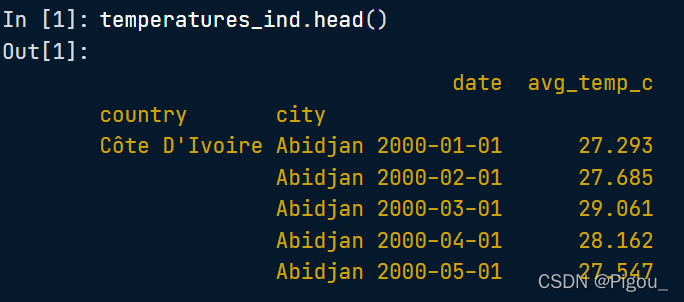
得到temperatures_ind 之后,我们建立一个元组,让loc去定位索引。
# Index temperatures by country & city
temperatures_ind = temperatures.set_index(['country' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5251
5251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











