







框架
这篇论文除摘要外共分七个部分。
1.总体介绍
文章中提到:
1)现在大的数据集有LabelMe(包含成千上万个完全分割的图像)和ImageNet(包含超过22000个类别的多于1500万张高分辨率图像)。
2)对象识别任务的巨大复杂性意味着即使像ImageNet这样大的数据集也不能解决这个问题,因此我们的模型也应该具有大量的先验知识来补充没有的数据。
3)与具有相似大小层的标准前馈神经网络相比,CNNs具有更少的连接和参数,因此更容易训练,而其理论上最好的性能可能只差一点点。
4)作者们编写了一个高度优化的GPU实现的2D卷积和所有其他训练卷积神经网络固有的操作,并将其公开了(网址:http://code.google.com/p/cuda-convent)
5)最终的网络包含5个卷积和3个全连接层,这个深度很重要。因为经过实验发现去掉任何卷积层(每个卷积层包含的参数不超过模型参数的1%)都会导致性能下降。
2.数据集
1)在ImageNet上,通常报告两个错误率:top-1和top-5,其中top 5错误率是测试图像的一部分,其中正确的标签不在模型认为最可能出现的五个标签中
2)ImageNet由可变分辨率的图像组成,而他们的系统需要一个恒定的输入维数。因此,他们将图像降采样到一个固定的分辨率为256 * 256。给定一个矩形图像,首先重新调整图像的大小,使较短的边长度为256,然后从生成的图像中裁剪出中心256 * 256的块。除了从每个像素中减去训练集上的平均值外,并没有以任何其他方式对图像进行预处理。因此,他们是在像素的原始RGB值中训练网络的。
3.架构
网络的架构包含8个学习层——5个卷积层和3个全连接层。

3.1 ReLU非线性
对于同一深度卷积神经网络而言,使用ReLUs比使用tanh进行训练使用的时间短。
3.2 在多CPU上训练
1)他们使用的并行化方案本质上是将一半内核(或神经元)放在每个GPU上,还有一个额外的技巧:GPU只在特定的层中通信。这意味着,例如,第3层的内核从第2层的所有内核映射中获取输入。然而,第4层的内核只从位于同一GPU的第3层的内核映射中获取输入。对于交叉验证来说,选择连接模式是一个问题,但这允许我们精确地调整通信量,直到它是计算量的可接受部分。
2)双gpu网络的训练时间比单gpu网络略短。
在最后一个卷积层中,单gpu网络的内核数量与双gpu网络相同。这是因为网络的大部分参数都在第一个全连接层中,它以最后一个卷积层作为输入。因此,为了使这两个网具有大致相同的参数数量,我们没有将最终卷积层的大小减半(也没有将随后的全连接层的大小减半)。因此,这种比较偏向于单gpu网络,因为它比双gpu网络的“一半大”。
3.3 局部响应归一化
1)ReLUs有一个理想的特性,即不需要对输入进行标准化以防止其饱和。如果至少有一些训练例子对ReLU产生积极的输入,学习就会发生在那个神经元上。
2)下面的局部归一化方案有助于泛化。

3.4 重叠池化
CNNs中的汇聚层总结了同一核映射中相邻神经元群的输出。传统上,相邻池单元汇总的邻域不重叠。更精确地说,池层可以被认为是由间隔为 s 像素的池单元网格组成,每个网格汇总一个以池单元位置为中心的大小为 z * z 的邻域。如果设置s = z,将得到传统的本地池,就像CNNs中常用的那样。如果设置s < z,我们得到重叠池。这是作者在整个网络中使用的:s = 2,z = 3。作者在训练过程中观察到,具有重叠池的模型稍微不容易发生过拟合现象。
3.5 总体架构
网络包含八层,前五层是卷积层,剩下的三层为全连接层。最后一个全连接层的输出被提供给一个1000-way的softmax函数,它产生了一个超过1000个类标签的分布。作者的网络将多项式逻辑回归目标最大化,这等价于在预测分布下,将正确标签的log-概率的训练样本均值最大化。
第二层、第四层和第五层卷积层的内核只连接到上一层与其在同一GPU上的内核映射,第三层卷积层的内核连接到第二层的所有内核映射。全连接层的神经元与前一层的所有神经元连接。响应归一化层紧接着第一个和第二个卷积层。ReLU应用在每个卷积层和全连接层的输出。
第一个卷积层的输入为224 * 224 * 3的图像,对其使用96个大小为11 * 11 * 3的步长为4(步长表示内核映射中相邻神经元感受野中心之间的距离)的内核来处理输入图像。第二个卷积层将第一个卷积层的输出(响应归一化以及池化)作为输入,并使用256个内核处理图像,每个内核大小为5 * 5 * 48。第三个、第四个和第五个卷积层彼此连接而中间没有任何池化或归一化层。第三个卷积层有384个内核,每个的大小为3 * 3 * 256,其输入为第二个卷积层的输出。第四个卷积层有384个内核,每个内核大小为3 * 3 * 192。第五个卷积层有256个内核,每个内核大小为3 * 3 * 192。全连接层各有4096个神经元。
4.减少过拟合的方法
主要有两种方法来减少过拟合:
4.1 数据增强
作者使用了两种不同的数据增强形式,这两种方法都允许从原始图像生成转换后的图像,并且只需要很少的计算,因此转换后的图像不需要存储在磁盘上。在实现中,转换后的图像是用Python代码在CPU上生成的,而GPU正在对前一批图像进行训练。因此,这些数据增强方案实际上是无需计算的。
1)第一种形式包括图像平移和水平反射。作者通过从256 * 256规格图像中随机提取224 * 224大小的块(以及它们的水平映射),并在这些补块上训练他们的网络来做到这一点。这将训练集的大小增加了2048倍,尽管由此产生的训练示例当然是高度相互依赖的。如果没有这个方案,网络可能遭受严重的过拟合,这迫使我们使用更小的网络。在测试时,网络通过提取5个224 * 224的块(四个角块和中心块)及其水平映射(共10个块)进行预测,并求网络的softmax层10个块的预测平均值。
2)第二种形式包括改变训练图像中RGB通道的灰度。作者在整个ImageNet训练集图像的RGB像素值上使用PCA。对于每个训练图像,我们添加多个通过PCA找到的主成分,大小与相应的特征值成比例,乘以一个随机值,该随机值属于均值为0、标准差为0.1的高斯分布。
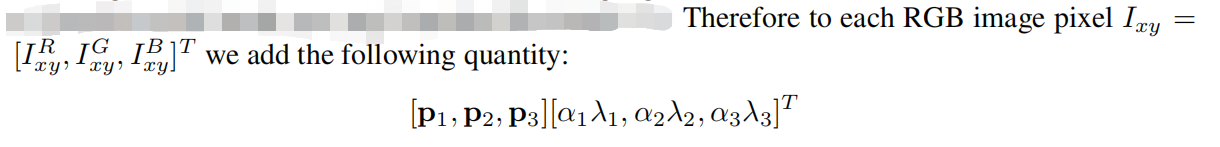 其中,pi和λi分别是3x3的RGB协方差矩阵的第i个特征向量和第i个的特征值,而αi是前面所说的随机值。对于一张特定图像中的所有像素,每个αi只会被抽取一次,直到这张图片再次用于训练时,才会重新提取随机变量。这个方案近似地捕捉原始图像的一些重要属性,对象的身份不受光照的强度和颜色变化影响。
其中,pi和λi分别是3x3的RGB协方差矩阵的第i个特征向量和第i个的特征值,而αi是前面所说的随机值。对于一张特定图像中的所有像素,每个αi只会被抽取一次,直到这张图片再次用于训练时,才会重新提取随机变量。这个方案近似地捕捉原始图像的一些重要属性,对象的身份不受光照的强度和颜色变化影响。
4.2 随机失活(Dropout)
1)以Dropout方法被置0的神经元不参与网络的前馈和反向传播。因此,每次给网络提供了输入后,神经网络都会采用一个不同的结构,但是这些结构都共享权重。这种技术减少了神经元的复杂适应性,因为神经元无法依赖于其他特定的神经元而存在。
2)作者前两个全连接层上使用了dropout。没有dropout,作者的网络会出现严重的过拟合。Dropout大概会使达到收敛的迭代次数翻倍。
5. 网络学习的细节介绍
使用随机梯度下降法来训练我们的模型,每个批次有128个样本,动量为0.9,权重衰减为0.0005。这种较小的权重衰减对于模型的训练很重要。换句话说,权重衰减在这里不仅仅是一个正则化方法:它减少了模型的训练误差。
 作者使用方差为0.01、均值为0的高斯分布来初始化各层的权重。网络中的第二个、第四个和第五个卷积层以及全连接层中的隐含层中的所有偏置参数使用常数1进行初始化。这种初始化权重的方法通过向ReLU提供了正的输入,来加速前期的训练。使用常数0来初始化剩余层中的偏置参数。
作者使用方差为0.01、均值为0的高斯分布来初始化各层的权重。网络中的第二个、第四个和第五个卷积层以及全连接层中的隐含层中的所有偏置参数使用常数1进行初始化。这种初始化权重的方法通过向ReLU提供了正的输入,来加速前期的训练。使用常数0来初始化剩余层中的偏置参数。
作者对所有层都使用相同的学习率,在训练过程中又手动进行了调整。作者遵循的启发式方法是:以当前的学习速率训练,当验证集上的错误率停止降低时,将学习速率除以10。学习率初始值设为0.01,并且在终止前减少3次。
6. 结果
7. 讨论
研究结果表明,一个大的深层卷积神经网络能够在纯粹使用监督学习的情况下,在极具挑战性的数据集上实现破纪录的结果。















 2015
2015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









