







《Generalized End-to-End Loss for Speaker Verification》论文学习
文章目录
摘要
本文提出了一种新的广义端到端(GE2E)损失函数,该函数使说话人验证模型的训练效率比之前基于元组的端到端(TE2E)损失函数更高。与TE2E不同,GE2E损失函数以一种方式更新网络,在训练过程的每一步强调难以验证的例子。此外,GE2E损失不需要初始阶段的示例选择。基于这些特性,我们的模型在增加损失函数的同时,使说话人验证EER降低了10%以上,同时减少了60%的训练时间。我们还介绍了MultiReader技术,它允许我们进行领域适应训练,一个更精确的模型,支持多个关键字(例如,“OK Google”和“Hey Google”)以及多种方言。
关键字 :说话人验证,端到端损失,MultiReader,关键字检测
1 介绍
1.1 背景
说话人验证(Speaker verification, SV)是基于说话人已知的语音(即注册语音),利用Voice Match(《Tomato, tomahto. Google Home now supports multiple users》,《Voice match will allow Google Home to recognize your voice》)等应用,验证某条语音是否属于该说话人的过程。
根据用于登记和验证的语音的限制,说话人验证模型通常分为两类:文本依赖的说话人验证(TD-SV)和文本独立的说话人验证(TI-SV)。在TD-SV中,加入语和验证语的转录本都有语音上的约束,而在TI-SV中,加入语和验证语的转录本没有词汇上的约束,暴露出更大的音素和话语时长的变异性(《An overview of textindependent speaker recognition: From features to supervectors》,《A tutorial on text-independent speaker verification》)。在这项工作中,我们专注于TI-SV和TD-SV的一个特殊子任务,即全局密码TD-SV,其中验证是基于检测到的关键字,例如 “OK Google”(《Small-footprint keyword spotting using deep neural networks》,《Automatic gain control and multi-style training for robust small-footprint keyword spotting with deep neural networks》)。
在以前的研究中,基于i-vector的系统一直是TD-SV和TI-SV应用《Front-end factor analysis for speaker verification》的主要方法。近年来,越来越多的工作集中在使用神经网络进行说话人验证,而最成功的系统使用端到端训练(《Deep neural networks for small footprint text-dependent speaker verification》,《Locally-connected and convolutional neural networks for small footprint speaker recognition》,《Deep speaker: an end-to-end neural speaker embedding system》,《End-to-end attention based text-dependent speaker verification》,《The IBM 2016 speaker recognition system》)。在这样的系统中,神经网络的输出向量通常称为嵌入向量(也称为d-vector)。与i-vector类似,这种嵌入可以用来表示固定维度空间中的语音,在这个空间中,可以使用其他通常更简单的方法来消除说话人之间的歧义。
1.2 基于元组的端到端损失
在我们之前的工作(《End-to-end text-dependent speaker verification》)中,我们提出了基于元组的端到端(TE2E)模型,该模型模拟了训练期间运行时注册和验证的两阶段过程。在我们的实验中,TE2E模型结合LSTM(《Long short-term memory》)获得了当时最好的性能。对于每个训练步骤,一个元组包含一个评价语音
X
j
∽
X_{j\backsim}
Xj∽和
M
M
M个注册语音
X
k
m
X_{km}
Xkm(当
m
=
1
,
.
.
.
,
M
m = 1,...,M
m=1,...,M)被送入我们的LSTM网络:
{
X
j
∽
,
(
X
k
1
,
.
.
.
,
X
k
M
)
}
\{X_{j\backsim},(X_{k1},...,X_{kM})\}
{Xj∽,(Xk1,...,XkM)},其中
X
X
X代表一个定长段的特征(log-mel-filterbank 能量),
j
j
j和
k
k
k代表语音的说话人,而
j
j
j可能等于也可能不等于
k
k
k。该元组包含来自说话人
j
j
j的单个语音,而
M
M
M来自说话人
k
k
k的不同语音。如果
X
j
X_j
Xj和
M
M
M加入的语音来自同一个说话人,即
j
=
k
j = k
j=k,则称该元组为正的,否则称其为负的。我们交替生成正元组和负元组。
对于每个输入元组,我们计算LSTM的L2归一化响应:
{
e
j
∽
,
(
e
k
1
,
.
.
.
,
e
k
M
)
}
\{e_{j\backsim},(e_{k1},...,e_{kM})\}
{ej∽,(ek1,...,ekM)}。这里每个
e
e
e是一个固定维数的嵌入向量,它是由LSTM定义的序列-向量映射产生的。元组的质心
(
e
k
1
,
.
.
.
,
e
k
M
)
(e_{k1},...,e_{kM})
(ek1,...,ekM)表示由
M
M
M个语音构建的声纹,其定义如下
c
k
=
E
m
[
e
k
m
]
=
1
M
∑
m
=
1
M
e
k
m
(1)
c_k=\mathbb{E}_m[e_{km}] = \frac {1}{M} \sum_{m=1}^M e_{km} \tag{1}
ck=Em[ekm]=M1m=1∑Mekm(1) 相似度是用余弦相似度函数定义的:
s
=
w
⋅
c
o
s
(
e
j
∽
,
c
k
)
+
b
(2)
s = w \cdot cos(e_{j\backsim}, c_k) + b \tag{2}
s=w⋅cos(ej∽,ck)+b(2)
w
w
w和
b
b
b为可学习值时,TE2E损失最终定义为:
L
T
(
e
j
∽
,
c
k
)
=
δ
(
j
,
k
)
(
1
−
σ
(
s
)
)
+
(
1
−
δ
(
j
,
k
)
)
σ
(
s
)
(3)
L_T(e_{j\backsim}, c_k) = \delta(j,k)\big( 1 - \sigma(s) \big) + \big( 1 - \delta(j,k) \big) \sigma(s) \tag{3}
LT(ej∽,ck)=δ(j,k)(1−σ(s))+(1−δ(j,k))σ(s)(3) 这里
σ
(
x
)
=
1
/
(
1
+
e
−
x
)
σ(x) = 1/(1 + e^{-x})
σ(x)=1/(1+e−x)是标准的sigmoid函数,如果
j
=
k
j = k
j=k,
δ
(
j
,
k
)
δ(j, k)
δ(j,k)等于
1
1
1,否则等于
0
0
0。当
k
=
j
k = j
k=j时,TE2E损失函数鼓励更大的
s
s
s值,当
k
≠
j
k \ne j
k=j时,鼓励更小的
s
s
s值。考虑到正元组和负元组的更新,这个损失函数非常类似于FaceNet(《Facenet: A unified embedding for face recognition and clustering》)中的三重损失。
1.3 概述
在本文中,我们介绍了TE2E体系结构的一个概括。这种新的体系结构从不同长度的输入序列以更有效的方式构造元组,大大提高了TD-SV和TI-SV的性能和训练速度。本文组织如下:第2.1节给出了GE2E损失的定义;第2.2节是为什么GE2E更有效地更新模型参数的理论论证;第2.3节介绍了一种名为“MultiReader”的技术,它使我们能够训练一个支持多种关键字和语言的单一模型;最后,我们在第三节展示我们的实验结果。
2 广义的端到端模型
广义端到端(GE2E)训练基于一次处理大量的语音,以批处理的形式包含
N
N
N个说话人,平均每个说话人有
M
M
M个语音,如图1所示。

2.1 训练方法
我们获取
N
×
M
N \times M
N×M个语音来构建一个批处理。这些语音来自
N
N
N个不同的说话人,每个说话人有
M
M
M个语音。每个特征向量
X
j
i
(
1
≤
j
≤
N
a
n
d
1
≤
i
≤
M
)
X_{ji} (1 \le j \le N \ and \ 1 \le i \le M)
Xji(1≤j≤N and 1≤i≤M)表示从说话人
j
j
j的语音
i
i
i中提取的特征。
与前面的工作(《End-to-end text-dependent speaker verification》)类似,我们将从每个语音
X
j
i
X_{ji}
Xji中提取的特征输入到LSTM网络中。线性层连接到最后一个LSTM层,作为网络最后一帧响应的附加变换。我们将整个神经网络的输出表示为
f
(
X
j
i
;
w
)
f(X_{ji};w)
f(Xji;w)。其中,
w
w
w表示神经网络的所有参数(包括LSTM层和线性层)。将嵌入向量(d-vector)定义为网络输出的L2归一化:
e
j
i
=
f
(
X
j
i
;
w
)
∣
∣
f
(
X
j
i
;
w
)
∣
∣
2
(4)
e_{ji} = \frac {f(X_{ji};w)} {||f(X_{ji};w)||_2} \tag{4}
eji=∣∣f(Xji;w)∣∣2f(Xji;w)(4) 这里
e
j
i
e_{ji}
eji表示第
j
j
j个说话人的语音的嵌入向量。从第
j
j
j个说话人
[
e
j
1
,
.
.
.
,
e
j
M
]
[e_{j1},...,e_{jM}]
[ej1,...,ejM]的嵌入向量的质心,通过公式1定义为
c
j
c_j
cj。
相似矩阵
S
j
i
,
k
S_{ji,k}
Sji,k定义为每个嵌入向量
e
j
i
e_{ji}
eji与所有质心
c
k
(
1
≤
j
,
k
≤
N
a
n
d
1
≤
i
≤
M
)
c_k (1 \le j, k \le N \ and \ 1 \le i \le M)
ck(1≤j,k≤N and 1≤i≤M)的缩放余弦相似度:
S
j
i
,
k
=
w
⋅
c
o
s
(
e
j
i
,
c
k
)
+
b
(5)
S_{ji,k} = w \cdot cos(e_{ji}, c_k) + b \tag{5}
Sji,k=w⋅cos(eji,ck)+b(5) 其中
w
w
w和
b
b
b是可学习参数。我们限制权值为正
w
>
0
w > 0
w>0,因为当余弦相似度更大时,相似度也更大。TE2E和GE2E之间的主要区别如下:
(1)TE2E的相似度(公式2)是一个标量值,它定义了嵌入向量
e
j
∽
e_{j\backsim}
ej∽与单个元组质心
c
k
c_k
ck之间的相似度。
(2)GE2E建立了一个相似矩阵(公式5),它定义了每个
e
j
i
e_{ji}
eji与和所有质心
c
k
c_k
ck之间的相似点。
图1展示了整个过程,包括特征、嵌入向量和不同说话人的相似度得分,用不同的颜色表示。
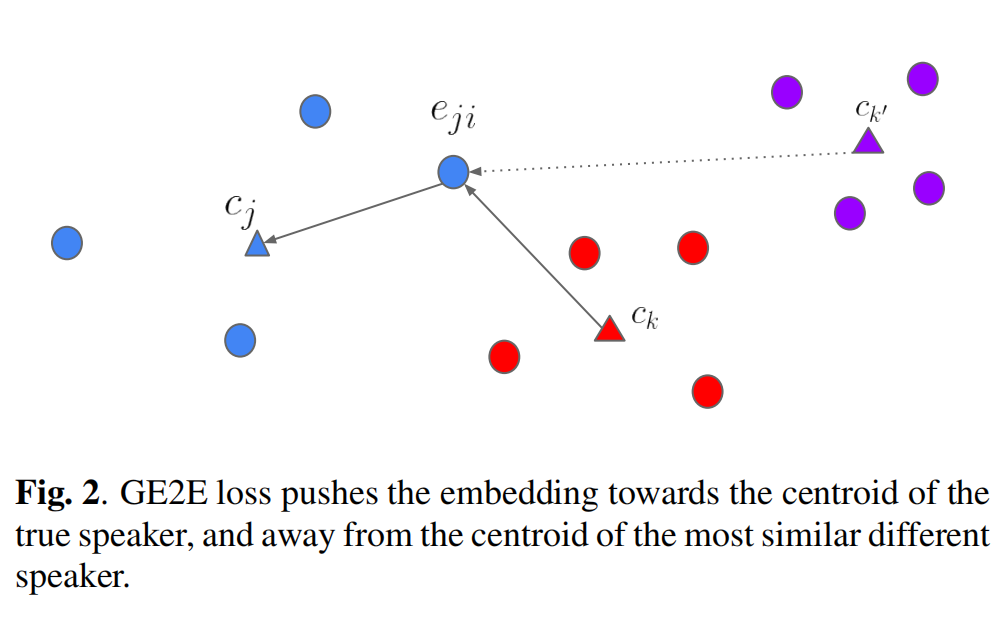
在训练过程中,我们希望每个语音的嵌入都与该说话人嵌入的质心相似,同时又远离其他说话人的质心。如图1中的相似矩阵所示,我们希望有色区域的相似值较大,灰色区域的相似值较小。图2以不同的方式说明了相同的概念:我们希望蓝色嵌入向量靠近它自己的说话人的质心(蓝色三角形),而远离其他质心(红色和紫色三角形),特别是最近的一个(红色三角形)。给定一个嵌入向量
e
j
i
e_{ji}
eji,所有质心
c
k
c_k
ck,以及相应的相似矩阵
S
j
i
,
k
S_{ji,k}
Sji,k,有两种方法来实现这个概念:
Softmax
我们在
S
j
i
S_{ji}
Sji上放一个softmax,且
k
=
1
,
.
.
.
,
N
k = 1,...,N
k=1,...,N使输出等于
1
i
f
f
k
=
j
1 \ iff \ k = j
1 iff k=j,否则使输出等于
0
0
0。因此,可以将每个嵌入向量
e
j
i
e_{ji}
eji上的损失定义为:
L
(
e
j
i
)
=
−
S
j
i
,
j
+
l
o
g
∑
k
=
1
N
e
x
p
(
S
j
i
,
k
)
(6)
L(e_{ji}) =-S_{ji,j} + log\sum^N_{k=1}exp(S_{ji,k}) \tag{6}
L(eji)=−Sji,j+logk=1∑Nexp(Sji,k)(6) 这个损失函数意味着我们将每个嵌入向量推近它的质心,并将它拉离所有其他质心。
Contrast
对比损失定义在正对和最激进的负对上,如:
L
(
e
j
i
)
=
1
−
σ
(
S
j
i
,
j
)
+
m
a
x
1
≤
k
≤
N
k
≠
j
σ
(
S
j
i
,
k
)
(7)
L(e_{ji}) =1-\sigma(S_{ji,j}) + \underset{k \ne j} {\underset{1 \le k \le N}{max}} \sigma(S_{ji,k}) \tag{7}
L(eji)=1−σ(Sji,j)+k=j1≤k≤Nmaxσ(Sji,k)(7) 其中
σ
(
x
)
=
1
/
(
1
+
e
−
x
)
σ(x) = 1/(1 +e^{-x})
σ(x)=1/(1+e−x)为
s
s
s型函数。对于每一个语音,准确地增加两个分量的损失:(1)一个正分量,它与嵌入向量与其真实说话人的声纹(质心)之间的正匹配有关。(2)一个硬负分量,与嵌入向量和所有虚假说话人中相似度最高的声纹(质心)之间的负匹配相关联。
在图2中,正项对应于将
e
j
i
e_{ji}
eji(蓝色圆圈)推向
c
k
c_k
ck(蓝色三角形)。负项对应于将
e
j
i
e_{ji}
eji(蓝色圆圈)从
c
k
c_k
ck(红色三角形)中拉出,因为
c
k
c_k
ck与
c
k
′
c_{k^\prime}
ck′相比更类似于
e
j
i
e_{ji}
eji。因此,对比损失可以让我们专注于困难的嵌入向量和负质心对。
在我们的实验中,我们发现GE2E损耗的两种实现都是有用的:Contrast Loss在TD-SV中表现更好,而Softmax Loss在TI-SV中表现略好。
此外,我们观察到在计算真说话人的质心时去除
e
j
i
e_{ji}
eji可以使训练稳定,并有助于避免琐碎的解。因此,在计算负相似度(即
k
≠
j
k \ne j
k=j)时,我们仍然使用方程1,而当
k
=
j
k = j
k=j时,我们使用公式8:
c
j
(
−
i
)
=
1
M
−
1
∑
m
=
1
m
≠
i
M
e
j
m
(8)
\mathbf{c}_j^{(-i)} = \frac {1} {M-1} \sum^M_{\underset{m \ne i}{m=1}} e_{jm} \tag{8}
cj(−i)=M−11m=im=1∑Mejm(8)
S
j
i
,
k
=
{
w
⋅
c
o
s
(
e
j
i
,
c
j
(
−
i
)
)
+
b
,
if
k
=
j
;
w
⋅
c
o
s
(
e
j
i
,
c
k
)
+
b
,
otherwise.
(9)
S_{ji,k} = \begin{cases} w \cdot cos(\mathbf{e}_{ji}, \mathbf{c}_j^{(-i)}) + b, & \text{if $k = j$;} \\ w \cdot cos(\mathbf{e}_{ji}, \mathbf{c}_k) + b, & \text{otherwise.} \end{cases} \tag{9}
Sji,k={w⋅cos(eji,cj(−i))+b,w⋅cos(eji,ck)+b,if k=j;otherwise.(9) 结合方程4、6、7和9,最终GE2E损失
L
G
L_G
LG为相似性矩阵(
1
≤
j
≤
N
a
n
d
1
≤
i
≤
M
1 \le j \le N \ and \ 1 \le i \le M
1≤j≤N and 1≤i≤M)上的所有损失之和:
L
G
(
x
;
w
)
=
L
G
(
S
)
=
∑
j
,
i
L
(
e
j
i
)
(10)
L_G (\mathbf{x};\mathbf{w}) = L_G(\mathbf{S}) = \sum_{j,i}L(\mathbf{e}_{ji}) \tag{10}
LG(x;w)=LG(S)=j,i∑L(eji)(10)
2.2 TE2E与GE2E的比较
考虑GE2E损失更新中的单个批次:我们有
N
N
N个说话人,每个人有
M
M
M个语音。每一步更新都会将所有
N
×
M
N \times M
N×M嵌入向量推向它们自己的质心,并将它们拉离其他质心。
这反映了对于每个
x
j
i
\mathbf{x}_{ji}
xji, TE2E损失函数(《End-to-end text-dependent speaker verification》)中所有可能的元组所发生的情况。假设我们在比较说话人时,随机从说话人
j
j
j中选择
P
P
P个话语:
(1)正元组:
{
x
j
i
,
(
x
j
,
i
1
,
.
.
.
,
x
j
,
i
P
)
}
\{ \mathbf{x}_{ji},(\mathbf{x}_{j,i_1},...,\mathbf{x}_{j,i_P}) \}
{xji,(xj,i1,...,xj,iP)}且
1
≤
i
p
≤
M
a
n
d
p
=
1
,
.
.
.
,
P
1 \le i_p \le M \ and \ p = 1,...,P
1≤ip≤M and p=1,...,P。有
(
M
P
)
\begin{pmatrix} M \\ P \\ \end{pmatrix}
(MP)这样的正元组。
(2)负元组:
{
x
j
i
,
(
x
k
,
i
1
,
.
.
.
,
x
k
,
i
P
)
}
\{ \mathbf{x}_{ji},(\mathbf{x}_{k,i_1},...,\mathbf{x}_{k,i_P}) \}
{xji,(xk,i1,...,xk,iP)}且
k
≠
j
a
n
d
1
≤
i
p
≤
M
a
n
d
p
=
1
,
.
.
.
,
P
k \ne j \ and \ 1 \le i_p \le M \ and \ p = 1,...,P
k=j and 1≤ip≤M and p=1,...,P。对于每个
x
j
i
\mathbf{x}_{ji}
xji,我们必须与所有其他
N
−
1
N-1
N−1质心进行比较,其中每组
N
−
1
N-1
N−1比较都包含
(
M
P
)
\begin{pmatrix} M \\ P \\ \end{pmatrix}
(MP)元组。
每个正元组与一个负元组相平衡,因此总数量是正元组和负元组的最大数量乘以2。因此,TE2E损失的元组总数为:
2
×
(
(
M
P
)
,
(
N
−
1
)
(
M
P
)
)
≥
2
(
N
−
1
)
(11)
2 \times \left( \begin{pmatrix} M \\ P \\ \end{pmatrix}, \left( N-1 \right) \begin{pmatrix} M \\ P \\ \end{pmatrix} \right) \ge 2 \left( N-1 \right) \tag{11}
2×((MP),(N−1)(MP))≥2(N−1)(11) 公式11的下界发生在
P
=
m
P = m
P=m时。因此,在我们的GE2E损失中,
x
j
i
\mathbf{x}_{ji}
xji的每一次更新都等于我们的TE2E损失中至少
2
(
N
−
1
)
2(N - 1)
2(N−1)个步骤。上述分析说明了为什么GE2E更新模型比TE2E更有效,这与我们的经验观察结果一致:GE2E在更短的时间内收敛到更好的模型(详见第3节)。
2.3 训练MultiReader
考虑以下情况:我们关心一个域中的模型应用程序,它有一个小数据集
D
1
D_1
D1。同时,我们在一个类似但不完全相同的领域有一个更大的数据集
D
2
D_2
D2。我们希望在
D
2
D_2
D2的帮助下,训练一个在数据集
D
1
D_1
D1上表现良好的单一模型:
L
(
D
1
,
D
2
;
w
)
=
E
x
∈
D
1
[
L
(
x
;
w
)
]
+
α
E
x
∈
D
2
[
L
(
x
;
w
)
]
(12)
L \left( D_1,D_2;\mathbf{w} \right) = \mathbb{E}_{x \in D_1}[L(\mathbf{x};\mathbf{w})] + \alpha \mathbb{E}_{x \in D_2}[L(\mathbf{x};\mathbf{w})] \tag{12}
L(D1,D2;w)=Ex∈D1[L(x;w)]+αEx∈D2[L(x;w)](12) 这类似于正则化技术:在正常的正则化中,我们使用
α
∣
∣
w
∣
∣
2
2
\alpha||\mathbf{w}||^2_2
α∣∣w∣∣22来正则化模型。但这里,我们用
E
x
∈
D
2
[
L
(
x
;
w
)
]
\mathbb{E}_{x \in D_2}[L(\mathbf{x};\mathbf{w})]
Ex∈D2[L(x;w)]正规化。当数据集
D
1
D_1
D1没有足够的数据时,在
D
1
D_1
D1上训练网络会导致过拟合。要求网络在
D
2
D_2
D2上也能相当好地执行有助于使网络规范化。
这可以推广到组合
K
K
K个不同的,可能极度不平衡的数据源:
D
1
,
.
.
.
,
D
K
D_1,...,D_K
D1,...,DK。我们为每个数据源分配一个权重
α
k
\alpha_k
αk,表示该数据源的重要性。在训练过程中,在每一步中,我们从每个数据源提取一个批/元组的话语,并计算综合损失为:
L
(
D
1
,
.
.
.
,
D
K
)
=
∑
k
=
1
K
α
k
E
x
k
∈
D
K
[
L
(
x
k
;
w
)
]
L(D_1,...,D_K) = \sum^K_{k=1} α_k \mathbb{E}_{\mathbf{x}_k \in D_K} [L(\mathbf{x}_k;\mathbf{w})]
L(D1,...,DK)=∑k=1KαkExk∈DK[L(xk;w)],其中每
L
(
x
k
;
w
)
L(\mathbf{x}_k;\mathbf{w})
L(xk;w)为公式10中定义的损失。
3 实验
在我们的实验中,特征提取过程与(《Automatic gain control and multi-style training for robust small-footprint keyword spotting with deep neural networks》)相同。音频信号首先被转换成宽度为25ms、步长为10ms的帧。然后提取40维对数梅尔滤波器组能量作为每帧的特征。对于TD-SV应用,同样的功能用于关键字检测和说话人验证。关键字检测系统只将包含该关键字的帧传递给说话人验证系统。这些帧形成一个固定长度(通常是800ms)的段。对于TI-SV应用,我们通常在语音活动检测(VAD)后提取随机定长段,并使用滑动窗口方法进行推断(在第3.2节讨论)。
我们的生产系统使用投影(《Long short-term memory recurrent neural network architectures for large scale acoustic modeling》)的三层LSTM。嵌入向量(d-vector)大小与LSTM投影大小相同。对于TD-SV,我们使用128个隐藏节点,投影大小为64。对于TI-SV,我们使用768个隐藏节点,投影大小为256。在训练GE2E模型时,每批包含
N
=
64
N = 64
N=64位说话人,
M
=
10
M = 10
M=10位说话人。我们使用初始学习速率为0.01的SGD训练网络,每30M步将学习速率降低一半。将梯度的L2范数裁剪到
3
3
3(《Understanding the exploding gradient problem》),将LSTM中投影节点的梯度尺度设置为0.5。对于损失函数中的比例因子
(
w
,
b
)
(w, b)
(w,b),我们也观察到一个较好的初始值是
(
w
,
b
)
=
(
10
,
5
)
(w, b) =(10,5)
(w,b)=(10,5),在它们上的梯度尺度为
0.01
0.01
0.01较小,有助于平滑收敛。
3.1 依赖文本的说话人验证
虽然现有的语音助手通常只支持一个关键字,但研究表明,用户喜欢同时支持多个关键字。对于谷歌Home上的多用户,同时支持两个关键字: “OK Google” 和 “Hey Google”。
启用多个关键字的说话人验证介于TD-SV和TI-SV之间,因为文本既不局限于单个短语,也不完全不受限制。我们使用MultiReader技术来解决这个问题(第2.3节)。与直接混合多个数据源的简单方法相比,MultiReader有一个很大的优势:它可以处理不同数据源在大小上不平衡的情况。在我们的示例中,我们有两个用于训练的数据源:1)一个“OK Google”训练集,来自匿名用户查询,有约150M条语音和约630K个说话人;2)一个混合的“OK/Hey Google”训练集,手动收集约1.2M条语音和约18K个说话人。第一个数据集比第二个数据集大125倍,说话人数量大35倍。
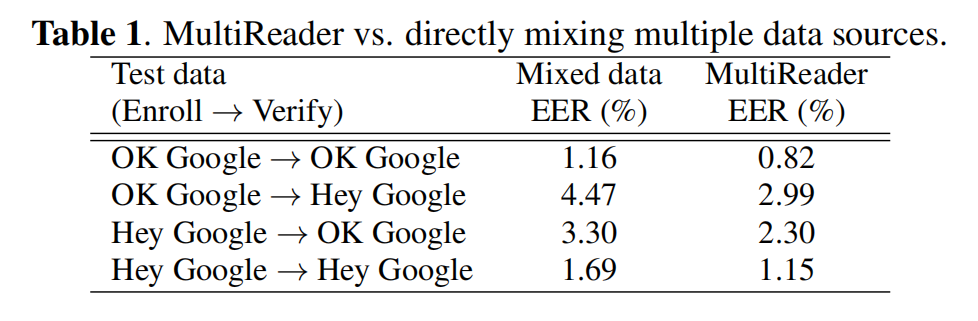
为了进行评估,我们报告了四种情况下的平均错误率(EER):使用任意一个关键字进行登记,并对任意一个关键字进行验证。所有评价数据集都是从665个说话人手动收集的,平均每个说话人有4.5个登记语音和10个评价语音。结果如表1所示。正如我们所看到的,MultiReader为这四种情况带来了30%的相对改善。
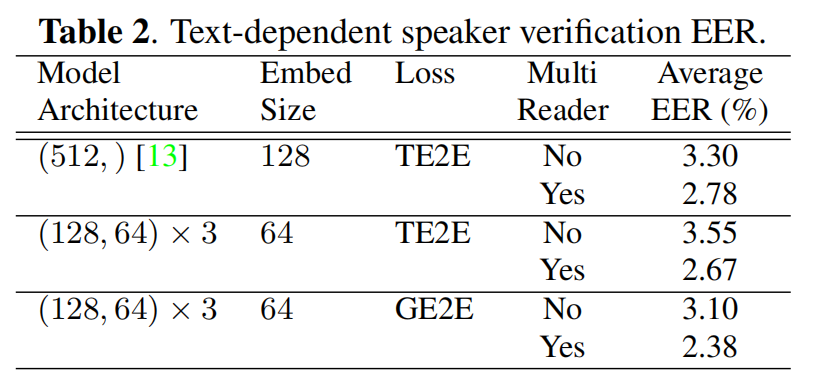
我们还在一个更大的数据集中进行了更全面的评估,该数据集收集了约83K不同的说话人和环境条件,包括匿名日志和手动收集。我们平均每人使用7.3个登记语音和5个评价语音。表2总结了使用和不使用MultiReader设置训练的不同损失函数的平均EER值。基线模型是一个单层LSTM,有512个节点,嵌入向量大小为128(《End-to-end text-dependent speaker verification》)。第二和第三行模型体系结构是3层LSTM。比较第2行和第3行,我们看到GE2E比TE2E好10%左右。与表1相似,这里我们也看到模型在使用MultiReader时性能显著提高。虽然表中没有显示,但同样值得注意的是,GE2E模型比TE2E花的训练时间少约60%。
3.2 文本无关的说话人验证
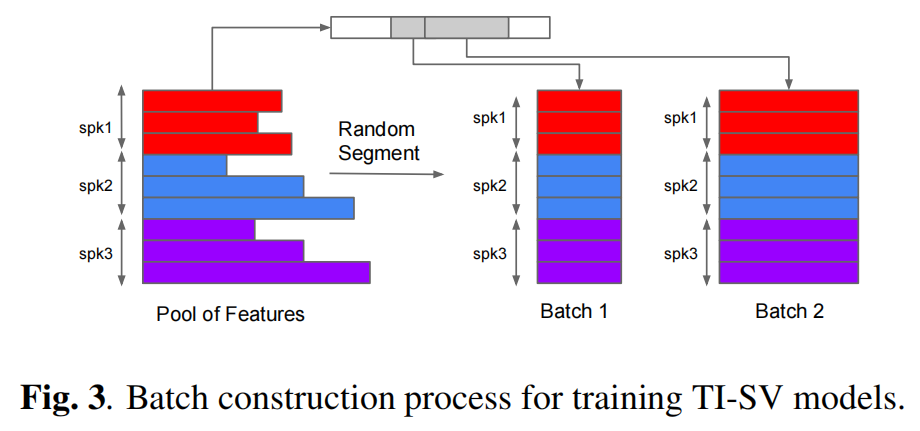
对于TI-SV训练,我们将训练话语分成更小的片段,我们称之为部分话语。虽然我们不要求所有的部分话语都是相同的长度,但在同一批中的所有部分话语必须是相同的长度。因此,对于每批数据,我们在 [ l b , u b ] = [ 140 , 180 ] [lb, ub] =[140, 180] [lb,ub]=[140,180]帧内随机选择时间长度 t t t,并强制该批中的所有部分话语长度为 t t t(如图3所示)。
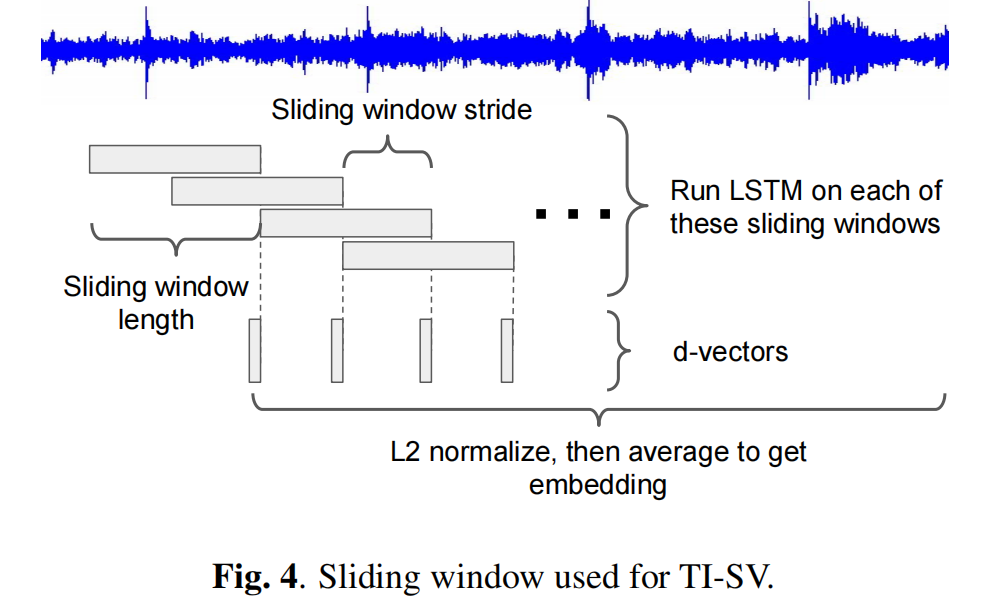
在推理期间,我们对每一个话语应用一个固定大小 ( l b + u b ) / 2 = 160 (lb + ub)/2 = 160 (lb+ub)/2=160帧的滑动窗口,其中 50 % 50\% 50%重叠。我们计算每个窗口的d向量。最终的话语层面的d-vector是由L2规范化窗口层面的d-vector,然后取元素层面的平均值(如图4所示)。
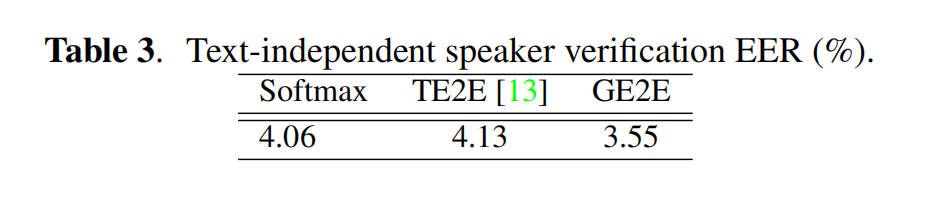
我们的TI-SV模型训练了来自18K说话人的大约36M条语音,这些话语是从匿名日志中提取出来的。对于评估,我们使用额外的1000个说话人,平均每个说话人6.3个注册语音和7.2个评价语音。表3显示了不同训练损失函数的性能比较。第一列是softmax,它预测训练数据中所有说话人的说话人标签。第二列是用TE2E损失训练的模型。第三列是使用GE2E损失训练的模型。从表中可以看出,GE2E的性能优于softmax和TE2E。EER性能改进大于 10 % 10\% 10%。此外,我们还观察到GE2E训练比其他损失函数快 3 × 3 \times 3×个左右。
4 结论
在本文中,我们提出了广义端到端(GE2E)损失函数来更有效地训练说话人验证模型。理论和实验结果都验证了这种新的损失函数的优越性。我们还介绍了MultiReader技术来组合不同的数据源,使我们的模型能够支持多个关键字和多种语言。通过结合这两种技术,我们产生了更准确的说话人验证模型。
Wan L, Wang Q, Papir A, et al. Generalized end-to-end loss for speaker verification[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 4879-4883.

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









