






论文主要工作
- 首次将clip用于reid任务。
- 提出了clip-reid,充分挖掘clip跨模型表达能力。在clip-reid中,每个id独立的token与模糊的文本描述集合,通过一个2stage的训练策略训练文本编码器。
- 证明clip-reid在多个reid数据集(行人/汽车)到达sota结果。
训练流程

简要描述训练过程:
- 将一个batch的图像以及对应的文本作为输入。 基于每个训练集中的id设置一系列可学习的文本tokens(x1, x2,…,xm)。
- 设定一个图像编码器和文本编码器,以及线性层gv和gt。
- 下载预训练clip模型,初始化两个编码器、线性层,随机初始化可学习的文本token。
- 在第一stage训练时,计算文本与图像特征编码器的相似度。
- 通过eq5的损失函数前向传播优化,这一阶段只训练文本token,text encoder也是frozen的。
- 在第二stage训练,frozen文本token,只训练图像编码。
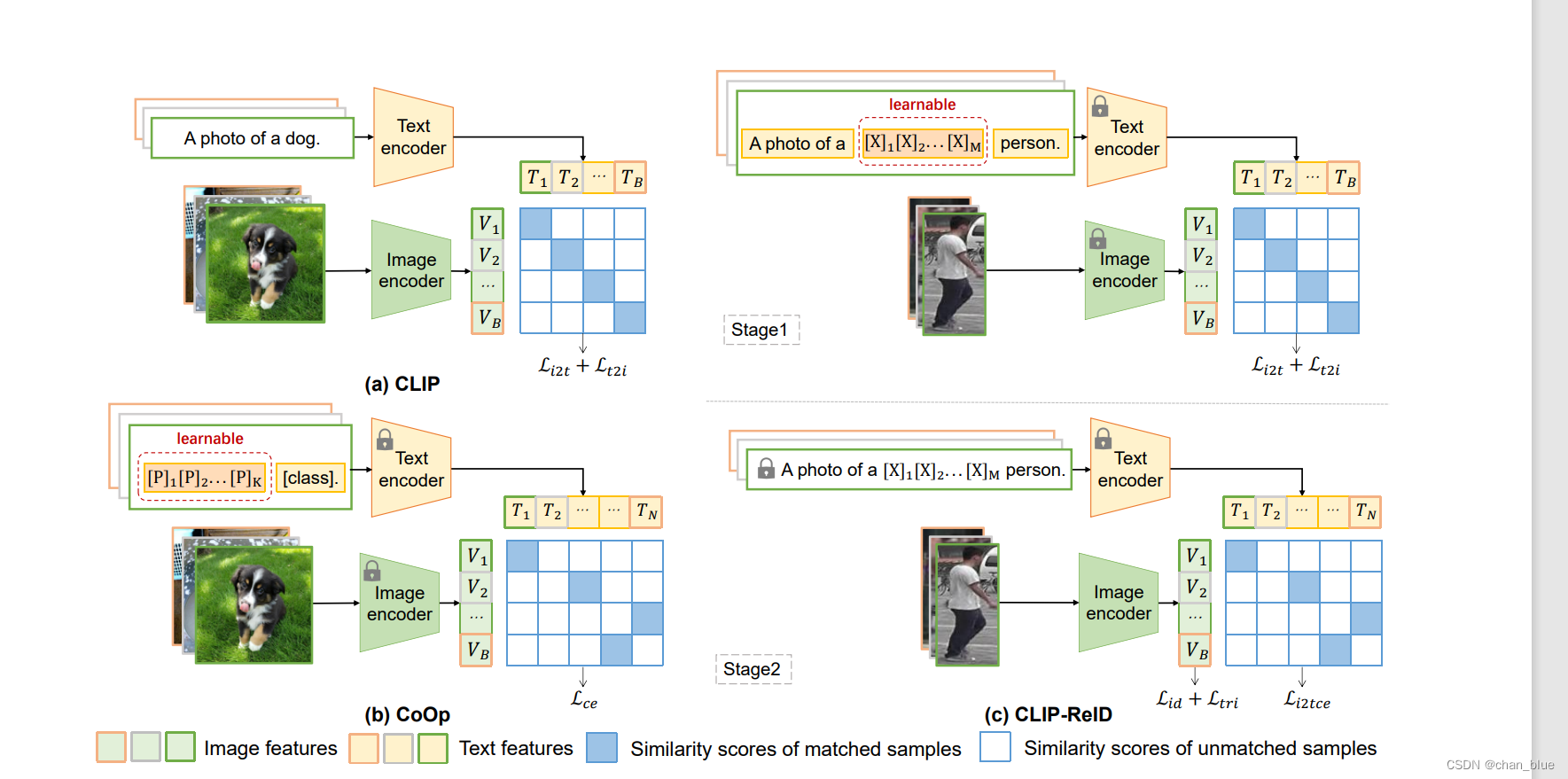
Clip-Reid算法框架
作者说明该算法的codebase为transReid、clip和CoOp。文章中将该算法与clip、CoOp进行了个对比,图画的蛮漂亮。
**
**
主要说下clip-reid的不同之处:
- 借鉴了clip和coop的text 和image encoder,将完整语句替换为语义模糊的句子,每个句子长度是fixed,中间图像的描述词语是learnable tokens,这个作者做过实验,用四个token学习是效果最好的。
- stage1:text 和image encoder都是frozen的,只输入learnable的token送入text encoder学习,image encoder是采用imagenet预训练的模型,将数据送入encoder,只优化tokens。(A photo of x x x x person.)这个阶段与clip处理方法一致,用损失函数Loss(img2text)和Loss(text2img)。此外,在Loss(text2img),在同一batch的不同图像很可能属于同一个行人id,所以对loss进行了优化:
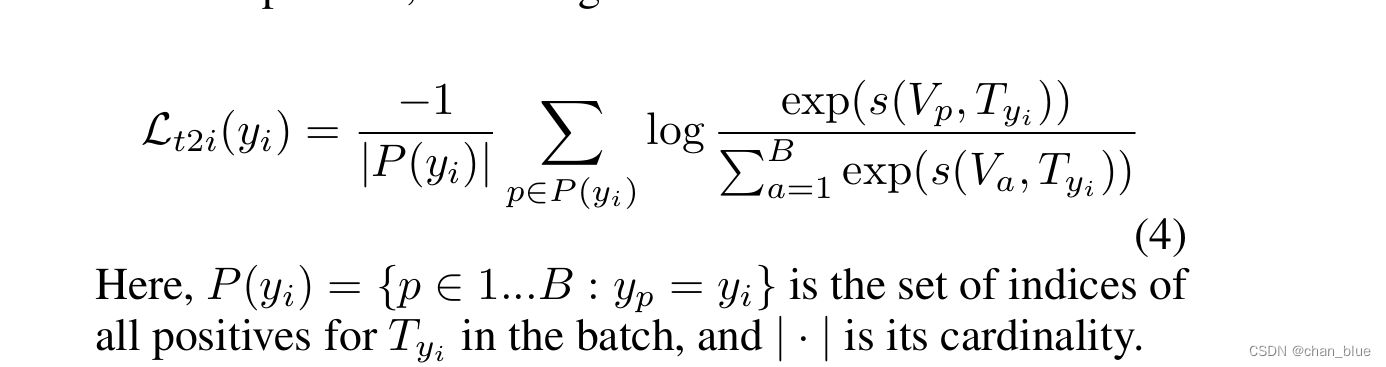
- stage2:该训练阶段只有image encoder中的参数进行优化。reid部分代码借鉴object reid,用triplet loss和加入label smooth 的id loss进行优化。为了充分利用clip,就用第一阶段的文本特征计算img2text的交叉熵。这一部分也粘贴下调试过程中的重点部分:
#processor/process_clipreid_stage2.py --line:55
#train
batch = cfg.SOLVER.STAGE2.IMS_PER_BATCH
i_ter = num_classes // batch
left = num_classes-batch* (num_classes//batch)
if left != 0 :
i_ter = i_ter+1
text_features = []
# text feature extract
with torch.no_grad():
for i in range(i_ter):
if i+1 != i_ter:
l_list = torch.arange(i*batch, (i+1)* batch)
else:
l_list = torch.arange(i*batch, num_classes)
with amp.autocast(enabled=True):
text_feature = model(label = l_list, get_text = True)
text_features.append(text_feature.cpu())
text_features = torch.cat(text_features, 0).cuda()
#image encoder optimize
for epoch in range(1, epochs + 1):
start_time = time.time()
loss_meter.reset()
acc_meter.reset()
evaluator.reset()
scheduler.step()
model.train()
for n_iter, (img, vid, target_cam, target_view) in enumerate(train_loader_stage2):
optimizer.zero_grad()
optimizer_center.zero_grad()
img = img.to(device)
target = vid.to(device)
if cfg.MODEL.SIE_CAMERA:
target_cam = target_cam.to(device)
else:
target_cam = None
if cfg.MODEL.SIE_VIEW:
target_view = target_view.to(device)
else:
target_view = None
with amp.autocast(enabled=True):
score, feat, image_features = model(x = img, label = target, cam_label=target_cam, view_label=target_view)
#image-text match
logits = image_features @ text_features.t()
loss = loss_fn(score, feat, target, target_cam, logits)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
if 'center' in cfg.MODEL.METRIC_LOSS_TYPE:
for param in center_criterion.parameters():
param.grad.data *= (1. / cfg.SOLVER.CENTER_LOSS_WEIGHT)
scaler.step(optimizer_center)
scaler.update()
acc = (logits.max(1)[1] == target).float().mean()
由于我训练的数据集较大,stage2常因为内存出问题,因此直接将stage1部分的模型保存。再次训练时,跳过1st的训练,load模型权重,直接进行2次训练,非常节省时间。
0516补充
网络部署
图像和文本的特征提取用的CLIP的visual encoder和text encoder,并且提供了两种方式:(1)transformer(vit-B16);(2)CNN以及global attention。训练细节包含学习率、warmingup策略设置、batch_size以及num_instance,推荐阅读原文和代码。
实验结果分析
- 两阶训练的必要性:CLIP可以融合文本和图像领域的嵌入特征。由于Reid数据集不会给不同的人id给特定的文本分析,因此该算法提供了被与训练过的一系列可学习的tokens。在第一阶段训练中,在训练image encoder的同时用对比损失训练text tokens。在第二阶段,将第一阶段训练的text tokens用来计算图像与文本匹配的交叉熵损失。消融实验的结果表明,可学习的text tokens虽然不能描述图像,但是会影响到image encoder的优化。
- 分析损失函数的权重:在stage2训练中,text encoder被冻,损失函数由id的交叉熵损失、triplet loss和image2text损失构成,在vit中,将各损失函数的权重设置为1、1、0.25;CNN设置为1、1和1。
代码调试
这个项目的代码并不难调,复现应该是比较简单的。但是分布式训练写的代码不太好,特别是load数据部分,百万数据集竟能load6个小时,后面根据fast reid的框架进行了修改,同时修改了num_workers,才稍好一点。就结果而言,在我配置的环境和自己的训练集,效果并没有fast reid好,但也有可能是没有加很多的数据增强,以及SIE信息没有加入。后续如果有很大的提升tricks会继续补充。或者后续将该训练策略移植到fast reid上做做对比实验,观察实验效果。
240605补充:
1 数据增强加了效果不好。分析原因:clip训练时只用了简单的数据增强,在finetune时使用一致的数据增强更容易收敛。
2将text_prompt部分移植到fast reid上,二阶段没用clip的visual部分,而是用了backbone+head与text prompt对齐,效果不如单纯backbone+head。


















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









