







论文
code(pytorch部署,简易可读版本,个人调试的是这个版本)
论文阅读
论文主要提出了一个cycle-gan,实现图像风格迁移的工作。创新点在于图像迁移项目中并没有很多paired data可进行训练,unpaired图像对更多一点。但是我们又想生成图像,就是要学习一个映射:使图像X很像图像Y。由于这个mapping是非常严苛的,因此可以同时学习一个逆映射使Y非常像X。同时,引入了一个循环一致损失函数(cycle consistency loss)进行优化。该技术可以用于多项领域,泛化能力强。
准备的数据是unpaired data。可以看出paired data间存在着联系,而unpaired data中x和y之间并没有其他的信息。
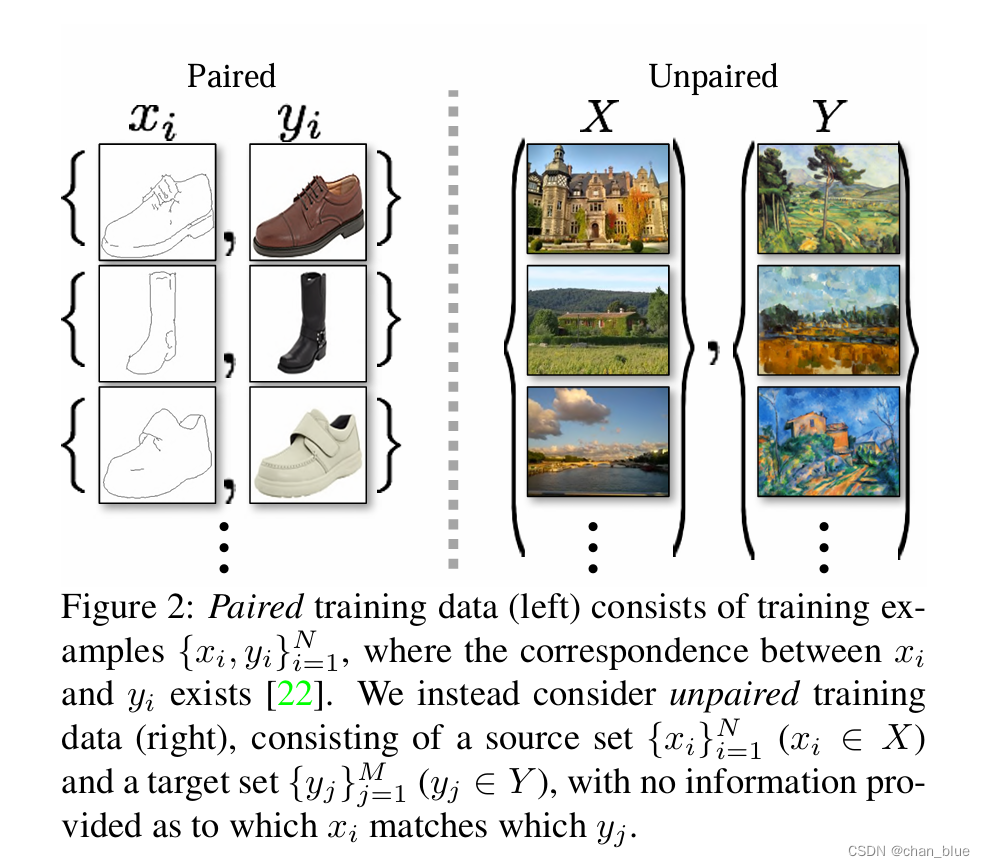
所以目标在于学习两个映射G(x)和F(y)以及对抗性判别器,论文的图示很清晰的说明了这点。同时,为进一步将这个映射正则化,引入了2个循环一致性损失函数进行对抗性网络。图三建议与第三部分公式一起看,主要是优化目标函数。
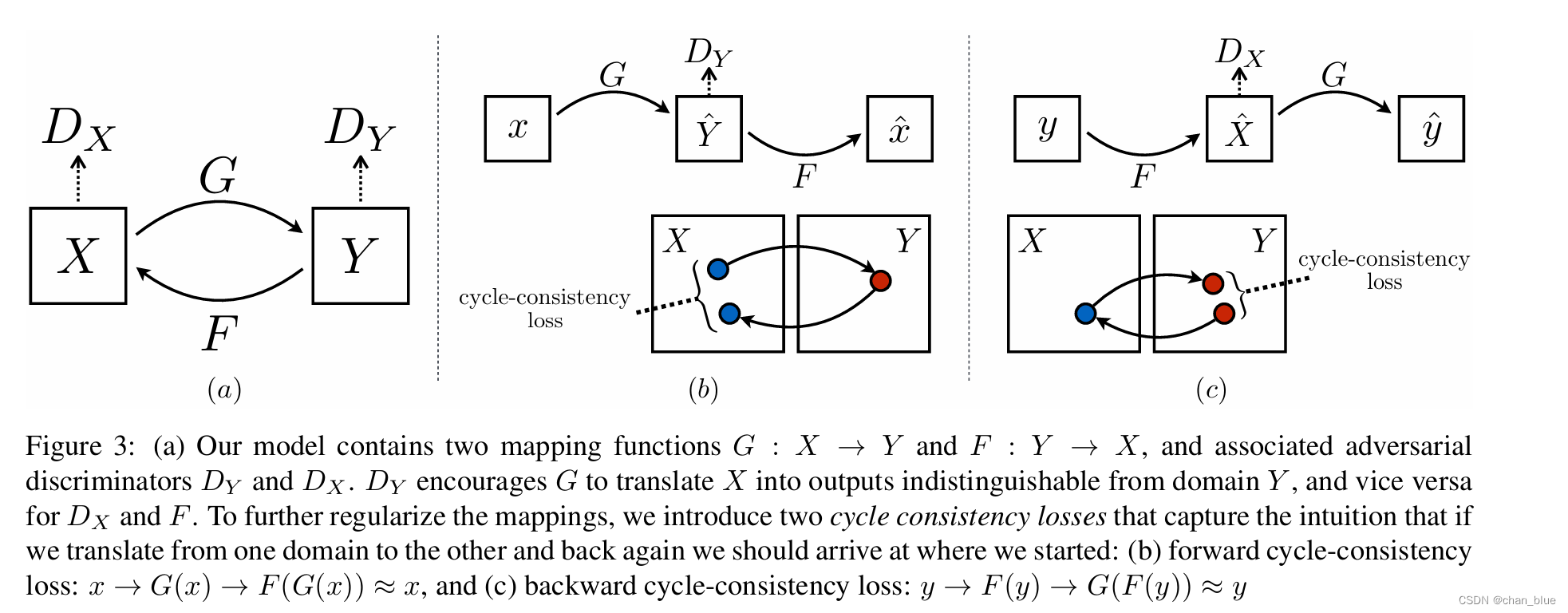
网络架构
借鉴了Johnson的GNN网络架构,根据代码说明一下。loss中的参数设定在原文中的training details,如有需要自行阅读。
#n_residual_blocks: for 128*128 training images, use 6 blocks; for 256*256 training images, use 9 blocks, please feel free to set this hyper-parameter.
class Generator(nn.Module):
def __init__(self, input_nc, output_nc, n_residual_blocks=9):
super(Generator, self).__init__()
# Initial convolution block
model = [ nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True) ]
# Downsampling
in_features = 64
out_features = in_features*2
#paper content: including 3 convs,several residual, use instancenorm
for _ in range(2):
model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features*2
# Residual blocks
for _ in range(n_residual_blocks):
model += [ResidualBlock(in_features)]
# Upsampling, paper content: two fractionally-strided convs with stride 1/2
out_features = in_features//2
for _ in range(2):
model += [ nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features//2
# Output layer, paper content: one conv maps feature to rgb
model += [ nn.ReflectionPad2d(3),
nn.Conv2d(64, output_nc, 7),
nn.Tanh() ]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
对抗性判别器部分
class Discriminator(nn.Module):
def __init__(self, input_nc):
super(Discriminator, self).__init__()
# A bunch of convolutions one after another
model = [ nn.Conv2d(input_nc, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(256, 512, 4, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True) ]
# FCN classification layer
model += [nn.Conv2d(512, 1, 4, padding=1)]
self.model = nn.Sequential(*model)
def forward(self, x):
x = self.model(x)
# Average pooling and flatten
return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)
损失函数部分:
# Lossess,initialize
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
# Identity loss
# G_A2B(B) should equal B if real B is fed, F(G(x))≈x, therefore calculate MAE
same_B = netG_A2B(real_B)
loss_identity_B = criterion_identity(same_B, real_B)*5.0
# G_B2A(A) should equal A if real A is fed
same_A = netG_B2A(real_A)
loss_identity_A = criterion_identity(same_A, real_A)*5.0
# GAN loss, fake images use MSE to calculate loss
fake_B = netG_A2B(real_A)
pred_fake = netD_B(fake_B)
loss_GAN_A2B = criterion_GAN(pred_fake, target_real)
fake_A = netG_B2A(real_B)
pred_fake = netD_A(fake_A)
loss_GAN_B2A = criterion_GAN(pred_fake, target_real)
# Cycle loss, for example, whether recovered A equals A, therefore also use MAE
recovered_A = netG_B2A(fake_B)
loss_cycle_ABA = criterion_cycle(recovered_A, real_A)*10.0
recovered_B = netG_A2B(fake_A)
loss_cycle_BAB = criterion_cycle(recovered_B, real_B)*10.0
# Total loss
loss_G = loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB
loss_G.backward()
实验分析
在section5对实验结果进行了分析。对于loss func而言,做了消融实验,分别移除了GAN和cycle-consistency loss,然后也做了GAN+前向cycle/GAN+后向cycle。实验结果表明,这样会使训练不稳定,可以看下对比图。

调试经验
这个代码也是蛮好调的,用monet2photo数据集先进行了下复现,batchsize设为1就导致训练速度还是比较慢……对数据量要求低,所以还要什么自行车呢。用自己的数据集进行训练,效果还行,但是我的数据集大小不一致,因此在test脚本中还是需要在transform_中加入resize和crop(这里换成了centercrop,还会进行下一步优化),有些图像被crop掉了不完整,后面会进行优化下做对比实验。以及code中用visdom有点鸡肋,如果不用可以注释掉。后续有进一步优化的tricks会继续补充。
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









