







本文节选自我的博客:AI 作诗 (附源码)
- 💖 作者简介:大家好,我是MilesChen,偏前端的全栈开发者。
- 📝 CSDN主页:爱吃糖的猫🔥
- 📣 我的博客:爱吃糖的猫
- 📚 Github主页: MilesChen
- 🎉 支持我:点赞👍+收藏⭐️+留言📝
- 💬介绍:The mixture of WEB+DeepLearning+Iot+anything🍁
前言
使用RNN生成古诗,你给它输入一堆古诗词,它会学着生成和前面相关联的字词。如果你给它输入一堆姓名,它会学着生成姓名;给它输入一堆古典乐/歌词,它会学着生成古典乐/歌词,让电脑可以向人一样做诗。

原理
了解RNN
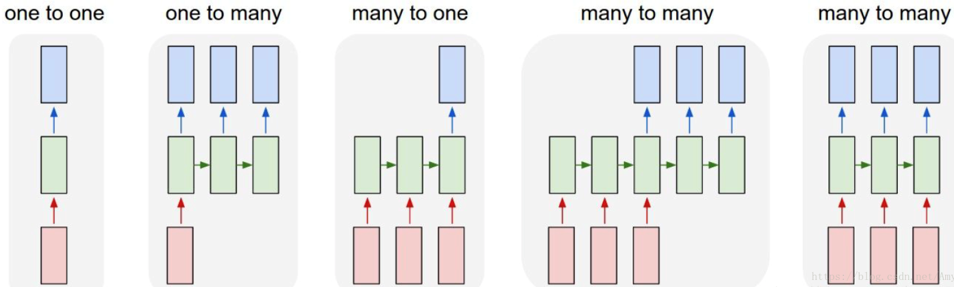
循环神经网络主要应用于序列数据的处理,因输入与输出数据之间有时间上的关联性,所以在常规神经网络的基础上,加上了时间维度上的关联性,也就是有了循环神经网络。因此对于循环神经网络而言,它能够记录很长时间的历史信息,即使在某一时刻有相同的输入,但由于历史信息不同,也会得到不同的输出,这也是循环神经网络相比于常规网络的不同之处。根据输入与输出之间的对应关系,可以将循环神经网络分为以下五大类别:
古诗生成RNN
基于字符集的文本生成原理可以这样简单理解:
- 将一个长文本序列依次输入到循环神经网络
- 对于给定前缀序列的序列数据,对序列中将要出现的下一个字符的概率分布建立模型
- 这样就可以每次产生一个新的字符
训练过程
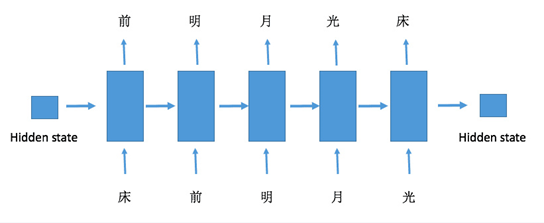
前面我们介绍过 RNN 的输入和输出存在多种关系,比如一对多,多对多等等,不同的输入对应着不同的应用,比如多对多可以用来做机器翻译等等,今天我们要讲的 Char RNN 在训练网络的时候是一个相同长度的多对多类型,也就是输入一个序列,输出一个吸纳共同长度的序列。
具体的网络训练过程如下:
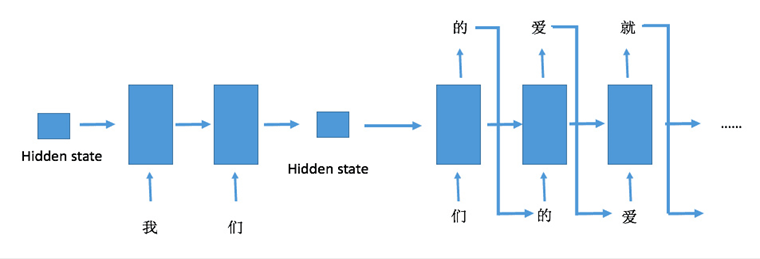
生成文本:
首先需要输入网络一段初始的序列进行预热,预热的过程并不需要实际的输出结果,只是为了生成拥有记忆效果的隐藏状态,并将隐藏状态保留下来,接着我们开始正式生成文本,不断地生成新的句子,这个过程是可以无限循环下去,或者到达我们的要求输出长度,具体可以看看下面
代码解析
目录结构

文本预处理
把文本文件进行字符编码并且建立数据集。
class TextConverter(object):
def __init__(self, text_path, max_vocab=5000):
with codecs.open(text_path, mode='r', encoding='utf-8') as f:
text_file = f.readlines()
word_list = [v for s in text_file for v in s]
vocab = set(word_list)
# 如果单词超过最长限制,则按单词出现频率去掉最小的部分
vocab_count = {}
for word in vocab:
vocab_count[word] = 0
for word in word_list:
vocab_count[word] += 1
vocab_count_list = []
for word in vocab_count:
vocab_count_list.append((word, vocab_count[word]))
vocab_count_list.sort(key=lambda x: x[1], reverse=True)
if len(vocab_count_list) > max_vocab:
vocab_count_list = vocab_count_list[:max_vocab]
vocab = [x[0] for x in vocab_count_list]
self.vocab = vocab
self.word_to_int_table = {c: i for i, c in enumerate(self.vocab)}
self.int_to_word_table = dict(enumerate(self.vocab))
@property
def vocab_size(self):
return len(self.vocab) + 1
def word_to_int(self, word):
if word in self.word_to_int_table:
return self.word_to_int_table[word]
else:
return len(self.vocab)
def int_to_word(self, index):
if index == len(self.vocab):
return '<unk>'
elif index < len(self.vocab):
return self.int_to_word_table[index]
else:
raise Exception('Unknow index!')
def text_to_arr(self, text):
arr = []
for word in text:
arr.append(self.word_to_int(word))
return np.array(arr)
def arr_to_text(self, arr):
words = []
for index in arr:
words.append(self.int_to_word(index))
return "".join(words)
模型结构
class CharRNN(g.Block):
def __init__(self, num_classes, embed_dim, hidden_size, num_layers,
dropout):
super(CharRNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
with self.name_scope():
self.word_to_vec = g.nn.Embedding(num_classes, embed_dim)
self.rnn = g.rnn.GRU(hidden_size, num_layers, dropout=dropout)
self.proj = g.nn.Dense(num_classes)
def forward(self, x, hs=None):
batch = x.shape[0]
if hs is None:
hs = nd.zeros(
(self.num_layers, batch, self.hidden_size), ctx=mx.gpu())
word_embed = self.word_to_vec(x) # batch x len x embed
word_embed = word_embed.transpose((1, 0, 2)) # len x batch x embed
out, h0 = self.rnn(word_embed, hs) # len x batch x hidden
le, mb, hd = out.shape
out = out.reshape((le * mb, hd))
out = self.proj(out)
out = out.reshape((le, mb, -1))
out = out.transpose((1, 0, 2)) # batch x len x hidden
return out.reshape((-1, out.shape[2])), h0
测试
成功训练之后,用parse传入‘test’命令开始让电脑作诗。
def sample(ctx, model, checkpoint, convert, arr_to_text, prime, text_len=20):
'''
将载入好权重的模型读入,指定开始字符和长度进行生成,将生成的结果保存到txt文件中
checkpoint: 载入的模型
convert: 文本和下标转换
prime: 起始文本
text_len: 生成文本长度
'''
model.load_params(checkpoint, ctx=ctx)
samples = [convert(c) for c in prime]
input_txt = nd.array(samples).reshape((-1 ,1)).as_in_context(ctx)
embed = model[0](input_txt)
hs = nd.zeros(model[1].state_info(1)[0]['shape'], ctx=ctx)
_, init_state = model[1](embed, hs)
result = samples
model_input = input_txt[:, input_txt.shape[1] - 1].reshape((-1, 1))
for i in range(text_len):
# out是输出的字符,大小为1 x vocab
# init_state是RNN传递的hidden state
with mx.autograd.predict_mode():
embed = model[0](model_input)
out, init_state = model[1](embed, init_state)
out = model[2](out)
pred = pick_top_n(out)
model_input = nd.array(pred).reshape((-1, 1)).as_in_context(ctx)
result.append(pred[0])
return arr_to_text(result)
效果
用古诗作为训练集,输入字符“我”,得到下面的结果:

总结
源码点这,本本环境使用的pytorch1.1,其他版应该也是兼容的。
常规网络中的输入与输出大多是向量与向量之间的关联,不考虑时间上的联系,而在循环神经网络中,输入与输出之间大多是序列与序列(Sequence-to-Sequence.)之间的联系,也就产生了多种模式。
- 一对一(one to one):最为简单的反向传播网络。
- 一对多(one to many):可用于图像捕捉(image captioning),将图像转换为文字。
- 多对一(many to one):常用于情感分析(sentiment analysis),将一句话中归为具体的情感类别。
- 多对多( many to many):常用于输入输出序列长度不确定时,例如机器翻译(machine translate),实质是两个神经网络的叠加。不确定长度的多对多(many to many)(最右方):常用于语音识别(speech recognition)中,输入与输出序列等长。
如果你觉得本文对你有所帮助,别忘记给我点个start,有任何疑问和想法,欢迎在评论区与我交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









