









1 MR Reduce端join
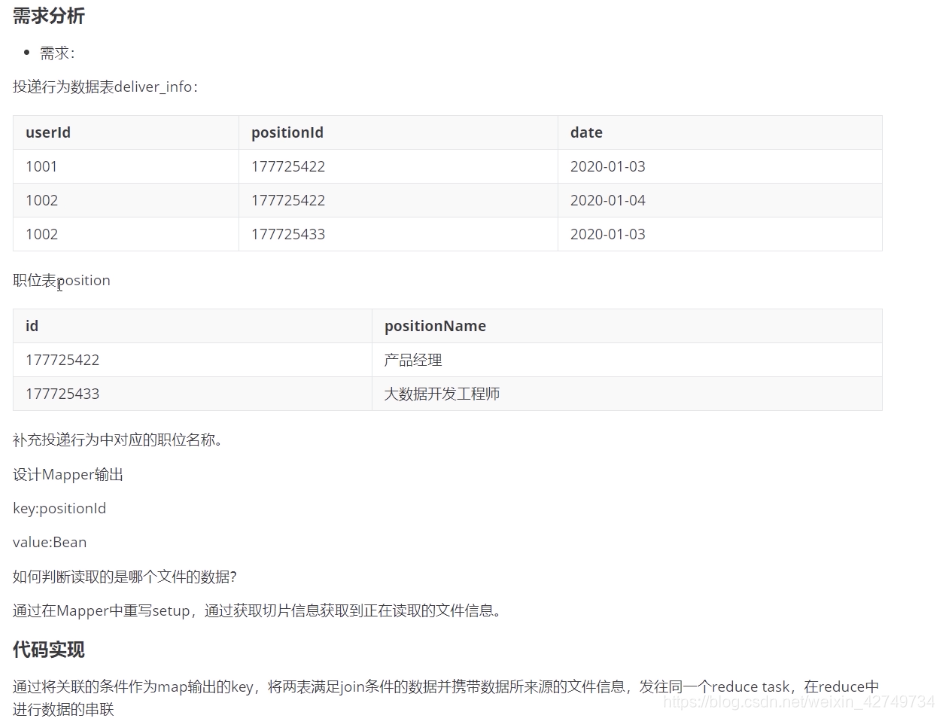
代码实现
Bean
package com.lagou.join;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class JoinBean implements Writable {
private String userId;
private String positionId;
private String date;
private String positionName;
// 判断是投递数据,还是职位数据
private String flag;
public JoinBean() {
}
public JoinBean(String userId, String positionId, String date, String positionName, String flag) {
this.userId = userId;
this.positionId = positionId;
this.date = date;
this.positionName = positionName;
this.flag = flag;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getPositionId() {
return positionId;
}
public void setPositionId(String positionId) {
this.positionId = positionId;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getPositionName() {
return positionName;
}
public void setPositionName(String positionName) {
this.positionName = positionName;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(userId);
out.writeUTF(positionId);
out.writeUTF(date);
out.writeUTF(positionName);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.userId=in.readUTF();
this.positionId=in.readUTF();
this.date=in.readUTF();
this.positionName=in.readUTF();
this.flag =in.readUTF();
}
@Override
public String toString() {
return
userId +
"\t" + positionId +
",\t" + date +
"\t" + positionName +
"\t" + flag ;
}
}
Mapper
package com.lagou.join;
import jdk.nashorn.internal.ir.CallNode;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class JoinMapper extends Mapper<LongWritable, Text,Text,JoinBean> {
String name="";
Text k=new Text();
JoinBean bean = new JoinBean();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
InputSplit inputSplit = context.getInputSplit();
FileSplit split=(FileSplit)inputSplit;
name=split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split("\t");
if (name.startsWith("deliver_info")){
bean.setUserId(arr[0]);
bean.setPositionId(arr[1]);
bean.setDate(arr[2]);
// 先置为空
bean.setPositionName("");
bean.setFlag("deliver");
}else {
bean.setUserId("");
bean.setPositionId(arr[0]);
bean.setDate("");
// 先置为空
bean.setPositionName(arr[1]);
bean.setFlag("position");
}
k.set(bean.getPositionId());
context.write(k,bean);
}
}
Reduce
package com.lagou.join;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
public class JoinReduce extends Reducer<Text,JoinBean,JoinBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<JoinBean> values, Context context) throws IOException, InterruptedException {
// 相同position的bean对象放在一起了(1个职位,多个投递行为数据)
ArrayList<JoinBean> joinBean=new ArrayList<>();
JoinBean positionBean = new JoinBean();
for (JoinBean bean : values) {
String flag = bean.getFlag();
if(flag.equalsIgnoreCase("deliver")){
// 投递行为数据
// 此处不能直接把bean对象添加到JoinBean,需要深度拷贝
JoinBean newBean = new JoinBean();
try {
BeanUtils.copyProperties(newBean,bean);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}else{
// 职位
try {
BeanUtils.copyProperties(positionBean,bean);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
// 遍历投递行为数据并拼接positionname
for (JoinBean bean : joinBean) {
bean.setPositionName(positionBean.getPositionName());
context.write(bean,NullWritable.get());
}
}
}
driver
package com.lagou.join;
import com.lagou.homework.HMapper;
import com.lagou.homework.HReducer;
import com.lagou.homework.Hdriver2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class JoinDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "JoinDriver");
job.setJarByClass(JoinDriver.class);
job.setMapperClass(JoinMapper.class);
job.setReducerClass(JoinReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(JoinBean.class);
job.setOutputKeyClass(JoinBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean flag = job.waitForCompletion(true);
System.out.println(flag?0:1);
}
}
Reduce端join的缺点
缺点:
- 数据聚合功能是在Reduce端完成,Reduce并行度一般不高,所以执行效率存在隐患
- 相同position的数据去完同一分区。如果数据本身存在不平衡,会造成大数据中最常见的一个问题:数据倾斜问题
解决:使用Map端join实现
2 MR map端join

- 使用map端join完成投递行为与职位数据的关联
- map端缓存所有职位数据
- map方法读取的文件数据是投递行为数据
- 基于投递行为数据的positionid去缓存中查询出positionname,输出即可
- 这个job中无需reducetask,setnumreducetask为0
package com.lagou.mapjoin;
import jdk.nashorn.internal.ir.CallNode;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
public class MapJoinMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
Text k=new Text();
HashMap<String,String> map=new HashMap<>();
// 加载职位数据
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 读取缓存数据
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream("position.txt"), "UTF-8");
BufferedReader reader = new BufferedReader(inputStreamReader);
// 读取职位数据,解析为k,v类型(hashmap);key:positionid,value:positionname
String line;
while(StringUtils.isNoneEmpty(line=reader.readLine())){
String[] fields = line.split("\t");
map.put(fields[0],fields[1]);
}
reader.lines();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split("\t");
// 都是投递行为数据
String positionName = map.get(arr[1]);
k.set(line+"\t"+positionName);
context.write(k,NullWritable.get());
}
}
package com.lagou.mapjoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class MapJoinDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "MapJoinDriver");
job.setJarByClass(MapJoinDriver.class);
job.setMapperClass(MapJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 设置加载缓存文件
job.addCacheFile(URI.create("file:///E:/cache/position.txt"));
// setNumReduceTasks为0
job.setNumReduceTasks(0);
boolean flag = job.waitForCompletion(true);
System.out.println(flag?0:1);
}
}
map端join避免了Reduce端数据倾斜的问题
3 数据倾斜解决方案
通用解决方法
对key增加随机数
以MR为例
第一阶段:对key增加随机数
第二阶段:去掉key的随机数
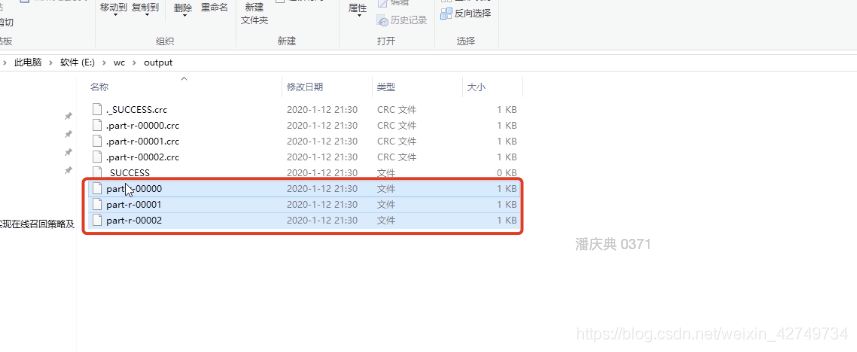
job2:增加一个随机数据,分成3个输出
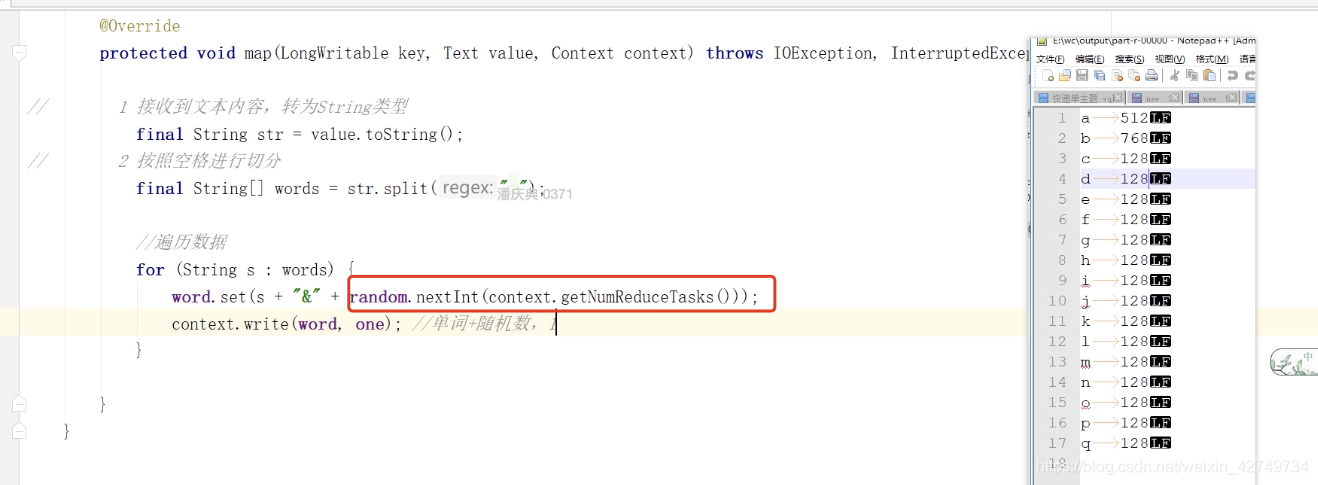
job2 输出三个文件
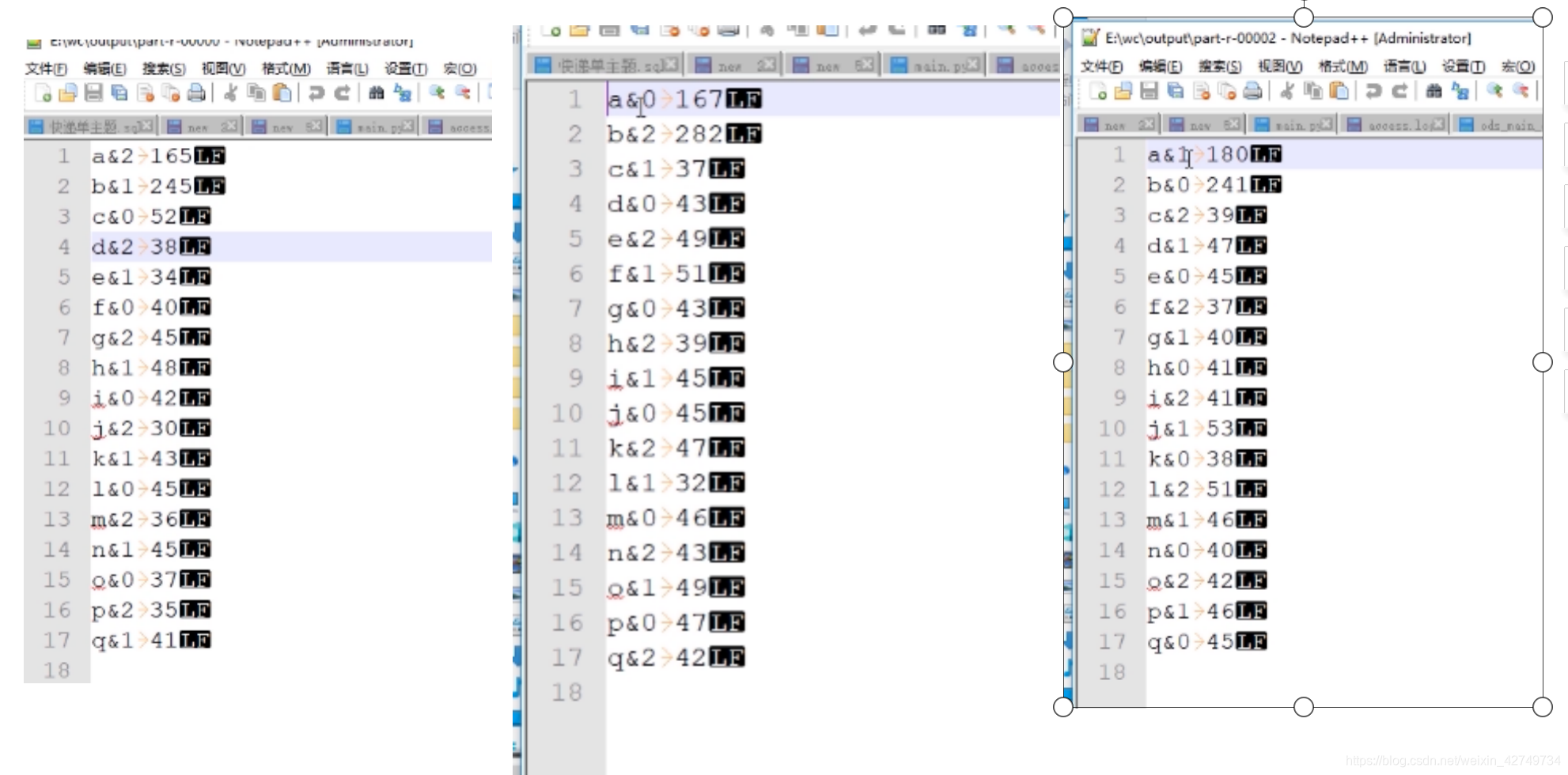
job2 输出的三个结果,比如a在三个文件都有出现
接下来job3要读取这三个数据,合并类似a这样的三个文本数据汇总到一个结果,此时a只有三条数据,相对其他一条数据,就不会数据倾斜














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









