







缘起
为什么要用缓存?
缓存是为了解决双方处理事务速率差异过大场景
CPU >> 高速缓存 >> 内存 >>外存

原理:程序访问的局部性原理
对大量典型程序运行情况分析的结果表明,在较短的时间间隔内,程序产生的地址往往集中在存储空间的一个很小范围,这种现象称为程序访问的局部性。
分类:时间局部性和空间局部性。
时间局部性:是指被访问的某个存储单元在一个较短的时间间隔很可能又被访问。
空间局部性:是指访问的某个存储单元的临近单元在一个较短的时间间隔内很可能也被访问。
既然缓存是解决访问效率上的问题,就应该了解每个组件应对并发量的支撑能力,才好知道哪是瓶颈,哪需要缓存?
性能分析
WEB中访问同MySQL响应之间的效率差异。
浏览器 >> Nginx >> Tomcat >> Redis >> 数据源 >> Mysql
指标
QPS: 每秒访问URL的数量
TPS: 每秒处理事务的数量,一个事务可以由多个URL组成。
例如,访问一个 Index 页面会请求服务器 3 次,包括一次 html,一次 css,一次 js,那么访问这一个页面就会产生一个“T”,产生三个“Q”。
Nginx
3W并发
OS操作系统
- 操作系统对于进程中的线程数有一定的限制:
- Windows 每个进程中的线程数不允许超过 2000
- Linux 每个进程中的线程数不允许超过 1000
- Java 中每开启一个线程需要耗用 1MB 的 JVM 内存空间用于作为线程栈之用
Tomcat
在Tomcat配置文件conf下面 server.xml:
- minProcessors:最小空闲连接线程数
- maxProcessors:最大连接线程数
- acceptCount:允许的最大连接数
Tomcat 默认配置的最大请求数是 150
当一个进程有 500 个线程在跑的话,那性能已经是很低很低了。
当某个应用拥有 250 个以上并发的时候,应考虑应用服务器的集群。
具体能承载多少并发,需要看硬件的配置,CPU 越多性能越高,分配给 JVM 的内存越多性能也就越高,但也会加重 GC 的负担。
SpringBoot Tomcat参数设置:
门口牌号的:accept-count的默认值为100
后厨同时做的:maxThreads默认200
线程数的经验值为: 1核2g内存为200,线程数经验值200;
4核8g内存,线程数经验值800
标准产品正式:通用g6:4核16G内存
大堂座位的:maxConnections 默认值是10000

Redis
小数据:可达到瞬间并发量10W+
Druid
单机:maxActive: 20
MySQL

说明:
1. 数据库 并发处理的事务越多,处理速率越慢
2. 还跟 内存,IO,CPU,数据库引擎 都有关系
3. 最大连接数:Docker版151,win下安装:200,云RDS版本:1700
4. MySQL连接数设置和标准:
支持的最大连接数:show variables like '%max_connections%';
使用过的最大连接数:show global status like 'Max_used_connections';
max_used_connections / max_connections * 100% (理想值≈ 85%)
并发最好是600,可以支持3000个TPS
WEB缓存
各级缓存机制
- 浏览器缓存
- CND缓存:在靠近用户的机器上放一些频繁访问的文件
- Nginx缓存
- Tomcat缓存
- WEB内部缓存:EhCache,ThreadLocal
- WEB分布式缓存:Redis, MongoDB, ElasticSearch
- ORM缓存(两级缓存机制)
- Mysql缓存
-
技术选型
- WEB分布式缓存:Redis, MongoDB, ElasticSearch
- Redis:比较通用
- MongoDB:文档型数据库
- ElasticSearch:搜索引擎
- 通用分布式缓存设计
-
需求引入
读多,更新少的场景
线上购物场景,看的多,买的少。

读:SELECT * from product where id = 1;
写:update product set price = 20 where id = 1;
读写流程:先在Redis中查,如果有直接返回(命中hit), 如果没有则查数据库(未命中miss),然后更新缓存,最后返回数据
缓存的命中率:请求缓存命中次数/总访问次数= hit/(hit+miss)
问题:价格变动时 怎么办?
1. 更新 数据库,然后更新Redis,还是先Redis,然后DB
2. 更新 数据库,淘汰Redis
还有一个问题:操作复杂了,对价格的操作得同时面对DB和缓存
更新缓存 VS 淘汰缓存
更新缓存:少了一次miss,直接能用
淘汰缓存:简单,读取的时候 再去加载缓存
本质加载缓存的位置,更新是更新是计算,淘汰是加载时计算。
场景1:如果数据复杂,价格是经过N个变量计算出的,此时只更新了一个变量。
更新缓存:需要查出其余 变量,执行计算,计算逻辑可能到处都是
淘汰缓存:查询时计算一次即可
场景2:如果数据很简单,就是一个数值。那么直接更新了反而省事。
淘汰缓存操作简单,并且带来的副作用只是增加了一次cache miss,作为通用的处理方式。
先操作数据库 vs 先操作缓存
假设淘汰缓存作为对缓存通用的处理方式,又面临两种抉择:
(1)先写数据库,再淘汰缓存
(2)先淘汰缓存,再写数据库
思路:如果出现不一致,谁先做对业务的影响较小,就谁先执行。
假设先写数据库,再淘汰缓存:
第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。
假设先淘汰缓存,再写数据库:
第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。
结论:数据和缓存的操作时序,结论是清楚的:先淘汰缓存,再写数据库。
缓存架构优化
上述缓存架构有一个缺点:业务方需要同时关注缓存与DB
有两种常见的方案:
1. 中间增加服务层:屏蔽对缓存和DB的操作。
2. 使用CDC(数据库增量日志补货)技术,读取DB增量日志,同步更新到缓存
数据一致性问题
先淘汰缓存有问题没?
如果线程A淘汰缓存成功,B线程读取发现没有,加载了一遍数据,此时A还没更新数据呢,出现了不一致。
如果主从DB,读写分离。同步数据会有延迟,及时A线程提交了事务,B也从从库读取不到最新数据。
问题本质1:读取的数据时 数据没有更新呢。
解决办法1:那么更新完再次淘汰一次缓存呢。
第二次淘汰缓存:
1. 在Service中同步进行
2. 抛出一个执行命令到MQ中
3. 使用CDC技术 进行淘汰
这又回到了那个问题:淘汰失败了呢?
问题本质2:更新数据的时候,可以读取
解决办法2:更新是锁住此行数据,读也候着
共享锁(读锁):select …… lock in share mode; 不让其他事务写
排他锁(写锁):select …… for update; 不让其他事务写,照样读
(明确指定主键,并且有此商品,必须走索引,否则是表锁,row lock)
SELECT * FROM product WHERE id=’3’ FOR UPDATE;
单独使用是不可以的。利用在排它锁上不能加其他锁的特征。
解决:写:
-- 设置不自动提交事务
set autocommit=0;
-- 开启事务
start transaction;
-- 获取排它锁
SELECT price from product where id = 1 for update;
-- 更新数据
update product set price = 23 where id = 1;
-- 提交事务
commit;读:
-- 获取共享锁
SELECT price from product where id = 1 lock in share mode;注意:
1.必须保证:读的时候 得获取 共享锁。
2.SELECT price from product where id = 1;是可以正常返回数据的。
3.如果读取出口多,架构上就需要优化。
数据一致性问题架构优化
如果出口太多,那么每个查询要避免读物造数据,就得添加共享锁,很容易忘。
方法:减少出口,减少到只有一个出口。
实施1:Mapper 统一出口,所有Service调用。
关联查询就从业务上避免吧,如果只是查看,那么延迟1S也无所谓。
特殊场景1:冷启动
系统刚启动,缓存没有数据着呢。那么所有请求都会打在DB上,会导致DB的瞬间瘫痪。
1. 预热:实现将一些数据加载到redis中
2. 加载缓存数据需要有个流量控制
2.1 加一个计数器
2.2 将所有加载缓存的操作 让MQ的订阅者完成,这样对DB操作入口统一,可以控制MQ的Handler梳理,进行削峰。
3. 冷启动实际是,缓存被击穿了,命中率为0了,导致所有请求直接打到DB,压力过大时会导致DB集群出现雪崩。
如果MQ执行有问题呢?
1. 失败消息建立重试机制
2. 缓存更新的报警机制,方便更新失败后进行“人工补救”
特殊场景2:缓存穿透问题
访问的数据压根不存在,缓存中就不可能加载此数据。那么每次都会从DB加载数据。这时缓存跟没有一样,被穿透了。
解决:布隆过滤器
布隆过滤器可以查出某个数据是否一定没有,但不能判断一定存在,也会有误判情况。
权限URI,如果某个URI没有,布隆过滤器可以判断出 该URI一定没有,那么也没必要查数据库了。如果出现少量的误判,此URI有,一查发现没有,也没关系,能过滤大部分没有URI就行了。
优化:将误判的URI在缓存中存储一段时间,比如5min。
布隆过滤器原理:
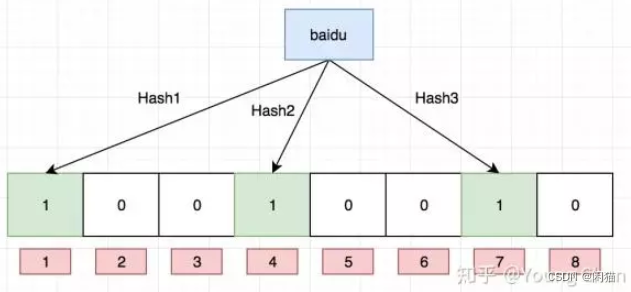
场景:
- DB中有数据:1,4,7
- hash算法:x%8+1,
- 将所有数据 加载到过滤器,如上图:
- 进来2 , hash(2)=3, 刚开始为空,那么一定没有
- 进来11,hash(11)=4, 4号位置为1,说明可能有,那么访问缓存吧
有啥问题没:
1. 布隆过滤器是时候加载呢
2. 如果用Lazy加载方式,更新是个问题
实际用的布隆过滤器比这复杂,不在细讲。
完整方案

END
















 40
40











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











