







这里写目录标题
类别不平衡问题
训练数据中某些类别的样本数量极多,而有些类别的样本数量极少,就是所谓的类不平衡(class-imbalance)问题。
比如说一个二分类问题,1000个训练样本,比较理想的情况是正类、负类样本的数量相差不多;而如果正类样本有995个、负类样本仅5个,就意味着存在类不平衡。
在后文中,把样本数量过少的类别称为“少数类”。
但实际上,数据集上的类不平衡到底有没有达到需要特殊处理的程度,还要看不处理时训练出来的模型在验证集上的效果。有些时候是没必要处理的。

“再缩放”这种方法,虽然看上去简单但是实现起来,有一个bug,就是该方法的假设“训练集是真实样本的无偏采样”一般是不成立的。也就是说通常无法通过训练集的数据分布推断出样本集的真实分布。
解决方法
1、再缩放
如上。
2、欠采样(undersampling)
直接对训练集的里的数量较多的类别进行欠采样,即抛弃一些样本从而缓解类别不平衡的问题。
3、过采样(oversampling)
增加(生成)一些样本数量较少的类别的样本,从而平衡样本数目。

Hard Negative Mining
对于样本类别不均衡的问题可以采用hard negative mining方法帮助我们训练。
hard negative mining顾名思义:negative,即负样本,其次是hard,说明是困难样本,也就是说在对负样本分类时候,loss比较大(label与prediction相差较大)的那些样本,也可以说是容易将负样本看成正样本的那些样本。
hard negative mining就是多找一些hard negative加入负样本集,进行训练,这样会比easy negative组成的负样本集效果更好。
hard negative mining思路在目标检测中的训练过程,简单来说有以下三个步骤:
1、目标检测中如何根据有标签的数据划分正负训练集?
用带标签的图像随机生成图像块,iou大于某一个阈值的图像块做为正样本,否则为负样本。但一般负样本远远多于正样本,为避免训练出来的模型会偏向预测为负例,需要保持样本均衡,所以初始负样本训练集需要选择负样本集的子集,一般正:负=1:3。
2、有了正负训练集就可以训练神经网络了。经过训练后,就可以用这个训练出的模型预测其余的负样本了(就是没有加入训练集的那些负样本)。模型在预测一张图像块后会给出其属于正负的概率,在这里设置一个阈值,预测为正的概率大于这个阈值(困难负样本),就可以把这个图像块加入负样本训练集了。
3.正样本训练集不变,负样本训练集除了初始的那些,还有新加入的。拿着这个新的训练集,就可以开始新的一轮训练了。(这里运用了解决样本不平衡欠采样的方法之一)
—跳到第二步(这个过程是重复的)
也就是说,Hard Negative Mining相当于给模型定制一个错题集,在每轮训练中不断“记错题”,并把错题集加入到下一轮训练中,直到网络效果不能上升为止。
CrossEntropy Loss修改权重

样本不均衡时weight的求解方法:(亲测还是有用的 )

Focal Loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本(此处假设:负样本>>正样本)在训练中所占的权重,也可理解为一种困难样本挖掘。本损失函数通过添加了两个因子分别控制简单样本以及负样本(负样本>>正样本)在loss中的贡献度。
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:

是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
1、困难因子:(hhh我自己取得名字为了方便记忆)

首先在原有的基础上加了一个因子,其中gamma>0可以减少易分类样本(简单样本)的损失。使得更关注于困难的、错分的样本。
解释如下:
例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)是一个比较小的数,它的的gamma次方会更小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。
这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
2、平衡因子:
此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均。(对于样本多的类别设置权重小一点,样本少的类比设置权重大一点。)
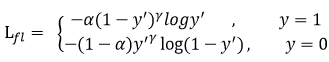
- 平衡因子:alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
- 困难因子:gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









