







0. 定义 区分这仨都是什么东西
参考https://zhuanlan.zhihu.com/p/70256971, https://blog.csdn.net/weixin_48268336/article/details/124393383,https://juejin.cn/post/6984287170517270559
0.1 并发和并行是什么
- 并发:只有一个CPU
- 并行:多个CPU
并发是一个CPU执行多个任务,在一段时间内这几个人物都在同一块CPU中运行,但是某个时间点中,CPU只运行一个任务。有多个线程的时候,只有一个CPU,那CPU只会将运行时间划分成若干个时间段。并发解决了程序排队等待的问题,如果一个程序发生阻塞,其他程序仍然可以正常执行。
并行就是多个CPU资源,一个CPU处理一个任务,互不干涉。
关键点:同时
0.2 进程
进程就是一个程序,是并发执行过程中分配和管理资源的基本单位,是资源分配的最小单位。同一时刻执行的进程不会超过CPU的数量。
每个进程都有自己的地址空间,这是为了记录当前状态,以便CPU切换后可以接着之前的进度工作。进程空间的大小只与处理机的位数有关,一个16位处理机的进程空间大小为216,而32位处理机的进程空间处理机大小为232。
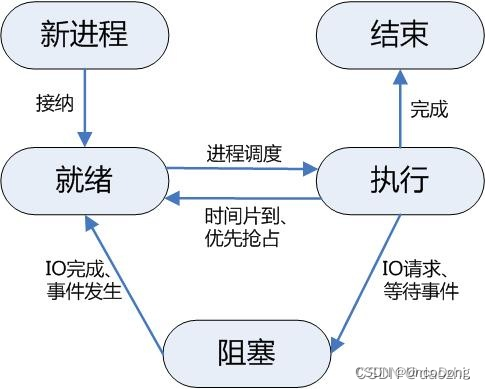
0.2 线程
- 进程-进程:程序和程序之间的关系
- 进程-线程:程序和程序内小任务
在网络或多个用户环境下,一个服务器通常需要接受大量且不确定数量用户的请求,为每一个请求都创建一个进程显然是行不通的,—无论是从系统资源开销方面,或是响应用户请求的效率来看。
线程是进程的一部分,只有一个线程的进程可以叫做“单线程”。在一个线程进程中,线程们共享堆,同时每个县城线程都要维护自己的栈。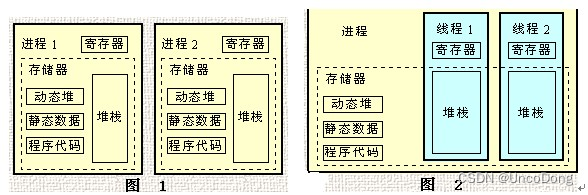
进程和线程的区别
- 进程是CPU资源分配的基本单位,线程是独立运行和独立调度的基本单位(CPU上真正运行的是线程)。
- 进程拥有自己的资源空间,一个进程包含若干个线程,线程与CPU资源分配无关,多个线程共享同一进程内的资源。
- 线程的调度与切换比进程快很多。
CPU密集型代码(各种循环处理、计算等等):使用多进程。IO密集型代码(文件处理、网络爬虫等):使用多线程
阻塞和非阻塞
- 阻塞就是线程/进程被挂起不执行
- 非阻塞就行没有被挂起,继续执行
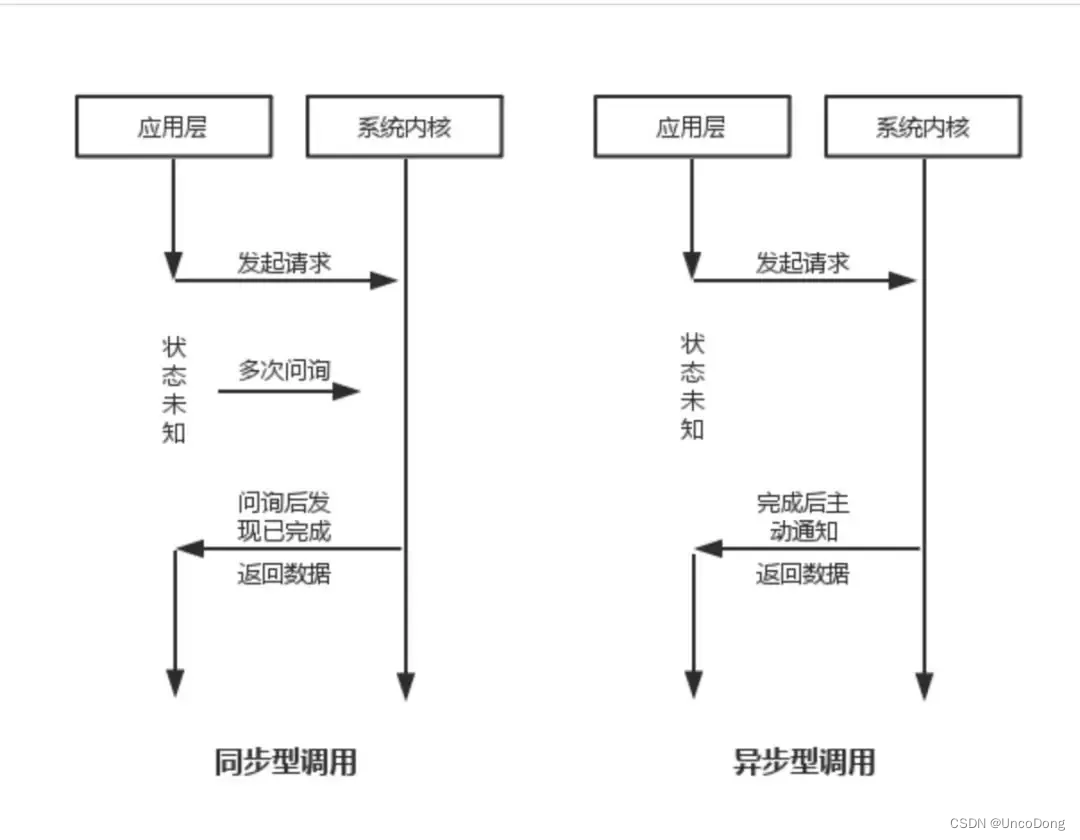
同步和异步
同步就是阻塞,异步就是非阻塞
- 同步就是一个进程在执行某个请求时候,如果该请求要等很长时间才能返回,那进程就会一直等待下去。
- 异步就是进程继续向下执行,不管这个请求的处理。当请求结束后系统会通知进程处理。
调用方主动查询被调用方叫做同步调用,被调用方主动告诉调用方叫做异步调用。
0.3 协程
协程是一种用户态的轻量级线程
协程其实可以认为比线程更小的执行单位。为啥说他是一个最小的执行单位,因为他自带CPU上下文。
简单来说,可以认为协程是线程里不同的函数,这些函数可以相互快速切换,协程和用户态线程非常接近,用户态线程之间的切换不需要陷入内核,但部分操作系统中用户态线程的切换需要内核态线程的辅助。
协程切换,协程拥有自己的寄存器上下文和栈。协程调度切换时候,将寄存器上下文和栈保存在其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
【没太看懂】
最佳实践
线程和协程推荐在IO密集型的任务(比如网络调用)中使用,而在CPU密集型的任务中,表现较差。
对于CPU密集型的任务,则需要多个进程,绕开GIL的限制,利用所有可用的CPU核心,提高效率。
所以大并发下的最佳实践就是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
顺便一提,非常流行的一个爬虫框架Scrapy就是用到异步框架Twisted来进行任务的调度,这也是Scrapy框架高性能的原因之一。
注意下面的代码都应该在pycharm运行,jupyter运行不了
1. 多进程学习 进程池loop
https://blog.csdn.net/h_jlwg6688/article/details/108614426
- 开启进程池
- 往池子里面放任务
- close,停止任务
- join,开始运行
2. 多线程学习
https://www.cnblogs.com/aylin/p/5601969.html
import threading
import time
globals_num = 0
lock = threading.RLock()
def Func():
# lock.acquire() # 获得锁
global globals_num
globals_num += 1
time.sleep(1)
print(globals_num)
# lock.release() # 释放锁
for i in range(10):
t = threading.Thread(target=Func)
t.start()
3. 多携程学习
python async异步编程(asyncio 学python必备)
up主 武沛齐:https://space.bilibili.com/550438936
4. 并发编程(目前比较实用)
https://python3-cookbook.readthedocs.io/zh_CN/latest/c12/p08_perform_simple_parallel_programming.html, https://blog.csdn.net/weixin_42516989/article/details/106890254
需要CPU密集型工作的任务,可以使用concurrent.futures库
基础模版如下
from concurrent.futures import ProcessPoolExecutor
with ProcessPoolExecutor() as pool:
...
do work in parallel using pool
...
使用例如下(参考 https://python3-cookbook.readthedocs.io/zh_CN/latest/c12/p08_perform_simple_parallel_programming.html)
准备工作
一个logs文件夹,文件夹里面的文件都是.log.gz结尾的
文件里面的数据都是这样的
124.115.6.12 - - [10/Jul/2012:00:18:50 -0500] "GET /robots.txt ..." 200 71
210.212.209.67 - - [10/Jul/2012:00:18:51 -0500] "GET /ply/ ..." 200 11875
210.212.209.67 - - [10/Jul/2012:00:18:51 -0500] "GET /favicon.ico ..." 404 369
61.135.216.105 - - [10/Jul/2012:00:20:04 -0500] "GET /blog/atom.xml ..." 304 -
函数使用
# findrobots.py
import gzip
import io
import glob
from concurrent import futures
def find_robots(filename):
'''
Find all of the hosts that access robots.txt in a single log file
'''
robots = set()
# 打不开的话就换成with open,读取文字,效果是一样的
with gzip.open(filename) as f:
for line in io.TextIOWrapper(f,encoding='ascii'):
fields = line.split()
if fields[6] == '/robots.txt':
robots.add(fields[0])
return robots
def find_all_robots(logdir):
'''
Find all hosts across and entire sequence of files
'''
files = glob.glob(logdir+'/*.log.gz')
all_robots = set()
with futures.ProcessPoolExecutor() as pool:
for robots in pool.map(find_robots, files):
all_robots.update(robots)
return all_robots
if __name__ == '__main__':
robots = find_all_robots('logs')
for ipaddr in robots:
print(ipaddr)
特殊情况
有的时候会报错AttributeError: Can’t pickle local object,这个和多进程中的序列化有关(闭包:https://blog.51cto.com/u_14640073/2806706;不允许闭包序列化https://www.zhihu.com/question/28566219)
我还没搞懂具体为什么,但知道一个解决办法,完美解决了我的问题,参考https://blog.csdn.net/weixin_42516989/article/details/106890254
from multiprocessing import Pool
class test1:
def __init__(self, args):
self.args = args
def __call__(self, t):
return self.args + t
if __name__ == "__main__":
p = Pool(4)
result = p.map(test1(10), [i for i in range(10)])
p.close()
p.join()
print(result)














 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









