







正则表达式用法---Python,R
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式在文本挖掘,爬虫,数据处理中都十分重要。
基本用法—单字符匹配
| 字符 | 功能 |
|---|---|
. | 匹配任意一个字符(除了\n) |
[] | 匹配方框中列举的字符 |
\d | 匹配数字0-9 |
\D | 匹配非数字 |
\s | 匹配空白(包括 空格、\tab、\r,\n等) |
\S | 匹配非空白 |
\w | 匹配单词字符包括a-z,A-Z,0-9,_ |
\W | 匹配非单词字符 |
下面我们来看一下正则表达式在具体软件中的基本用法:
1. python
import re #导入正则表达式对应的包
print(re.match(".","ab"))
print(re.match(".",""))

2. R
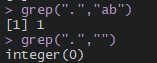
grep(".","ab")
grep(".","")
基本用法—数量匹配
| 字符 | 功能 |
|---|---|
* | 匹配前一个字符出现0次或者无数次 |
+ | 匹配前一个字符出现最少一次 |
? | 匹配前一个字符出现0次或者一次 |
{m} | 匹配前一个字符出现m次 |
{m,} | 匹配前一个字符至少出现m次 |
{m,n} | 匹配前一个字符出现m到n次(n>m) |
python
print(re.match("\d{5,7}","1234"))
print(re.match("\d{5,7}","12345"))

R
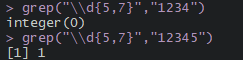
grep("\\d{5,7}","1234")#需要加入转义字符进行识别,python中可在正则表达式前面加r来识别转义字符
grep("\\d{5,7}","12345")
基本用法—边界子符串
| 字符 | 功能 |
|---|---|
^ | 匹配字符串的开头 |
$ | 匹配字符串的结尾 |
\b | 匹配一个单词到边界 |
\B | 匹配非单词边界 |
python
s = "one two three"
print(re.match("abcd123","abcd1234"))
print(re.match("abcd123$","abcd1234"))
print(re.match(r"\w+\s\btwo\b",s))#到达一个单词的边界
print(re.match(r"\w+\s\btwo\B",s))

R
s = "one two three"
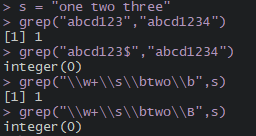
grep("abcd123","abcd1234")
grep("abcd123$","abcd1234")
grep("\\w+\\s\\btwo\\b",s)
grep("\\w+\\s\\btwo\\B",s)
基本用法—匹配分组
| 字符 | 功能 |
|---|---|
| | 匹配左右任意一个表达式 |
(ab) | 将括号中符作为一个分组 |
\num | 引用分组num匹配到字符串 |
(?P<>) | 分组起名 |
?P=name | 引用别名为name分组匹配到的字符串 |
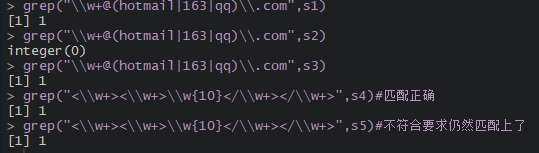
python
s1 = "123456789@qq.com"
s2 = "onetwothree@126.com"
s3 = "onetwothree@hotmail.com"
s4 = "<html><h1>helloworld</h1></html>"
s5 = "<html><h1>helloworld</h1></haml>"
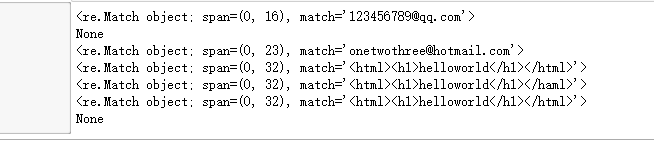
print(re.match(r"\w+@(hotmail|163|qq)\.com",s1))
print(re.match(r"\w+@(hotmail|163|qq)\.com",s2))
print(re.match(r"\w+@(hotmail|163|qq)\.com",s3))
print(re.match(r"<\w+><\w+>\w{10}</\w+></\w+>",s4))#匹配正确
print(re.match(r"<\w+><\w+>\w{10}</\w+></\w+>",s5))#不符合要求仍然匹配上了
print(re.match(r"<(?P<group1>\w+)><(?P<group2>\w+)>\w{10}</(?P=group2)></(?P=group1)>",s4))#匹配正确
print(re.match(r"<(?P<group1>\w+)><(?P<group2>\w+)>\w{10}</(?P=group2)></(?P=group1)>",s5))#识别出不符合要求
没有找到R对应的分组捕获模块,后面如果找到了再更新
grep("\\w+@(hotmail|163|qq)\\.com",s1)
grep("\\w+@(hotmail|163|qq)\\.com",s2)
grep("\\w+@(hotmail|163|qq)\\.com",s3)
grep("<\\w+><\\w+>\\w{10}</\\w+></\\w+>",s4)#匹配正确
grep("<\\w+><\\w+>\\w{10}</\\w+></\\w+>",s5)#不符合要求仍然匹配上了
进阶用法—Python
| 语句 | 功能 |
|---|---|
re.search() | 查找是否有对应字符串并显示位置 |
re.findall() | 查找所有符合条件,并输出到一个列表中 |
re.sub() | 搜寻符合条件的表达式,并用给出的表达式替换文本中原有表达式 |
re.split() | 将文本按照给出的分隔符进行分割,并保存到列表中 |
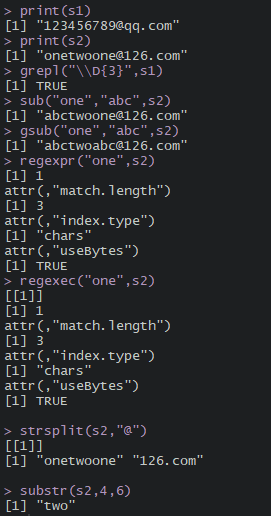
s6 ="abcd1234abc"
a = re.search(r"abc",s6)
print(a)
b = re.findall(r"\D{3}",s6)
print(b)
c = re.sub(r"\D{3}","qwe",s6)
print(c)
d = "first:1 ,second;2 third-3"
print(re.split(r":|,|;|-",d))

python其他字符串处理方法(pandas)
| 语句 | 功能 |
|---|---|
data.str.count('x') | 计算字符串中所出现次数 |
data.str.get(1) | 取字符串中对应位置的字符 |
data.contains('x') | 用布尔逻辑表示是否含有某个特定的字符 |
data.str.replace('a','b') | 替换掉某个字符串 |
data.str.slice(1,3) | 在指定的开始结束位置切割字符串 |
data.str.slice_replace(1,3,'a') | 在指定位置替换字符—最好先看一下是哪个字符 |
data.str.endwith/startwith('x') | 检查第一个字符或者左后一个字符是否是给定的,以布尔逻辑输出 |
data.str.lower()/upper()/swapcase() | 转换为大小写,或者互换大小写 |
data.str.find('x') | 找到每个字符所在位置 |
data.str.isalnum()/isalpha()/isdigit()/isspace() | 检查字符串由什么类型字符组成 |
进阶用法—R
| 语句 | 功能 |
|---|---|
grepl() | 返回布尔逻辑值 |
sub() | 只对查找到的第一个内容进行替换 |
gsub() | 对查找到的所有内容进行替换 |
regexpr() | 返回一个与给出第一个匹配的起始位置的文本长度相同的整数向量,如果没有则返回-1 |
gregexpr() | 返回一个与文本长度相同的列表,每个元素的格式与regexpr的返回值相同,除了给出了每个(不相交)匹配的起始位置。 |
regexec() | 返回与文本相同长度的列表,如果没有匹配,则返回-1,或者具有匹配的起始位置的整数序列和对应于模式的括号子表达式的所有子串,其中属性“match .length“给出匹配长度的向量(或没有匹配的-1)。 |
strsplit() | 字符串分割 |
substr() | 字符串提取 |
贪婪与非贪婪
贪婪指的是在能匹配上表达式的情况下,尽可能的使表达式匹配的内容最短
Python举例
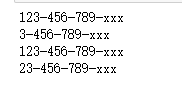
s = "123-456-789-xxx"
a = re.match(".+(\d+-\d+-\d+-\w+)",s)
b = re.match(".+?(\d+-\d+-\d+-\w+)",s)
print(a.group(0))
print(a.group(1))#贪婪算法
print(b.group(0))
print(b.group(1))#非贪婪算法















 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









