






0.打开,为什么呢?
因为chattts,一直有电流声。受不了。
anconda虚拟环境默认在C上,如果修改了,显示成功了,但还不行,注意修改指定位置的权限
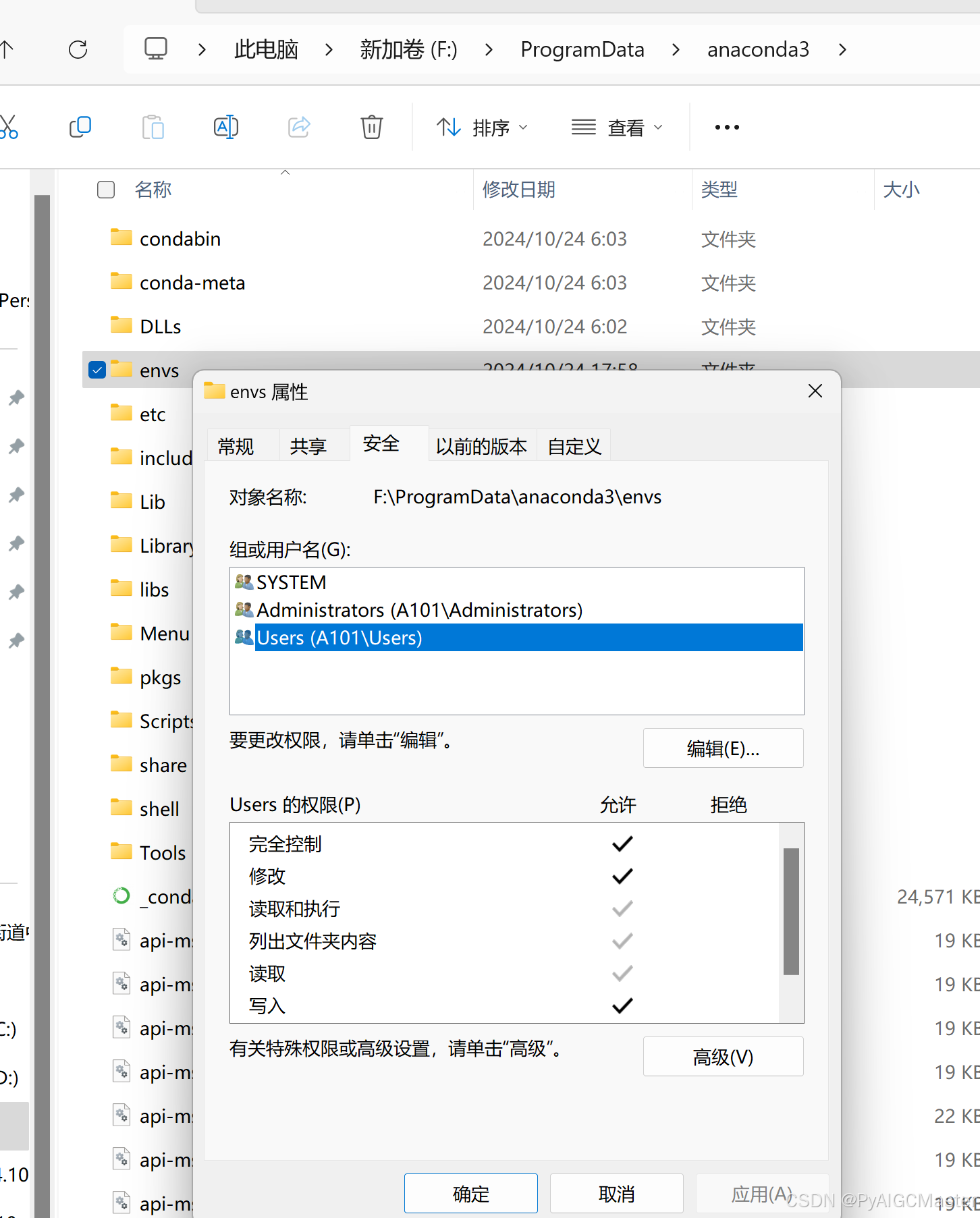
1.我在F盘
在F盘,地址栏上 cmd
照着说明上来
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.gitcd CosyVoice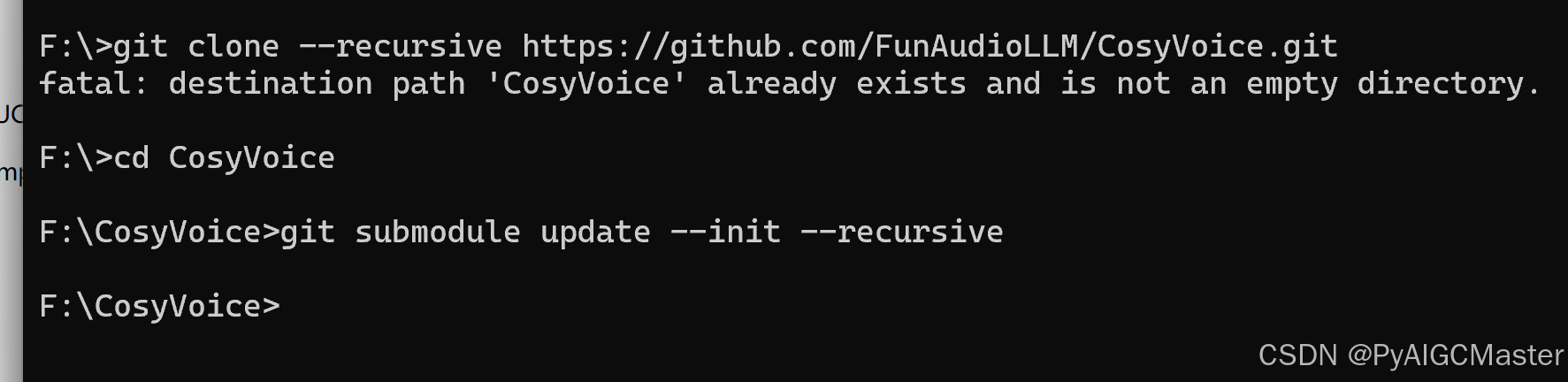 2.虚拟环境
2.虚拟环境
conda create -n cosyvoice python=3.8conda activate cosyvoice
# pynini is required by WeTextProcessing, use conda to install it as it can be executed on all platform.
conda install -y -c conda-forge pynini==2.1.5
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com 
很多教程上,要求修改 requirements.txt ,我试了几次,谁也不知什么问题会出现。所以我这次不修改了。直接用官网上的教程。
https://download.pytorch.org/whl/cu118/torch-2.0.1%2Bcu118-cp38-cp38-win_amd64.whl
这个有点大,我用下载器下到本地先。速度咕咕的。
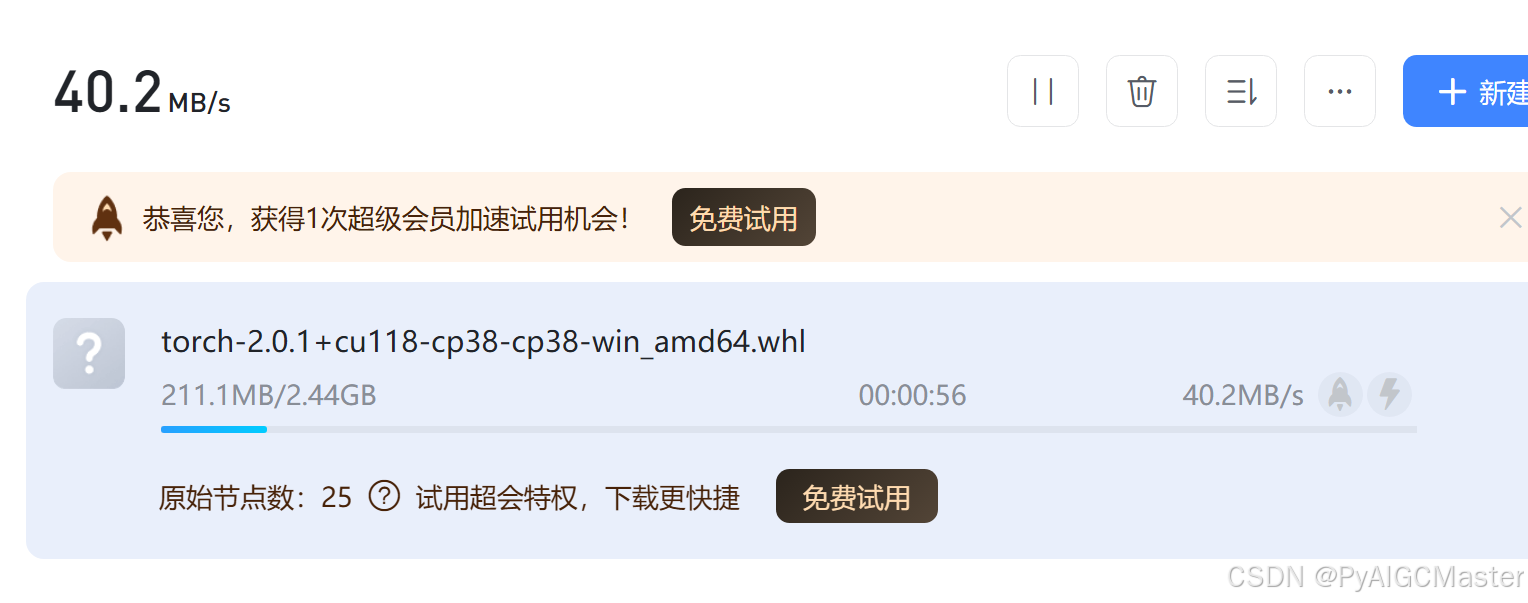
安装一下,注意你的实际
(cosyvoice) F:\CosyVoice>pip install F:\迅雷下载\torch-2.0.1+cu118-cp38-cp38-win_amd64.whl
速度吓人。修改一下。
python -m pip install --upgrade pip
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple这会行了。
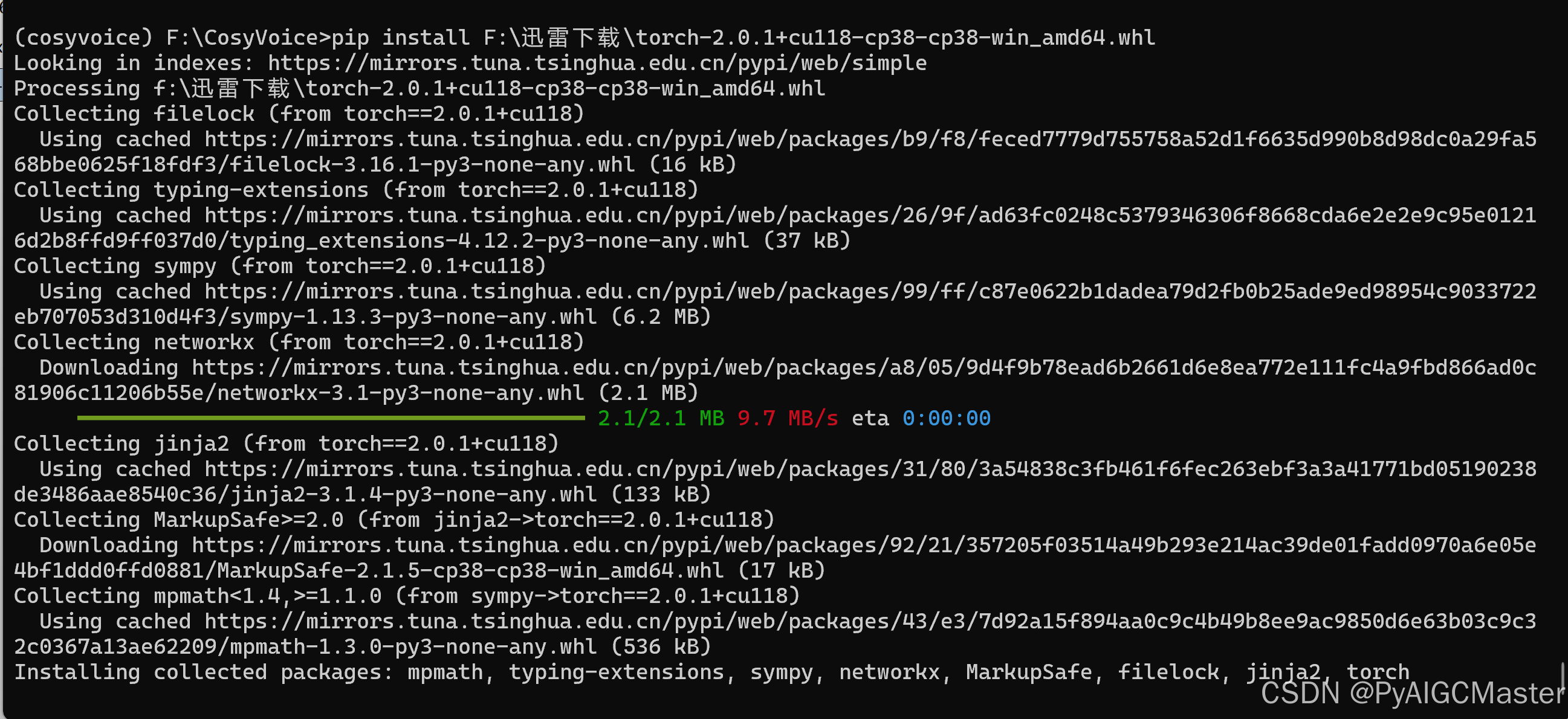
再次
pip install -r requirements.txt 无伤通过
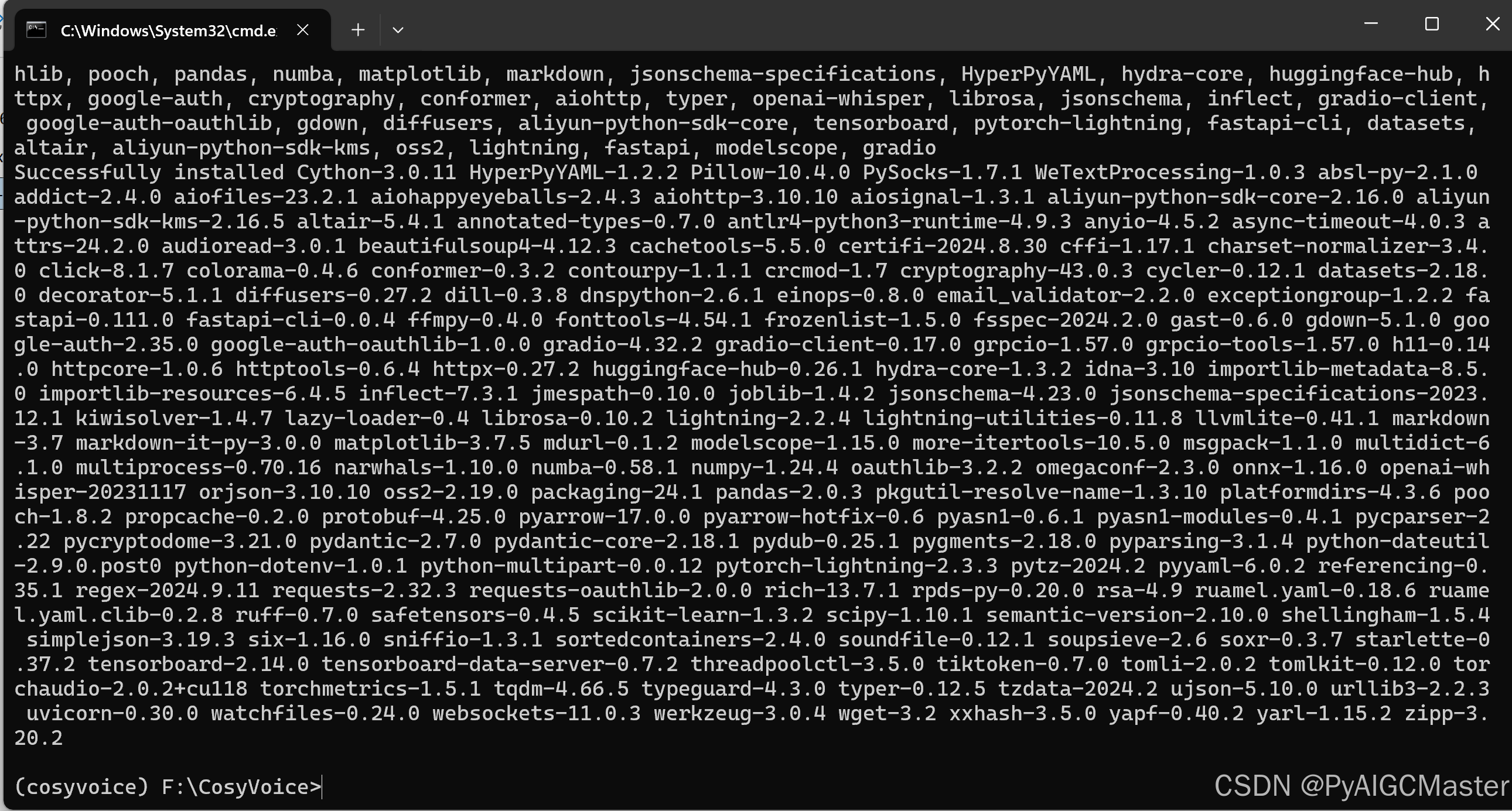
2.下载模型
打开pycharm社区版
新建工程,如果你像我找不到虚拟环境了。看图,另外注意大小写,复制吧。
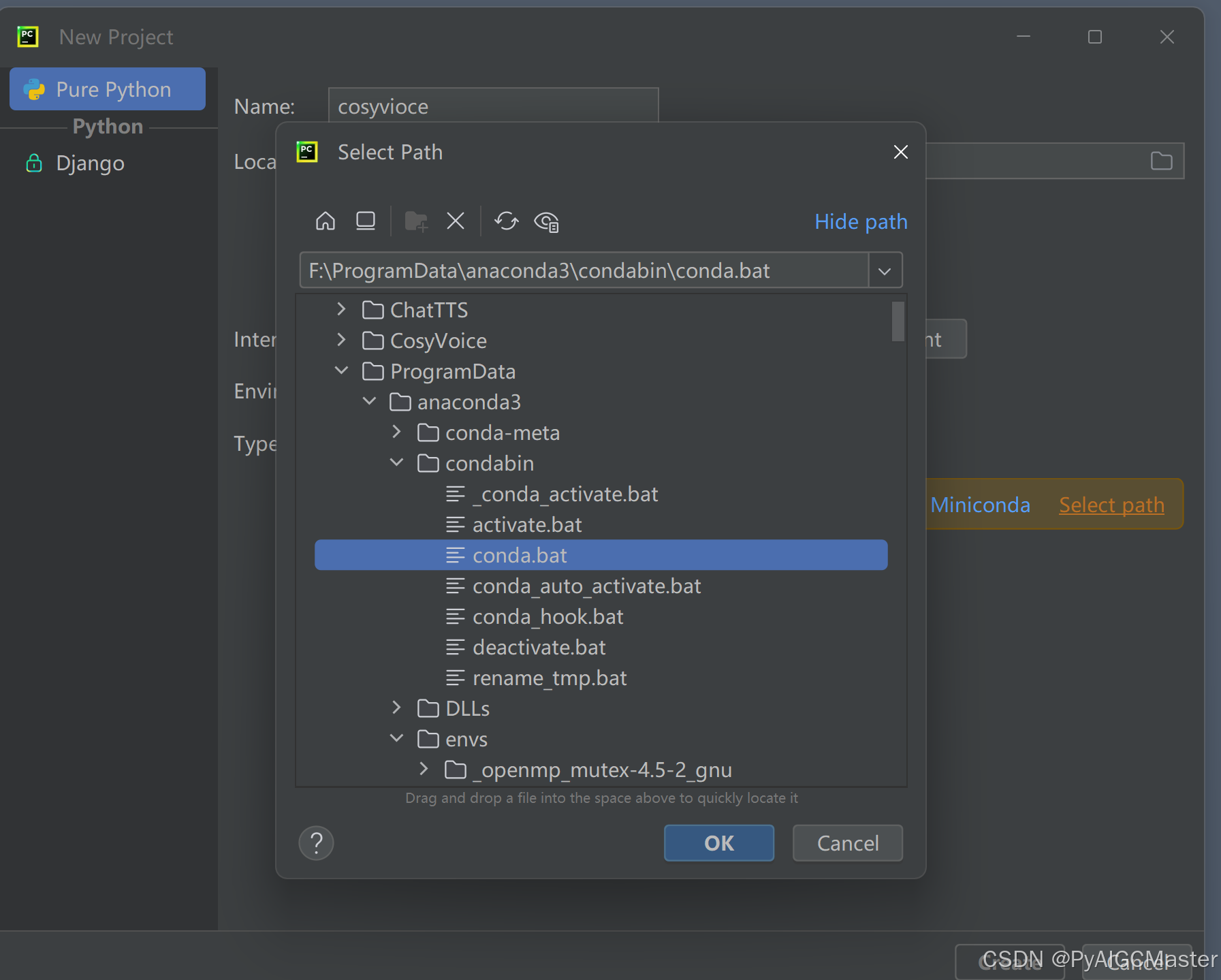
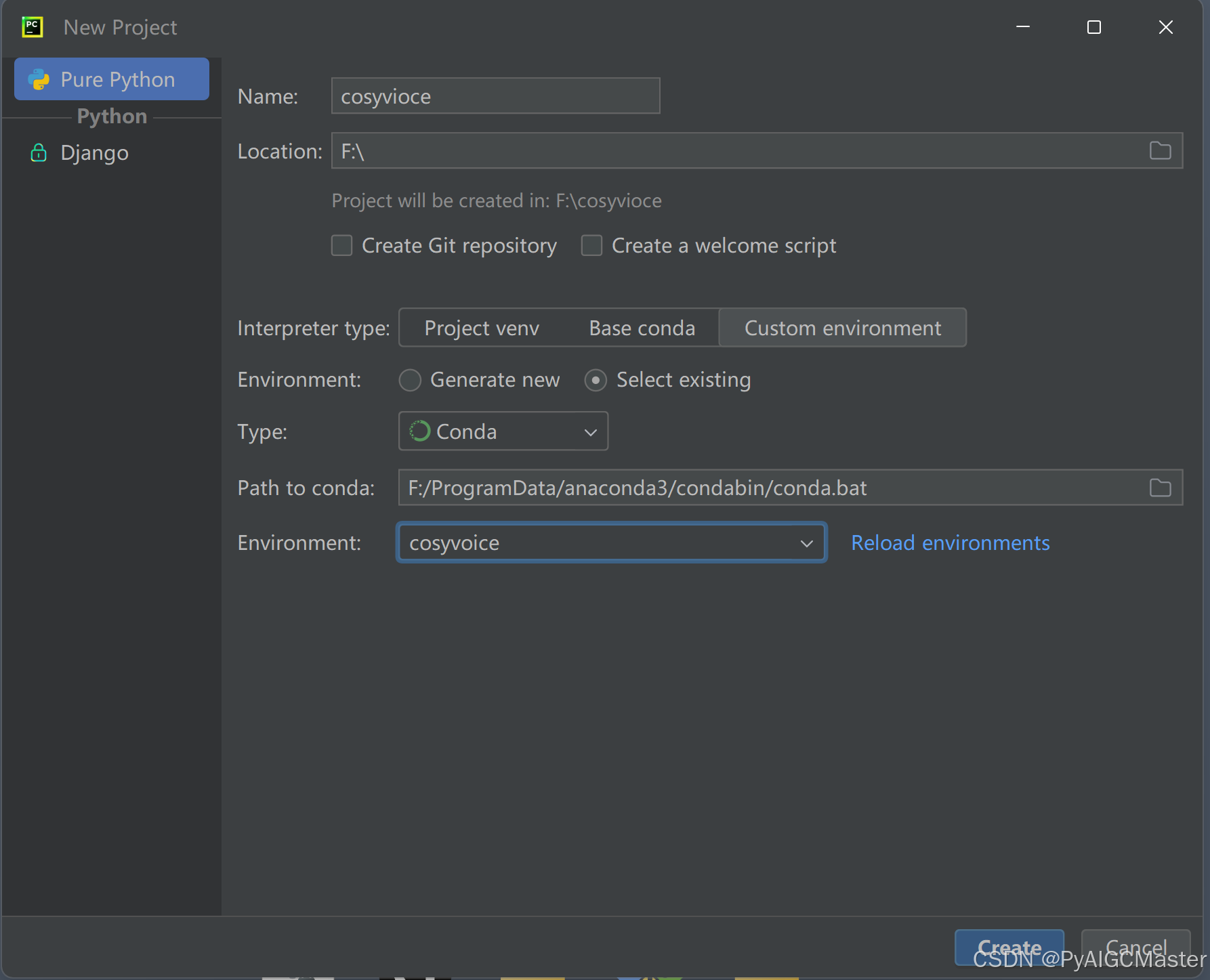
上图,工程名不对。注意一下。确定吧。
这是建立 之后的。
根目录下,新建一个下载模型的文件。
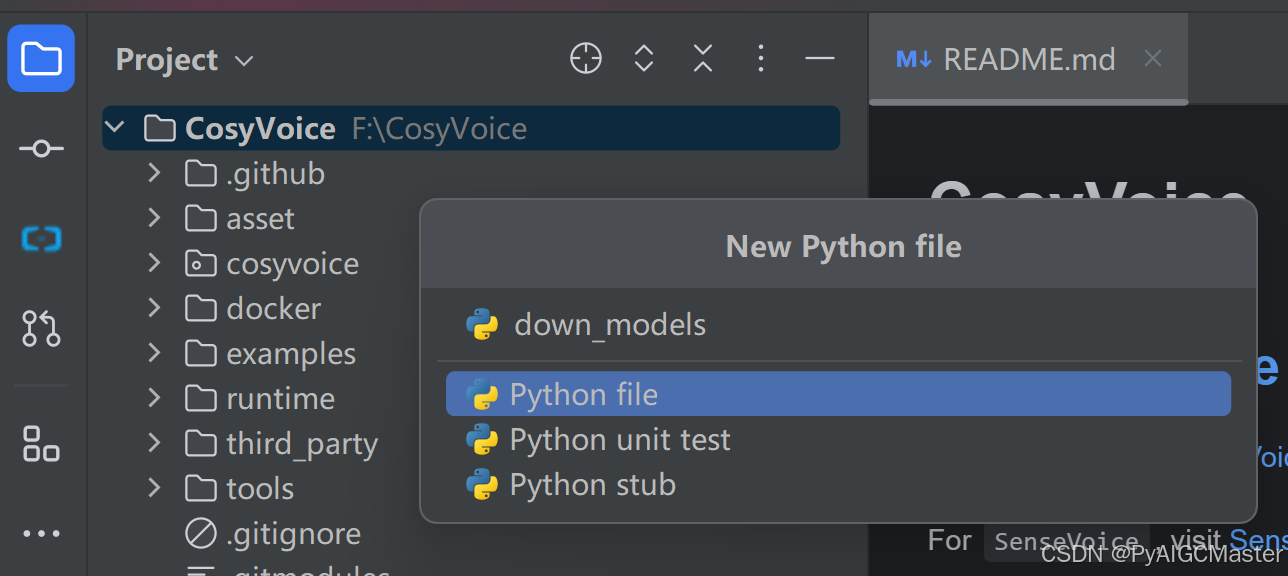
# SDK模型下载
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
snapshot_download('iic/CosyVoice-300M-25Hz', local_dir='pretrained_models/CosyVoice-300M-25Hz')
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')复制代码,如图
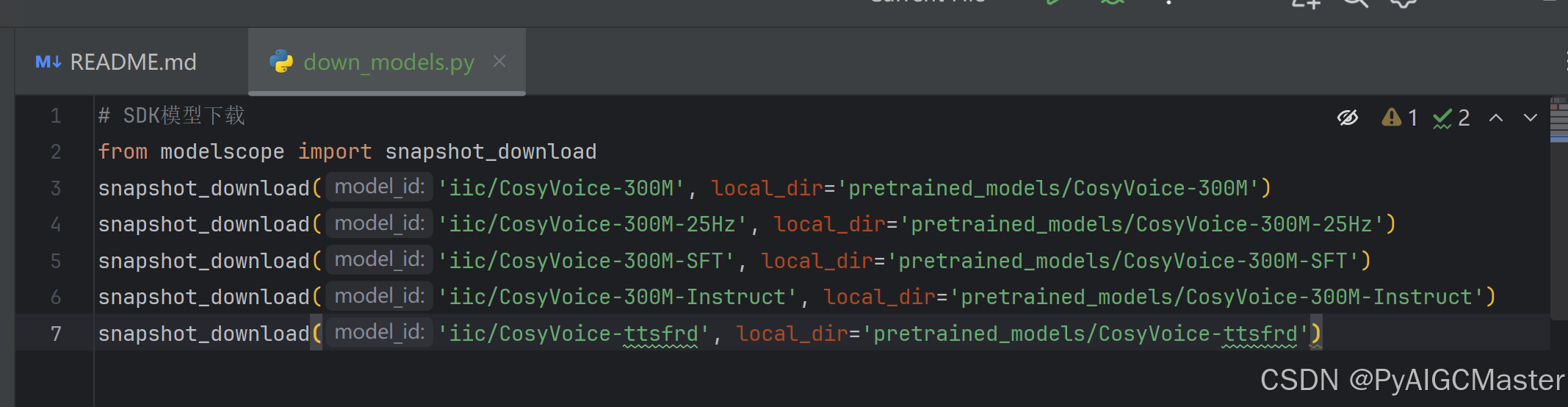
运行吧会在根目录下新建一个文件夹的。
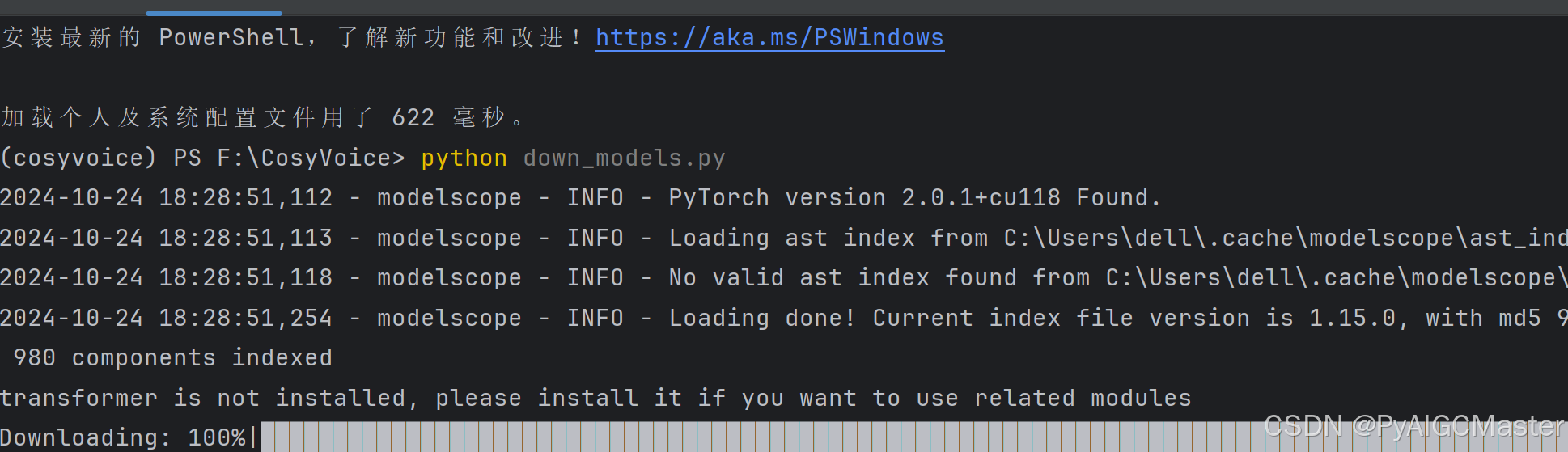
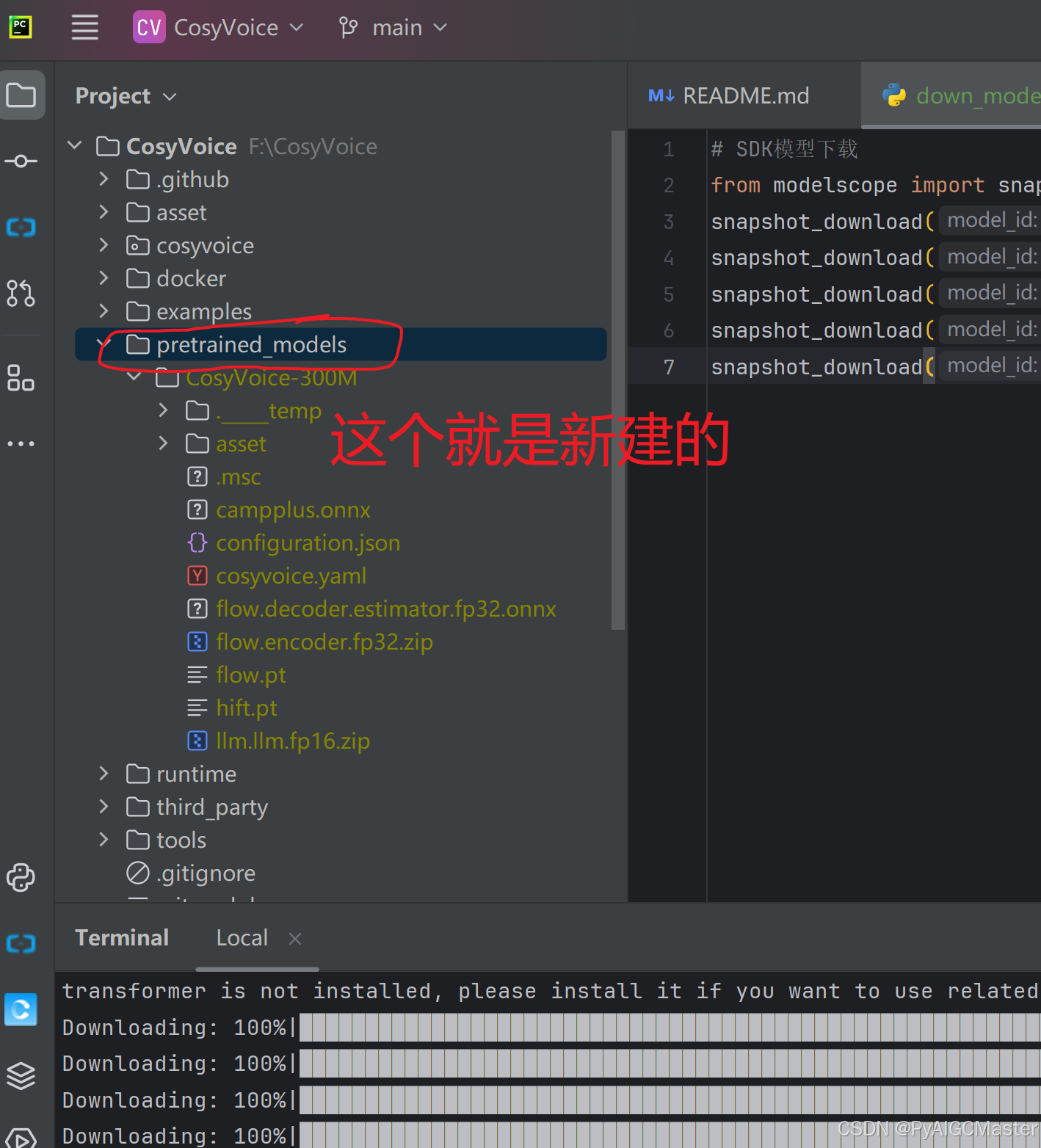
漫长的等待吧。看看正经的操作是什么?非必须过程。最后一个。说平台不符。什么鬼,过了吧。
cd pretrained_models/CosyVoice-ttsfrd/
unzip resource.zip -d .
pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whlunzip resource.zip -d . 这个换成图形操作,是什么选项?
将命令 unzip resource.zip -d . 转换为图形界面操作,可以按照以下步骤进行:
找到压缩文件:
在文件管理器中定位到 resource.zip 文件。
右键点击文件:
右键点击 resource.zip 文件,弹出上下文菜单。
选择解压选项:
在弹出的菜单中选择“解压到当前文件夹”或类似的选项。不同的文件管理器可能有不同的表述,例如:
Windows 资源管理器:选择“全部解压”或“解压到当前文件夹”。
macOS Finder:选择“解压”或“解压到当前文件夹”。
Linux 文件管理器(如 Nautilus):选择“解压到此处”。
确认解压:
如果有确认对话框出现,点击“确定”或“解压”按钮。
这样,resource.zip 文件就会被解压到当前文件夹中,与命令 unzip resource.zip -d . 的效果相同。
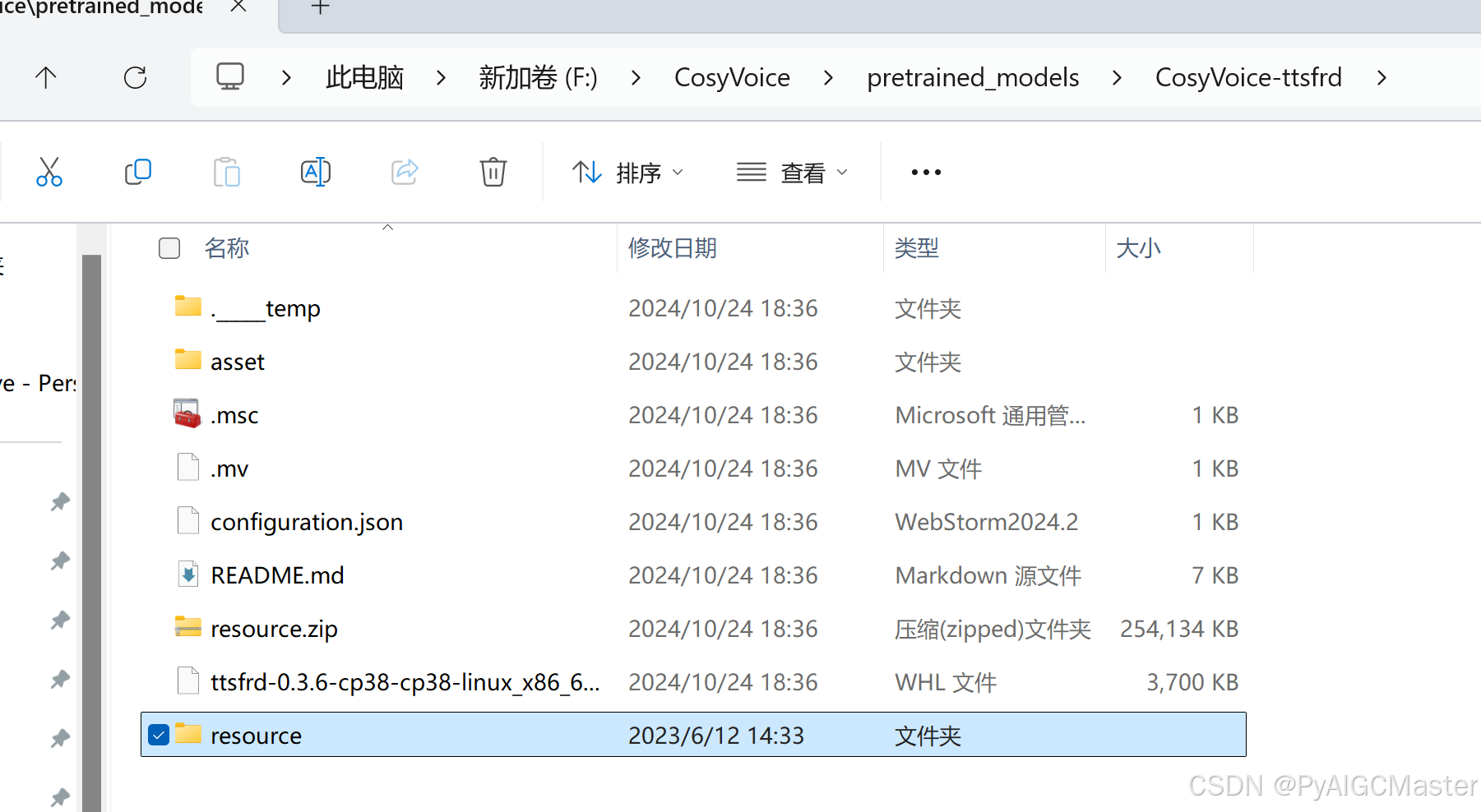

就是这个文件夹内的一个whl,图上倒数第二个。
不先管了。
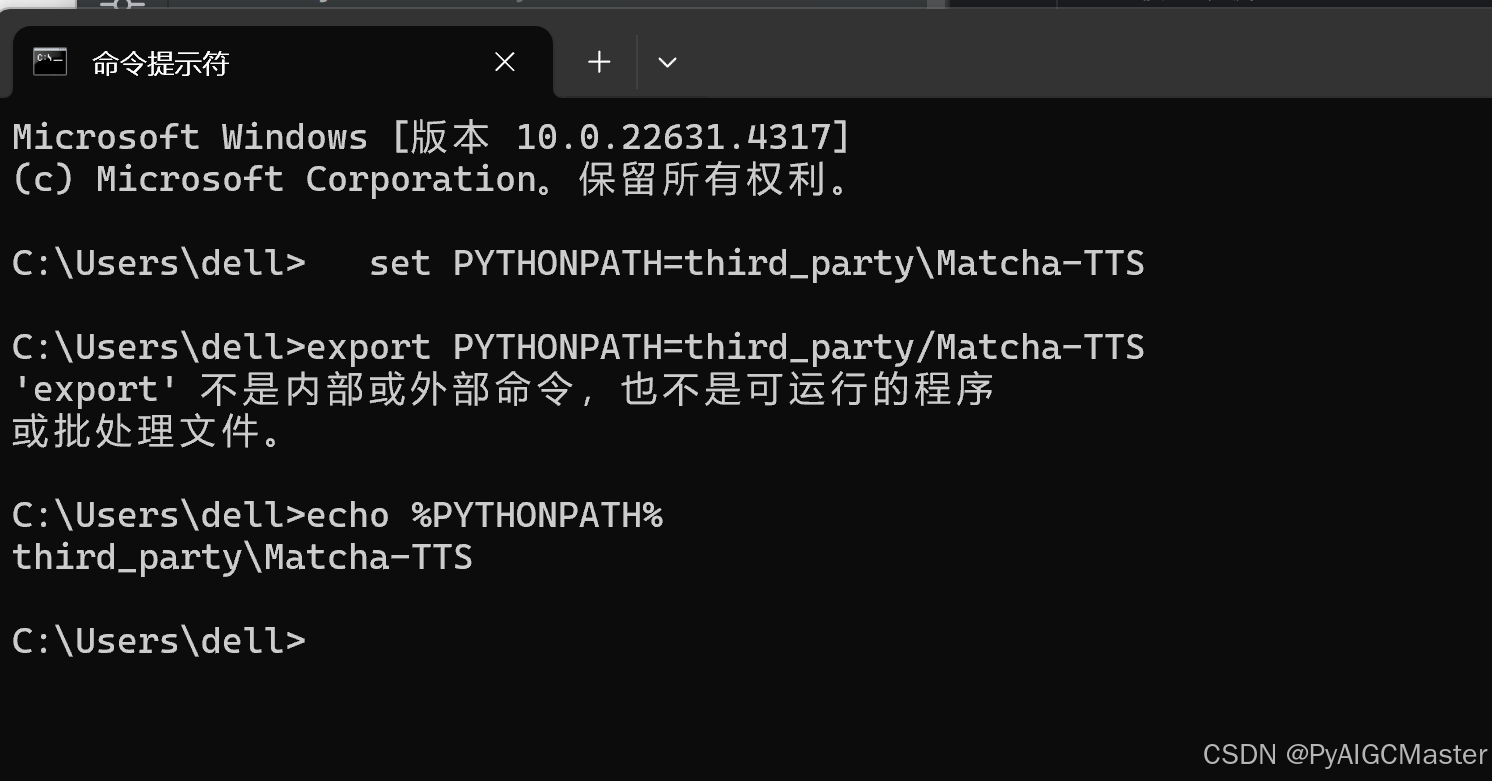
加路径 ,然后验证一下。下边的这个,问群里说,也可以不用管。谁知道来。
export PYTHONPATH=third_party/Matcha-TTS 非win平台,
set PYTHONPATH=third_party\Matcha-TTS win平台,真坑
3.测试一下。
from cosyvoice.cli.cosyvoice import CosyVoice
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-SFT', load_jit=True, load_onnx=False, fp16=True)
# sft usage
print(cosyvoice.list_avaliable_spks())
# change stream=True for chunk stream inference
for i, j in enumerate(cosyvoice.inference_sft('你好,我是通义生成式语音大模型,请问有什么可以帮您的吗?', '中文女', stream=False)):
torchaudio.save('sft_{}.wav'.format(i), j['tts_speech'], 22050)
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-25Hz') # or change to pretrained_models/CosyVoice-300M for 50Hz inference
# zero_shot usage, <|zh|><|en|><|jp|><|yue|><|ko|> for Chinese/English/Japanese/Cantonese/Korean
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], 22050)
# cross_lingual usage
prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k, stream=False)):
torchaudio.save('cross_lingual_{}.wav'.format(i), j['tts_speech'], 22050)
# vc usage
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
source_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_vc(source_speech_16k, prompt_speech_16k, stream=False)):
torchaudio.save('vc_{}.wav'.format(i), j['tts_speech'], 22050)
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-Instruct')
# instruct usage, support <laughter></laughter><strong></strong>[laughter][breath]
for i, j in enumerate(cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.', stream=False)):
torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], 22050)复制以上代码,放在根目录下。cs.py
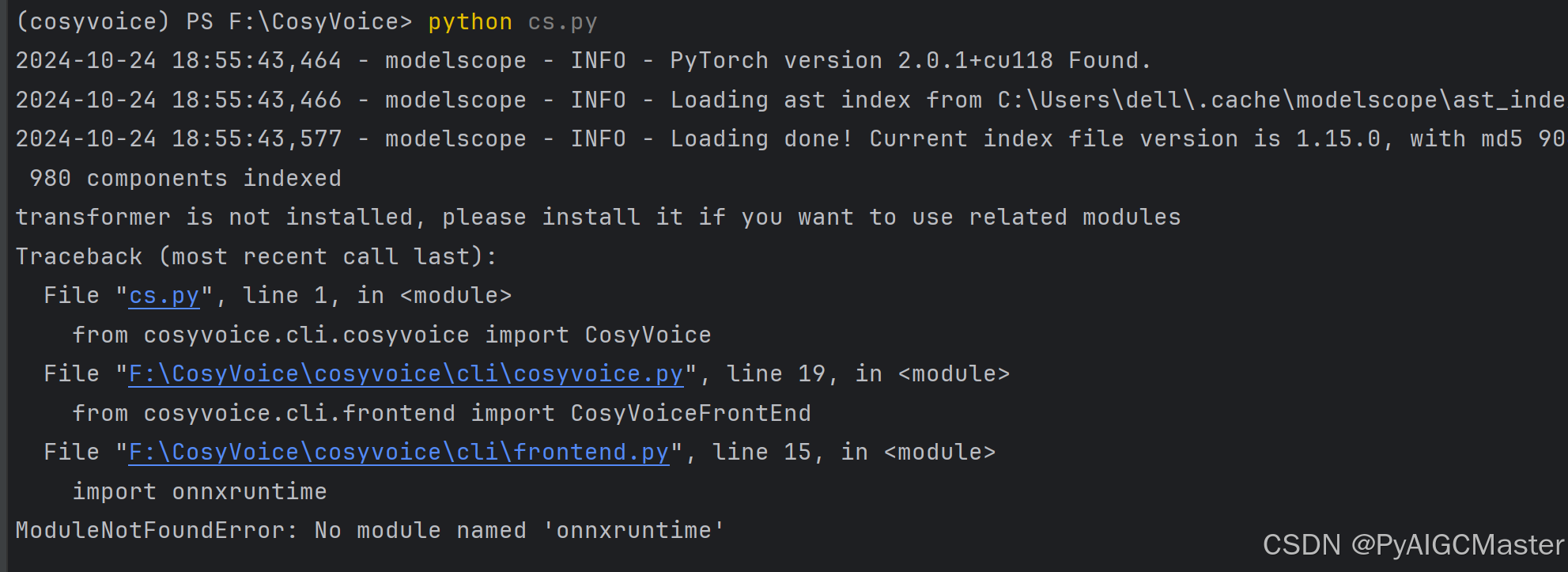
从错误信息来看,你的脚本 cs.py 在运行时遇到了两个主要问题:
缺少 transformers 库:
错误信息提示 transformer is not installed, please install it if you want to use related modules。
缺少 onnxruntime 库:
错误信息提示 ModuleNotFoundError: No module named 'onnxruntime'。
解决方法
1. 安装 transformers 库
你可以使用 pip 来安装 transformers 库。在命令提示符或终端中运行以下命令:pip install transformers2. 安装 onnxruntime 库
同样,你可以使用 pip 来安装 onnxruntime 库。在命令提示符或终端中运行以下命令:pip install onnxruntime
按照上面的解决,安装之。再试,找不到matcha,上超级
$env:PYTHONPATH = "F:\CosyVoice\third_party\Matcha-TTS;"+$env:PYTHONPATH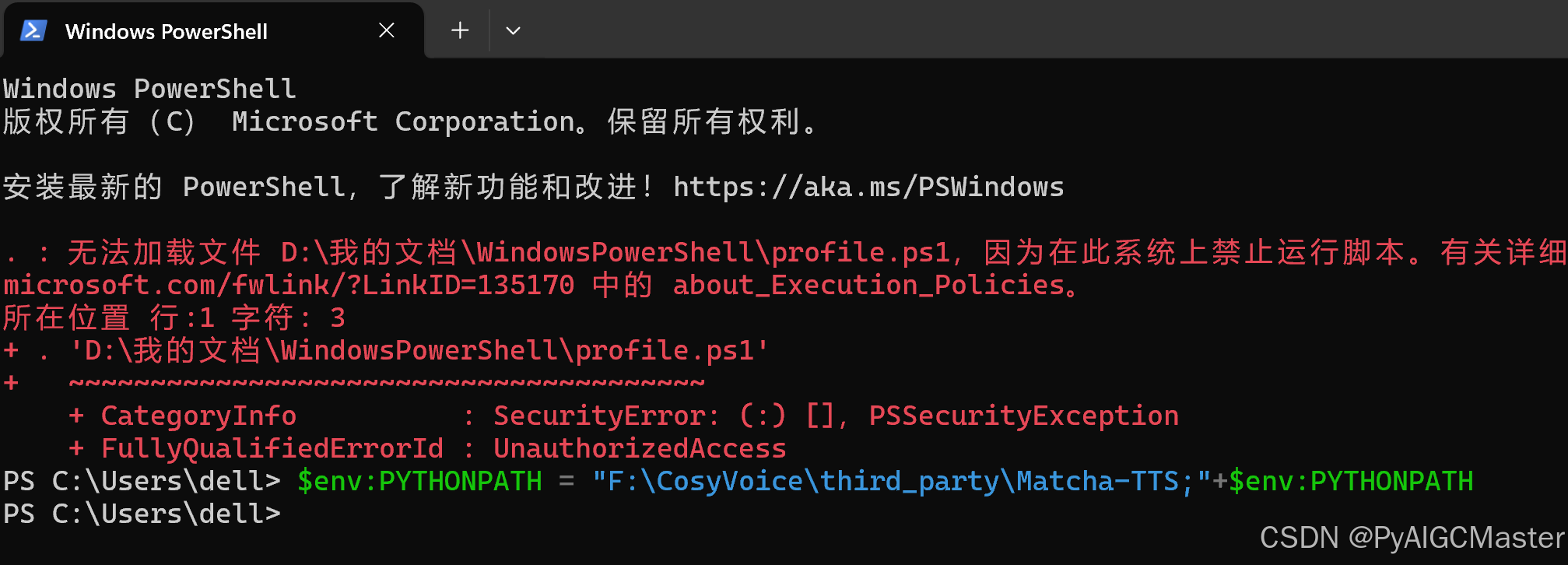
问了群里的,说,直接安装即可。
找原因吧。
可能的出错原因,你可以借看的。
运行的路径问题:,webui要从F盘开始运行如
(cosyvoice) PS F:\> python cosyvoice\webui.py
cs.py,即上面的那大段的代码。要从f:\cosyvoice下运行,有时不用也行。
:python cs.py
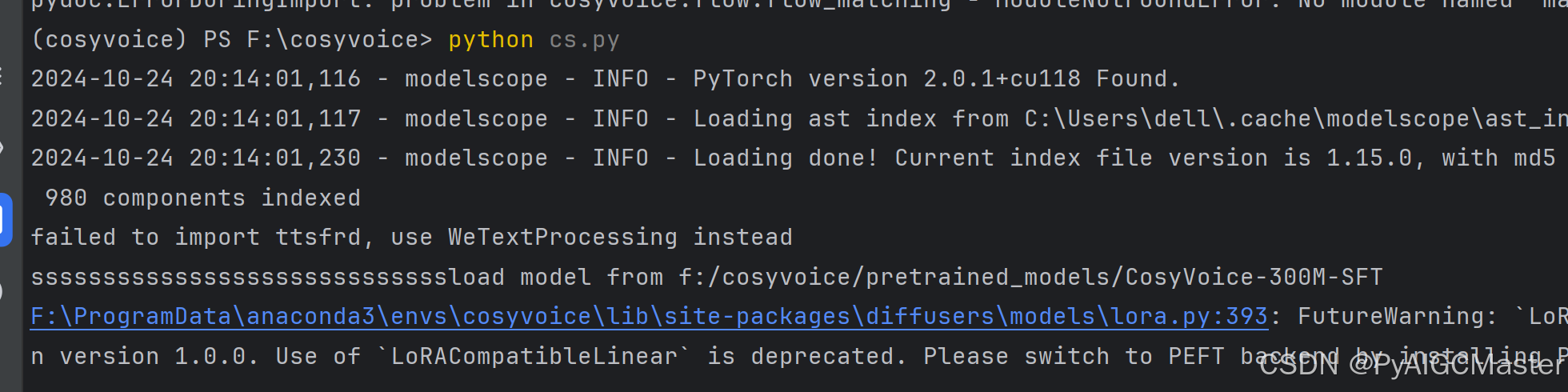
cs.py找不到matcha,的解决方法
import os, sys
sys.path.insert(0, os.path.abspath('third_party/Matcha-TTS')) 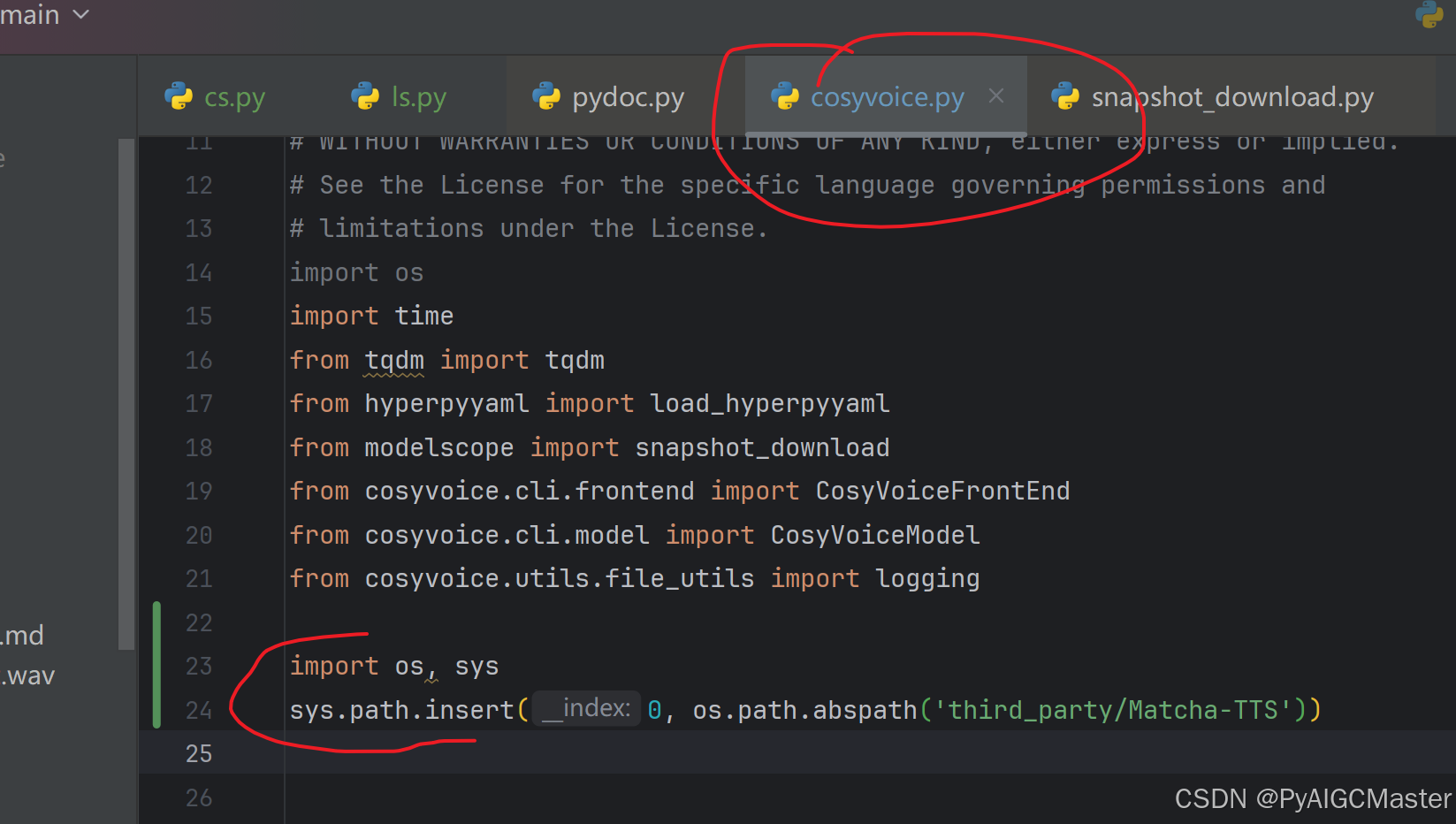
修改模型位置,改成绝对的位置,下面是webui.py的,运行要从盘符下方开始。否则出错。
如
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--port',
type=int,
default=8000)
parser.add_argument('--model_dir',
type=str,
default='f:/cosyvoice/pretrained_models/CosyVoice-300M',
help='local path or modelscope repo id')
args = parser.parse_args()
cosyvoice = CosyVoice(args.model_dir)
sft_spk = cosyvoice.list_avaliable_spks()
prompt_sr, target_sr = 16000, 22050
default_data = np.zeros(target_sr)
main()
模块板本问题,也要注意
pip install huggingface_hub==0.23.5 不要太高了。否则会出错的。
最终:
速度感觉不如chattts快,但是清晰一些。

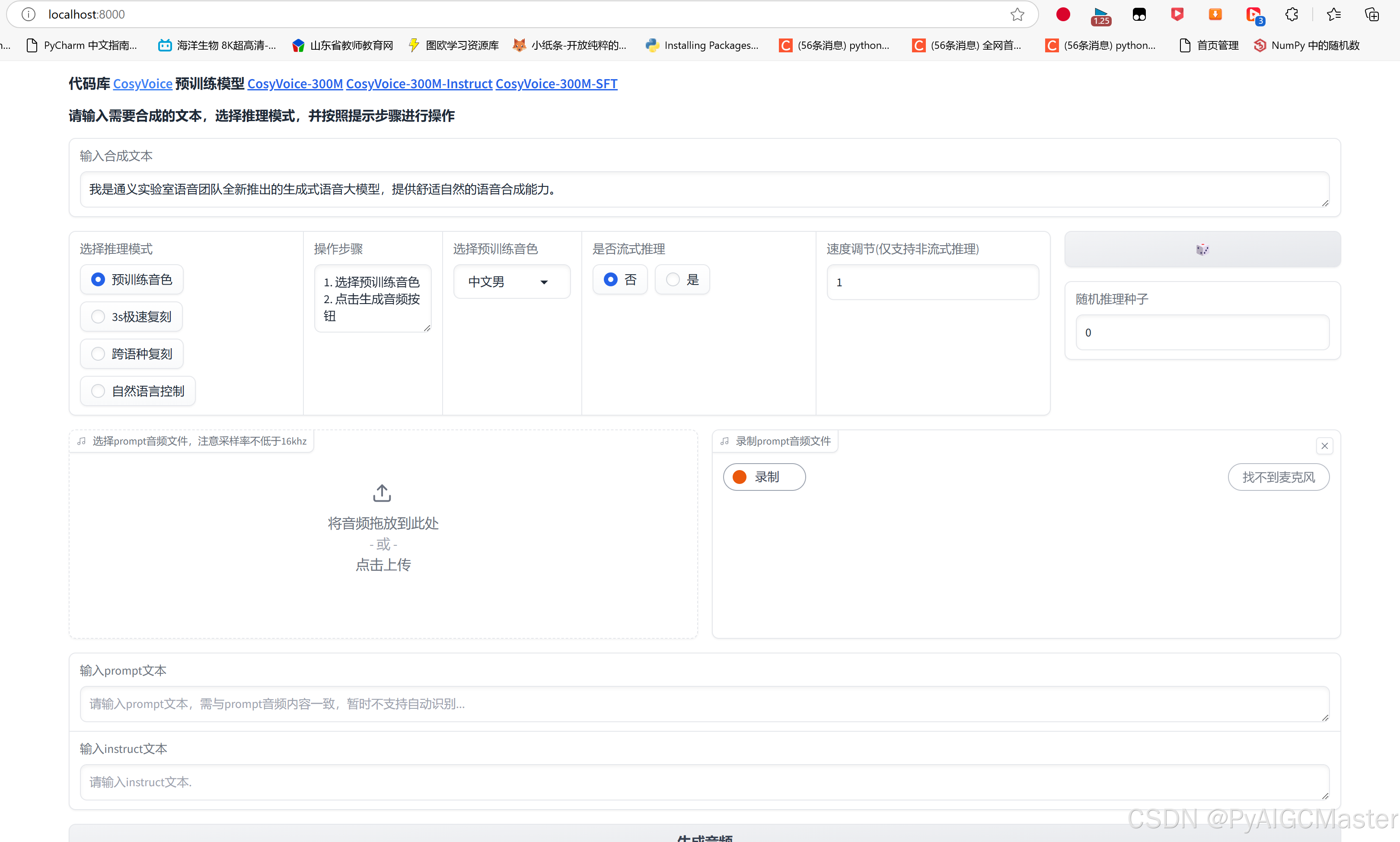
我的这个机器4G的t1000.,chattts,音频时间:生成时间约1:1.3-1.5左右。
这个大约是1:5-6之间。还是相差不少。但好在声音要好一些。 gpu使用100%
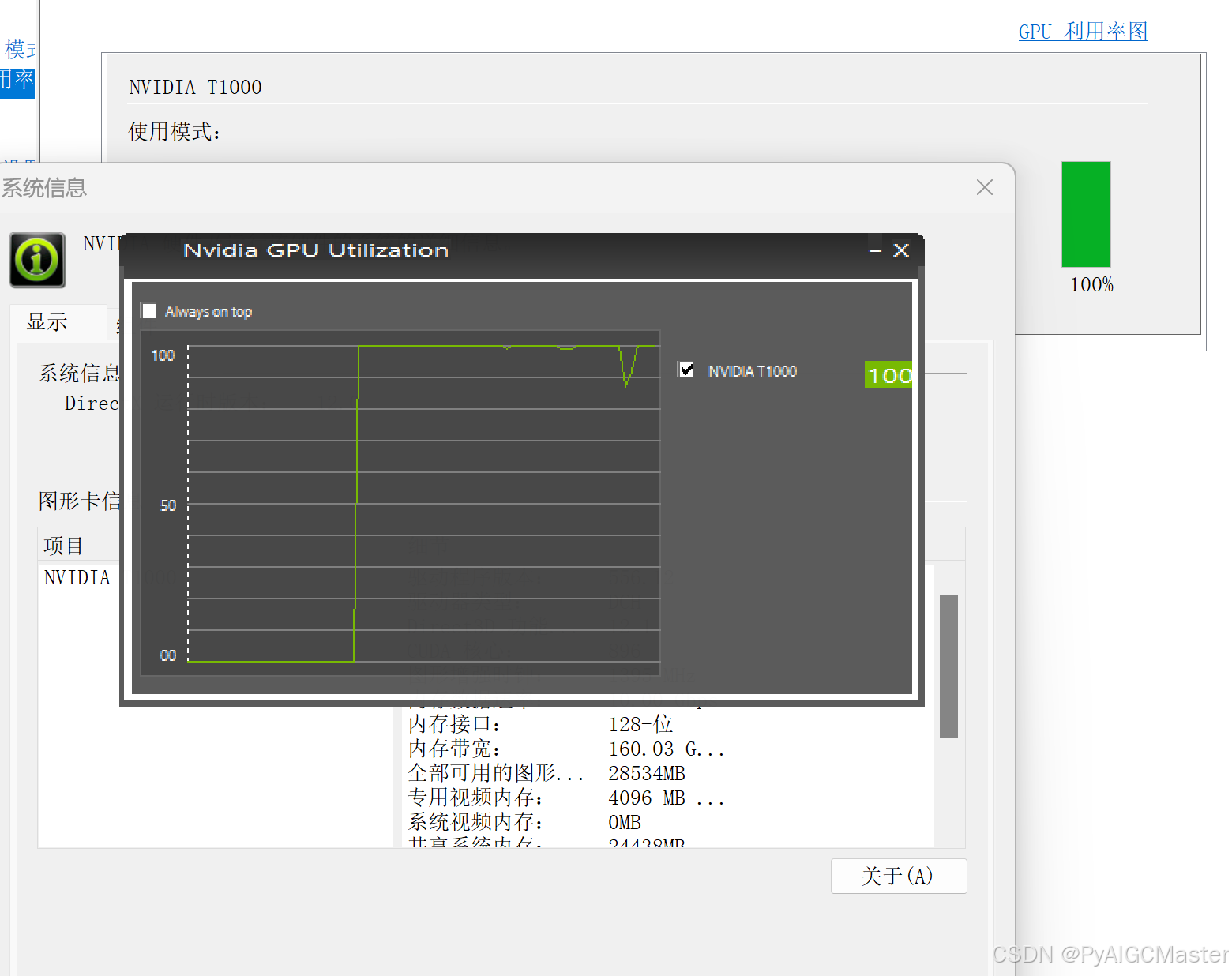
其实我这个模型安装过好多次了,老是出错。这次算是成功了。但看起来我的机器不太好。
希望你一次成功。有问题留言。


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











