







前段时间给大家介绍了阿里最强语音识别模型:
SenseVoice 实测,阿里开源语音大模型,识别效果和效率优于 Whisper
今天,它的姊妹篇来了:语音合成模型 CosyVoice,3秒极速复刻声音。
这两,堪称语音对话的完美搭档:
- SenseVoice 专注语音识别、情感识别和音频事件检测
- CosyVoice 专注语音合成,支持多语言、音色和情感控制。
能干什么?
只要是人机交互的应用场景,它都能顶。比如语音翻译、语音对话、互动播客、有声读物等。
本次分享,就带大家来体验一番,并在本地部署起来,方便随时调用。
目录
1. CosyVoice 简介
CosyVoice 的亮点总结:
- 只需3到10秒的音频样本,便能够复刻出音色,包括语调和情感等细节;
- 支持富文本和自然语言输入实现对情感和韵律的精细控制,使得合成语音充满感情色彩;
- 可以实现跨语种的语音合成。
官方共提供了三个版本的模型:
- 基座模型 CosyVoice-300M,支持 3s 声音克隆;
- 经过SFT微调的模型 CosyVoice-300M-SFT,内置了多个训好的音色;
- 支持细粒度控制的模型 CosyVoice-300M-Instruct,支持支持富文本和自然语言输入。
从模型架构图上,可以看出,文本输入侧,支持三种类型的输入。
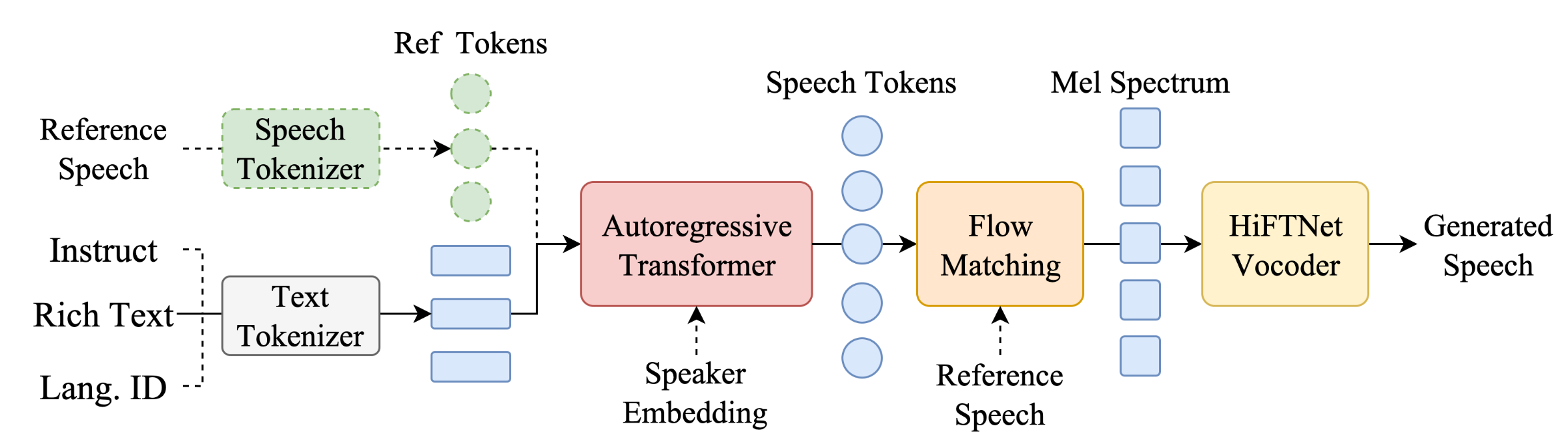
最近大火的 ChatTTS 对比,CosyVoice 在内容一致性上更优,且少有幻觉、额外多字。不得不说,CosyVoice 很好地建模了文本中的语义信息,达到了与人类发音相当的水平。
2. 在线体验
操作比较简单,多点一点就熟悉了~
对于开发者而言,一个好的工具,自然是要能够随时调用的,接下来我们就聊聊如何把它部署成一个服务,方便集成到的你的应用中去。
3.本地部署
本打算采用 ModelScope 的 GPU 实例进行演示,不过安装conda环境出现各种问题,最终还是弃用了。
今天给大家推荐一个云 GPU 厂商,新人注册送 100 点算力,还没使用过的小伙伴赶紧去薅羊毛:驱动云注册
virtaicloud 不仅是新人福利诚意满满,而且远程连接非常方便。此外,不用担心你的数据丢失:
- 项目空间中,
/gemini/code中的文件,会持久保存; - 只要将当前环境采用 dockerfile 构建为新镜像,项目依赖就会持久保存。
3.1 申请云实例
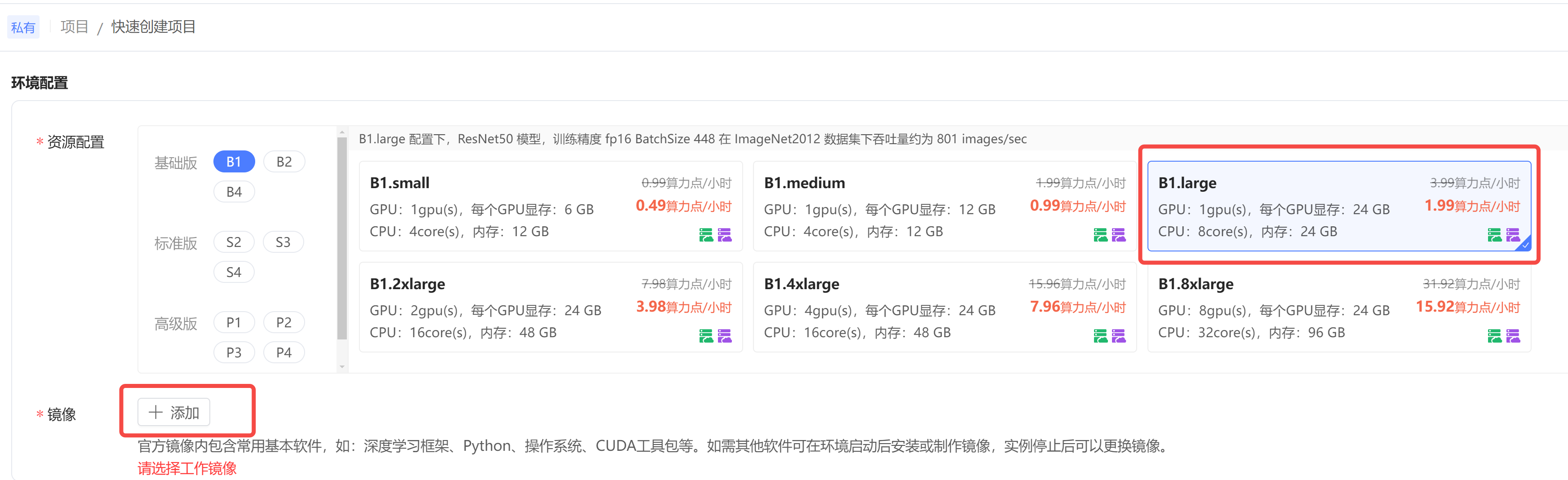
注册成功后,点击快速创建项目。
step1: 资源配置:选择一张 6G 的显卡就够
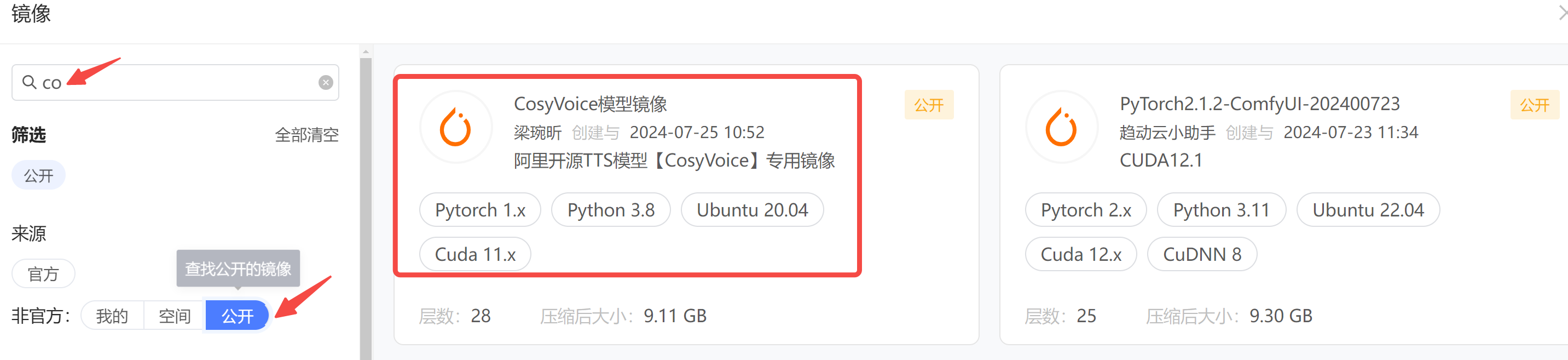
step2: 选择镜像,社区已有小伙伴做好了 CosyVoice 的镜像,拿来用就行,搜索框输入 cosy,从公开镜像中查找。
step3: 数据配置,社区已有小伙伴上传了 CosyVoice 的模型,赶紧挂载进来,否则接下来下载模型你会很痛苦(太慢了😂)。

step4: 下方开启 SSH 远程连接,点击立即启动。

等待机器分配并启动,成功后,在右侧可以看到 SSH 远程连接的指令:
VS Code 访问服务器需要在本地进行一番配置,不了解的小伙伴可以回看:【保姆级教程】Windows 远程登陆 Linux 服务器的两种方式:SSH + VS Code。
具体到这台云主机,ssh 配置如下:
Host virtaicloud
HostName ssh.virtaicloud.com
Port 30022
User action@root@ssh-09cecba52bec4fd832630062e8be5d5e.fbrmebdsfcjp
然后,到平台设置一个登录密码:
远程登录成功后,可以看到是 python 3.8 的环境:
(base) root@gjob-dev-475943020991115264-taskrole1-0:~# python -V
Python 3.8.18
3.2 环境准备
实例启动后,打开一个终端,下载项目源码。
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
项目依赖 python 3.8 环境,因为镜像已经装好了项目所需的依赖,所以这一步可以跳过。
conda create -n cosyvoice python=3.8
conda activate cosyvoice
conda install -y -c conda-forge pynini==2.1.5
pip install -r requirements.txt
3.3 模型准备(可选)
如果你在申请实例时,已经挂载了模型,可以跳过这一步,否则只能 kill 掉实例,才能在项目中重新挂载。
挂载的模型路径在:/gemini/pretrain,我们可以建立一个软链接:
ln -s /gemini/pretrain pretrained_models
然后安装 ttsfrd:
cd pretrained_models/CosyVoice-ttsfrd/
pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
当然你也可以选择在项目中下载模型,如果速度你能忍的话~
ModelScope 模型下载有多种方式,其中命令行下载可以实时看到下载进度,相对友好一些。运行下方指令,下载所需模型:
mkdir pretrained_models
modelscope download --model=iic/CosyVoice-300M --local_dir pretrained_models/CosyVoice-300M
modelscope download --model=iic/CosyVoice-300M-SFT --local_dir pretrained_models/CosyVoice-300M-SFT
modelscope download --model=iic/CosyVoice-300M-Instruct --local_dir pretrained_models/CosyVoice-300M-Instruct
modelscope download --model=iic/CosyVoice-ttsfrd --local_dir pretrained_models/CosyVoice-ttsfrd
3.3 本地测试
因为项目依赖第三方库 third_party/Matcha-TTS,所以要加入到 Python 环境变量中:
export PYTHONPATH=third_party/Matcha-TTS
3.3.1 sft 模型测试
当前支持的音色包括:[‘中文女’, ‘中文男’, ‘日语男’, ‘粤语女’, ‘英文女’, ‘英文男’, ‘韩语女’]。你需指定其中一个音色,然后进行语音合成:
from cosyvoice.cli.cosyvoice import CosyVoice
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-SFT')
# sft usage
print(cosyvoice.list_avaliable_spks())
output = cosyvoice.inference_sft('你好,我是通义生成式语音大模型,请问有什么可以帮您的吗?', '中文女')
torchaudio.save('sft.wav', output['tts_speech'], 22050)
3.3.2 基座模型测试
下方示例为 音色克隆,输入一段 3s 以上的音频即可,模型会生成该音色的语音:
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M')
# zero_shot usage, <|zh|><|en|><|jp|><|yue|><|ko|> for Chinese/English/Japanese/Cantonese/Korean
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
output = cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k)
torchaudio.save('zero_shot.wav', output['tts_speech'], 22050)
此外,模型还支持跨语言合成,也即输入是中文的语音,只复刻其中的音色,输出英文的语音:
# cross_lingual usage
prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
output = cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k)
torchaudio.save('cross_lingual.wav', output['tts_speech'], 22050)
3.3.3 Instruct 模型测试:
该模型支持细粒度的情绪控制,当前支持的富文本包括
<laughter></laughter>:中间的文本带有微笑语气;<strong></strong>:中间的文本带被刻意强调;[laughter][breath]:分别是笑声和深呼吸。
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-Instruct')
# instruct usage, support <laughter></laughter><strong></strong>[laughter][breath]
output = cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.')
torchaudio.save('instruct.wav', output['tts_speech'], 22050)
3.4 WebUI
项目中支持一键部署 webui,不过只能挂载一个模型,需要指定 model_dir:
python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M
服务部署在 5000 端口上,为了能在公网访问,
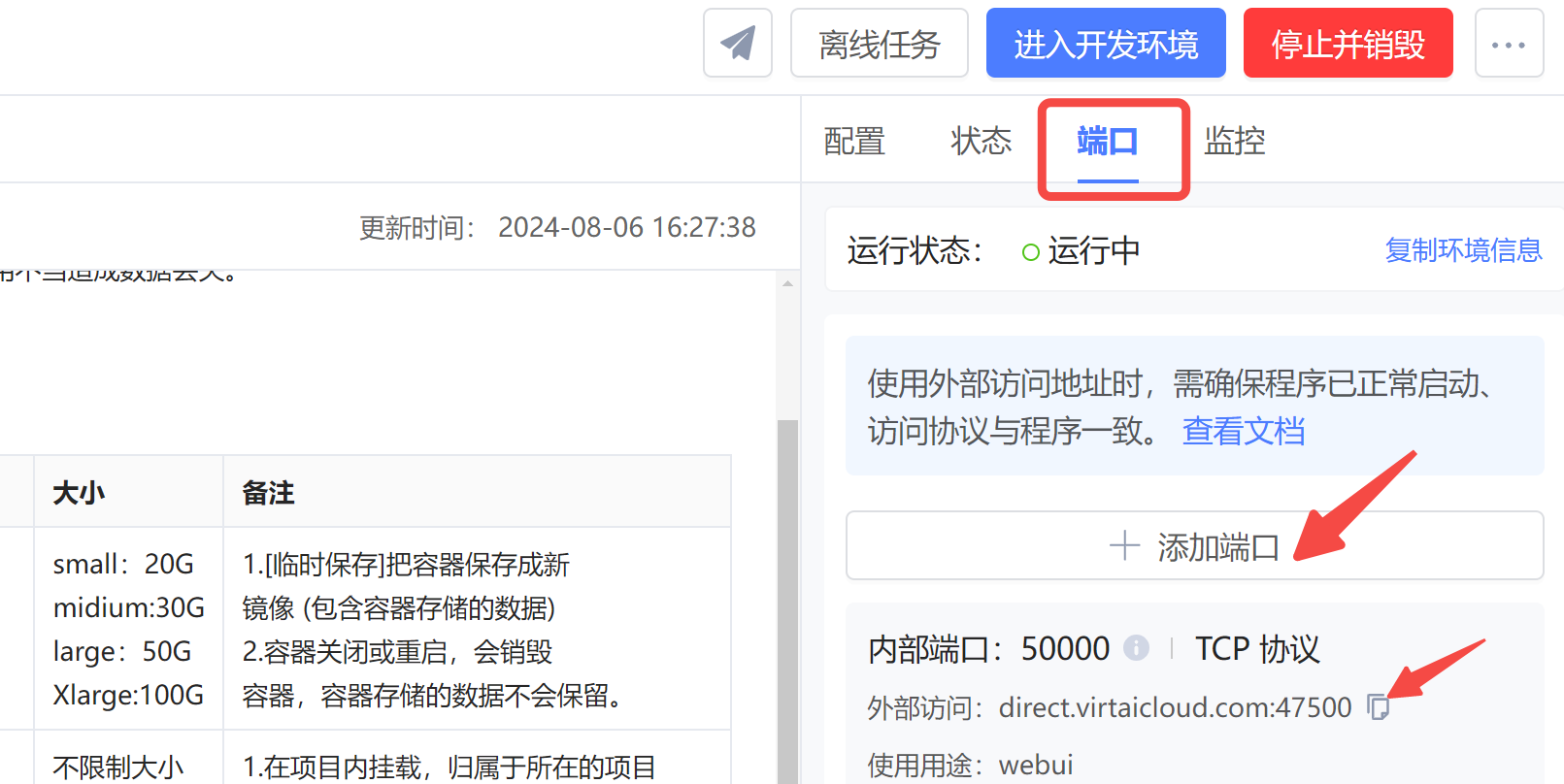
打开浏览器试试吧~
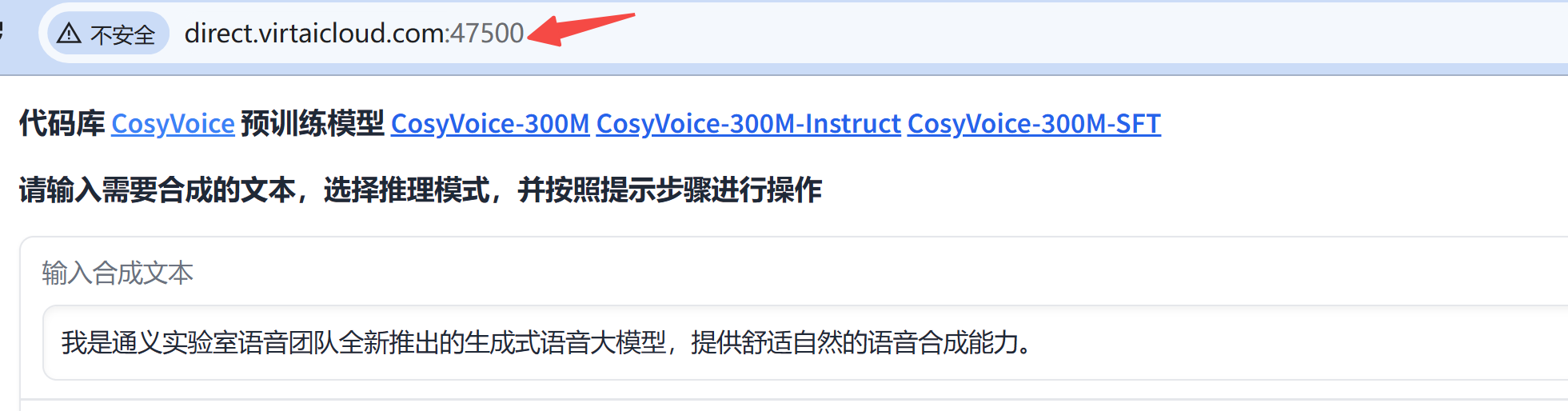
当然,如果你是 vscode 远程连接,那么 vscode 默认会自动把 50000 端口映射出来,所以localhost:50000 也是可以访问的。
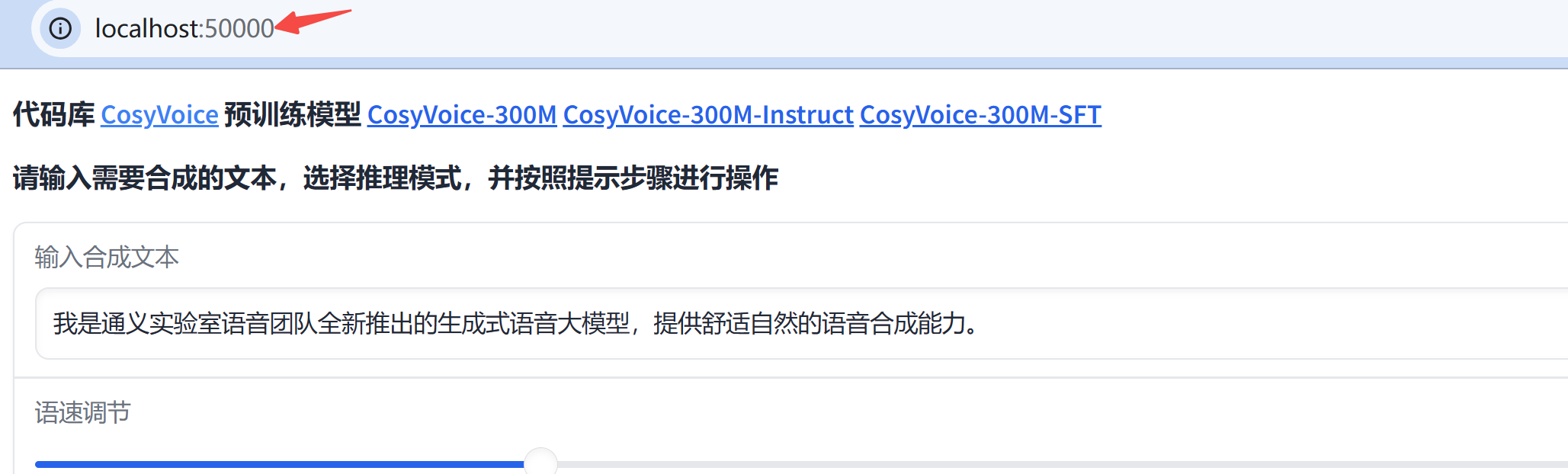
最上方输入待合成的文本,我们选择 3s 极速复刻, prompt 文本处输入音频对应的文本。
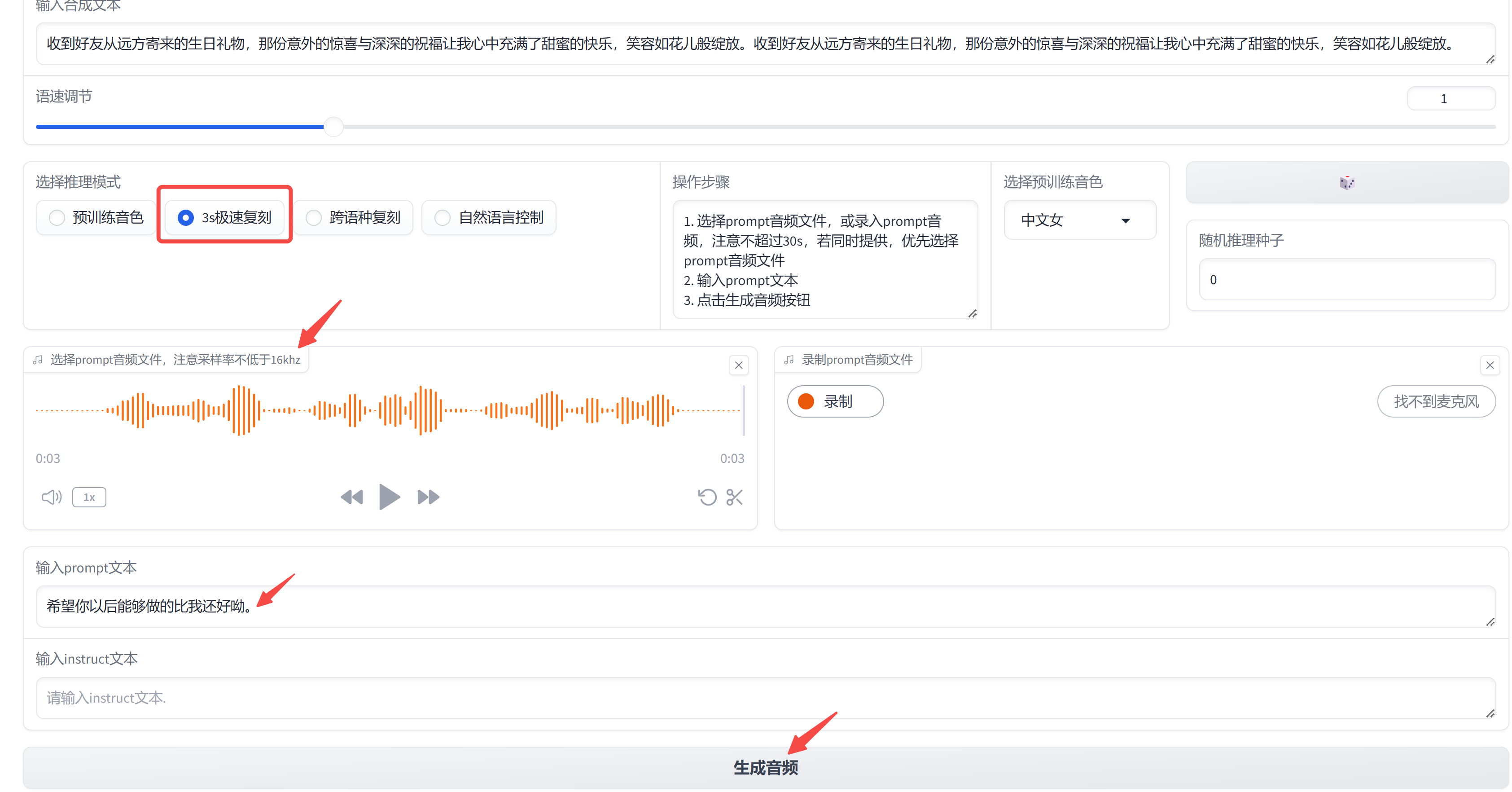
3.5 服务部署
3.5.1 服务端部署
项目支持 fastapi 部署,因此我们通过如下代码,启动服务端。
cd runtime/python/fastapi
export MODEL_DIR=/gemini/code/CosyVoice/pretrained_models/CosyVoice-300M-SFT
uvicorn server:app --host 0.0.0.0 --port 50000 --reload
简单解释下上面的代码:server.py 中需要指定MODEL_DIR环境变量,所以我们在命令行中给出。
- uvicorn server:app:启动 Uvicorn 服务器,server:app 表示在 server.py 文件中找名为 app 的 FastAPI 实例。
- –host 0.0.0.0:使服务器可以通过任何 IP 地址访问。
- –port 50000:指定服务器监听的端口。
- –reload:在开发模式下启用热重载,以便在代码更改时自动重启服务器。
稍等片刻让模型加载进显存,看下如下提示,代表服务已经正常启动:
INFO: Application startup complete.
3.5.2 客户端调用
客户端调用代码在 client.py,支持多种模式输入:
python client.py --api_base http://127.0.0.1:50000 --mode <sft|zero_shot|cross_lingual|instruct>
参数设置如下:
- –api_base:请求地址,由于我们已经在 virtaicloud 控制台中将端口映射了出来,所以直接请求
http://direct.virtaicloud.com:47500,也是 OK 的。 - –mode:推理模式,包括
<sft|zero_shot|cross_lingual|instruct>
更多参数设置可参考 client.py。
3.6 显存占用情况
给大家看下,显存占用情况:
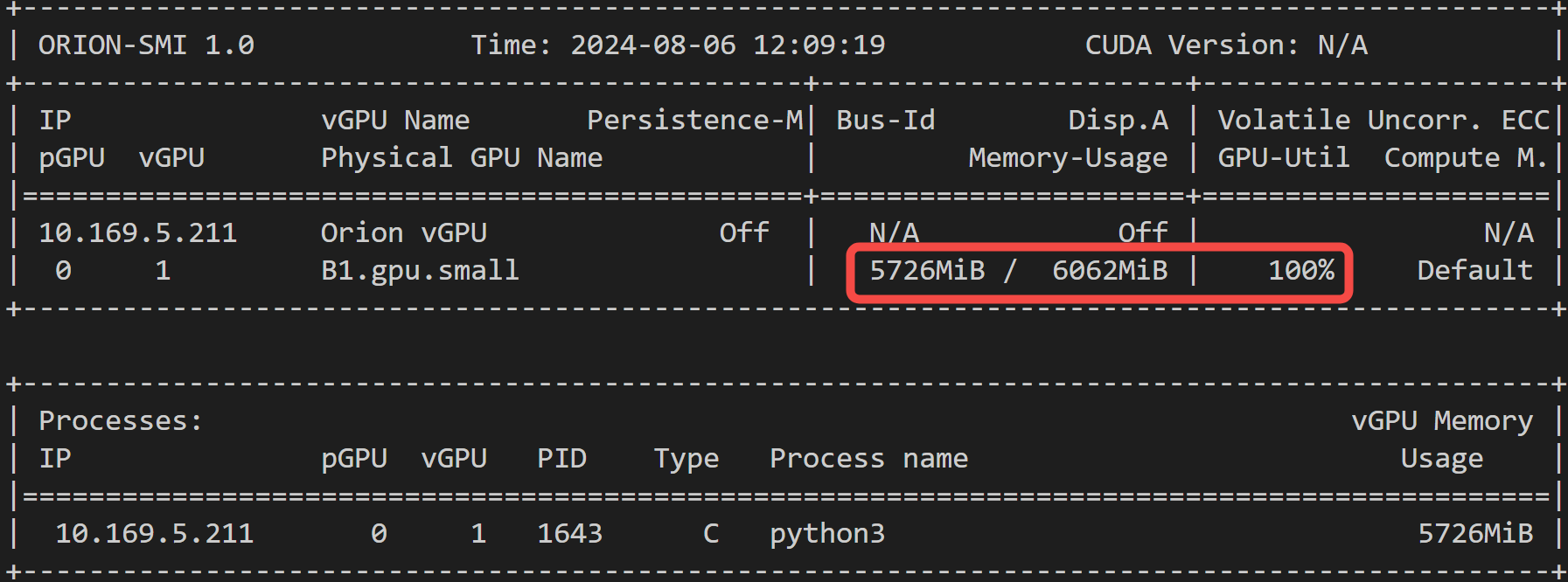
模型推理,大约占用 < 6G 显存,比 ChatTTS 略高~
选用趋动云的最小算力规格:B1.small,完全足够,一天合计花费为:0.49 算力点/小时 x 24 = 12 元。
12 元拥有一台 24 小时为你服务的语音合成工具,可还香?
目前新人注册送 100 点算力,推荐大家去薅羊毛:https://platform.virtaicloud.com/gemini_web/auth/register?inviteCode=b702f65cfe99e8cf10900a650fdc00c6
写在最后
从 GPT-SoVITS 到 CosyVoice,时隔不过两月,而语音克隆的难度已经极大降低,堪称 0 门槛了,一个人人有嘴替的时代已经到来。
你确定不去试试么?
关于开源 AI 大模型的文章,我打算做成一个专栏,目前已收录:
- CogVideo 实测,智谱「清影」AI视频生成,全民免费,连 API 都开放了!
- 全网刷屏的 LLaMa3.1,2分钟带你尝个鲜
- SenseVoice 实测,阿里开源语音大模型,识别效果和效率优于 Whisper
- EasyAnimate-v3 实测,阿里开源视频生成模型,5 分钟带你部署体验,支持高分辨率超长视频
- 开源的语音合成项目-EdgeTTS,无需部署无需Key
- 一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音
- FLUX.1 实测,堪比 Midjourney 的开源 AI 绘画模型,无需本地显卡,带你免费实战
后面会定期更新,感兴趣的小伙伴欢迎关注。
如果本文对你有帮助,欢迎点赞收藏备用。

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









