







前言
从你早上睁眼看到的今日头条推荐,到深夜刷到的抖音神评,人工智能大模型已经成为我们工作生活不可或缺的部分。但通用模型在专业场景的"人工智障"表现,让微调技术成为专业领域AI落地的最后1公里。
微调技术是指在预训练模型基础上,使用专业领域特定数据,指定特定方法对大模型参数进行调整,使其适应专业任务或领域。微调大模型可实现如下功能:
- 更新 + 学习新知识:注入并学习新的特定领域信息,例如“法衡大模型”在Llama模型基础上使用法律文本微调,以进行合同分析、判例法研究和合规性检测。
- 自定义行为:调整模型的语气、个性或响应样式,网络上流行的“甄嬛”对话风格大模型就是基于甄嬛风格对话数据集对Qwen模型微调。
- 针对任务进行优化:提高特定用例的准确性和相关性,例如训练大模型以预测标题对公司的影响是正面还是负面。
微调技术如此强大自然也涌现出了多种大模型微调工具,比较流行的有LlamaFactory、 Unsloth等,我也曾出两篇教程分享这两种微调工具的使用方法:
然而微调过程中形形色色的参数设置使得缺少深度学习调参经验的同学相当困惑,总有人后台私信我有没有一个通用经验设置帮助大家快速上手微调呢?最近在查阅Unsloth官方文档时意外发现Unsloth官方推出的初学者微调指南,原文Fine-tuning Guide | Unsloth Documentation。本次分享我就结合工作相关经验和官方文档整理一份适用于大模型初学者的微调指南。
微调第一步:选择合适的模型+微调方法
无论是Unsloth还是笔者工作实践,在选择微调模型时,即使你的显卡资源足够丰富,也要先从参数量较小(小于14B)的Instruct模型开始,检测你的数据集是否适合微调任务。例如你想微调Qwen2.5-72B-Instruct模型,你应该先选择Qwen2.5-7B-Instruct进行微调测试,然后逐步提高模型参数量。
微调方法大家一般只需要在Lora和QLora中做出选择,两者的特点如下, Unsloth官方默认是QLora方法,因为该方法消耗模型显存更小。如果你使用LLamaFactory训练模型也可以选择QLora方法。
- LoRA: 微调 16 位的小型可训练矩阵,无需更新所有模型权重。
- QLoRA: 将 LoRA 与 4 位量化相结合,以最少的资源处理非常大的模型。
微调第二步:选择合适的模型设置
选择完成合适的模型和微调方法后,通常还需要设置三个参数:
max_seq_length
默认设置为 2048, 该参数控制大模型输入输出的上下文长度。虽然一些模型支持 8192甚至更大的上下文长度,但Unsloth仍建议先使用 2048 进行微调测试,然后再使用2048的倍数4096、8192等逐步扩展。
dtype
Unsloth默认设置为None, 会根据我们的显卡类型自动检测。目前大模型的参数类型通常为torch.float16,在一些性能强劲的显卡例如A100或H100等显卡上可以设置为torch.bfloat16。 torch.bfloat16与torch.float16两者都是16位浮点数格式,torch.bfloat16格式能表示数字范围更大,更适合大模型训练,尤其是在A100/H100显卡上有专门优化。torch.float16精度高,但容易溢出,更适合精细度高的推理任务。
load_in_4bit
默认为True,采用4bit量化模型进行微调,虽然会损失约1%左右的精度,但是4bit模型占用的计算资源更小,更适合快速微调验证任务。如果你想完全微调模型需要设置full_finetuning = True ,如果想使用8 bit量化模型微调需要设置load_in_8bit = True。
使用Unsloth完成模型选择和设置的代码如下,这里以QwQ-32B 的unsloth 4bit量化版为例:
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./QwQ-32B-unsloth-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
微调第三步:准备数据集
对于大模型来说,数据集是可用于训练模型的数据集合。为了使训练有效,文本数据需要采用固定标记的格式。对于 继续预训练(CPT) 我们要采用的数据集格式如下, 只需要一个text字段的json数据即可
[{
"text": "Pasta carbonara is a traditional Roman pasta dish. The sauce is made by mixing raw eggs with grated Pecorino Romano cheese and black pepper. The hot pasta is then tossed with crispy guanciale (cured pork cheek) and the egg mixture, creating a creamy sauce from the residual heat. Despite popular belief, authentic carbonara never contains cream or garlic. The dish likely originated in Rome in the mid-20th century, though its exact origins are debated..."
}]
继续预训练适用于让模型理解专业领域字词之间的关联关系,但并不适合直接让大模型学会专业领域的语言表述。
对于文本的微调我们一般直接使用监督微调(SFT),采用的数据集格式是 Alpaca风格的Instruction格式, 格式如下:
“instruction”:必选, 我们希望模型执行的任务。
“input”: 可选,它本质上是我们除指令外的额外输入
“output”: 任务的预期结果和模型的输出。
以使用python编写列表排序代码为例:
“instruction”:请帮我编写一个python列表排序程序并对我提供的列表排序
“input”: 我的python列表是[0,1,23,4]
“output”:
不过 Alpaca风格的Instruction格式不适用于多轮对话,多轮对话常用的格式是ShareGPT或ChatML格式。
ShareGPT格式:
{
“conversations”: [
{
“from”: “人类”,
“value”: “你能帮我做意大利面培根蛋面吗?”
},
{
“from”: “gpt”, /
“value”: “您想要传统的罗马食谱,还是更简单的版本?
},
{
“from”: “人类”,
“value”: 请用繁体版本”
},
{
“from”: “gpt”, /
“value”: “正宗的罗马培根蛋面只使用几种成分:意大利面、番荔枝、鸡蛋、罗马佩克里诺和黑胡椒。你想要详细的食谱吗?
}
]
}
ChatML格式:
{
"messages": [
{
"role": "user", # user表示用户
"content": "What is 1+1?"
},
{
"role": "assistant", # assistant表示大模型
"content": "It's 2!"
},
]
}
以上数据集基本可以满足我们日常的微调任务了,当然微调除了SFT还有强化学习RL, 大模型函数工具调用学习ToolUse, 这些场景下的数据集格式大家可以参考数据集指南 |Unsloth 文档 或LlamaFactory数据集格式指南
微调第四步:模型训练参数设置
不得不说这部分微调的参数设置组合有成百上千种,而且我们既要设置Lora微调方法的参数,又要设置整体微调流程的超参数,选择正确的参数组合对好的微调结果至关重要。Unsloth默认的参数选择一般来说就是相对合理的,大家即使修改也希望参照下面的经验:
Lora参数设置:
r = 16
微调过程的等级。默认为16, 较大的数字会占用更多内存,并且速度会变慢,但可以提高更难任务的准确性。这里建议先保持默认,然后从8、16、32、64、128这几个数字进行尝试。target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],
默认选择所有模块进行微调。强烈不建议删除一些模块以减少内存使用量以加快训练速度,这通常会有难以分析的问题。lora_alpha = 16微调的比例因子。较大的数字能使微调收敛更快,但可能会引发过度拟合情况。建议等于r或是r的倍数。lora_dropout = 0默认为0即可,如果出现过拟合的情况可以适当调大,但不要超过0.5。bias = "none"默认为none即可,这样可以避免过拟合。use_gradient_checkpointing = "unsloth"默认为unsloth, 可以使内存使用量额外减少了30%,并支持极长的上下文微调,默认即可。random_state = 3407确定性运行数的编号。只要保持该数字和其它参数一致,训练的过程就可以复现。use_rslora = False高级功能,一般用不到保持False即可。loftq_config高级功能,用于将 LoRA 矩阵初始化为权重的前 r 个奇异向量。可以在一定程度上提高准确性,但可能会使内存使用量在开始时呈爆炸式增长,一般设置为None。
Unsloth设置Lora微调参数的代码如下,即使微调效果有偏差,我们也可以按照建议范围修改Lora参数设置。
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
更精确的Lora参数设置可查阅🧠LoRA 超参数指南
整体微调流程超参数
要了解整体微调流程的超参数设置,我们首先要知道什么是过拟合和欠拟合现象:
过拟合与欠拟合
过拟合: 该模型会记住训练数据,但对其它领域的通识理解会变弱,相当于“学傻了”只知道微调的专业领域数据集种的知识,大模型的泛化能力和创造性大大降低。
欠拟合: 缺乏合适的学习参数而导致模型无法从训练数据中学习到知识,提问模型专业领域相关情况模型还是无法正确回答。
整体微调流程超参数详解
整体微调流程主要关注如下超参数:
learning_rate学习率:
定义模型权重在每个训练步骤中调整的程度。
- 较高学习率: 更快的训练,减少过拟合,但过高的学习率会导致过拟合.
- 较低学习率:更稳定的训练,可能需要更多的 epoch,也可能导致欠拟合.
- 建议范围:1e-4 (0.0001) 至 5e-5 (0.00005)。
num_train_epochs训练轮数
模型训练专业数据的次数,设置训练轮数为3,模型会使用你的数据训练三个回合。
- 推荐: 虽然Unsloth推荐1-3 (超过 3 个通常不是最佳选择,除非你希望你的模型幻觉少得多且缺少相关领域创造性)。但结合自己工作实践我们采用专业领域训练还是要尽量避免大模型产生过多幻觉,我建议可以尝试1-50之间的值,超过50基本不是最好选择。
- 较多Epochs:更好的学习但有更高的过拟合风险。
- 较少Epochs:可能会导致模型欠拟合。
per_device_train_batch_size = 2
增加该值以提高 GPU 利用率,但要注意增加该值会导致训练速度变慢,显存资源足够可以适当调高该值。
gradient_accumulation_steps = 4
在不增加内存使用量的情况下模拟更大的批处理大小,显存资源足够可以适当调高该值。
使用Unsloth完成整体流程微调的代码如下:
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs = 3,
warmup_steps=5,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
避免过拟合和欠拟合现象经验
避免过拟合:
- 降低学习率
learning_rate。 - 增加批量
per_device_train_batch_size大小。 - 减少训练
epoch的数量。 - 将数据集改写为
ShareGPT格式 - 提高
dropout rate以引入正则化。
避免欠拟合:
- 提高学习率
learning_rate。 - 增加训练
epoch的数量。 - 提高Lora参数
r和lora_alpha。lora_alpha应至少等于r,r通常在 4 -64 之间,对于较小的模型或者更复杂的数据集应该更大。
值得注意的是:微调没有单一的 “最佳” 方法,只有最佳实践。实验是找到最适合参数的关键。虽然Unsloth 默认参数是根据研究论文和过去实验数据的最佳实践,但有时我们需要自己尝试这些参数才能获得最佳匹配。
微调第五步:训练+评估
在训练时,Unsloth会打印一些数字日志,它表示训练损失,大家的目标是使训练损失尽可能接近 0.5!如果微调损失未达到 1、0.8 或0.5,我们需要继续调整参数。微调模型不是一个确定性步骤,它往往需要我们不断调整上面介绍的参数,这就是大家所谓的“炼丹”过程。
如果大家发现损失变为 0,那说明你的模型过拟合了,需要降低epoch数量或者学习率learning_rate来避免过拟合。
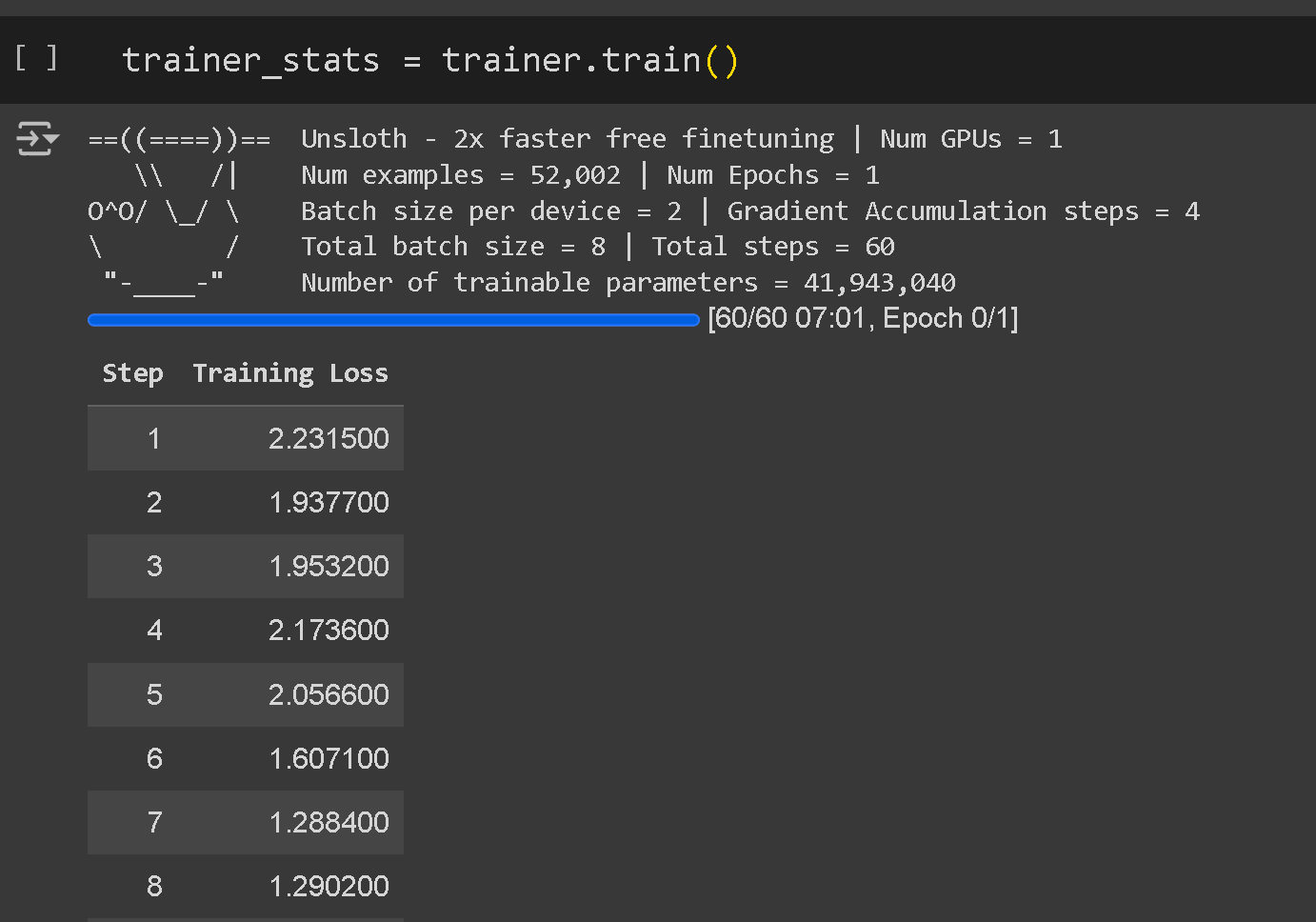
模型评估阶段大家一般选取20%的训练数据作为测试集(这部分数据集不参与训练),运行微调后模型进行人工评估。大家也可以直接通过 Unsloth 启用评估,设置evaluation_steps = 100。但这个会增加Unsloth训练的时间。还有一种方法是使用自动评估工具,例如 EleutherAI 的 lm-evaluation-harness。不过切记自动化工具可能无法完全符合评估标准。
大家在评估时可以使用如下代码:
FastLanguageModel.for_inference(model) # 开启推理模式
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda") # promt_style是提示词模板(自行设置),问题替换为自己问题
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
微调第六步:保存模型
trainer.train()运行完成后可以保存模型,Unsloth提供了多种保存模型的方法:
- 保存Lora适配器:只保存相对于原始模型增加的Lora参数(几百MB左右),不会融合新增加部分和原始模型。使用的代码是:
model.save_pretrained("lora_model")
tokenier.save_pretrained("lora_model")
- 保存完整模型safetensors格式:一般情况下我们需要保存完整的模型,可以使用如下代码,保存后格式与modelscope和huggingface上模型格式类似,可使用vllm等框架部署推理服务。
model.save_pretrained_merged("model", tokenizer, save_method = "merged_4bit",) #4位量化版
model.save_pretrained_merged("model", tokenizer, save_method = "merged_16bit",) #16位量化版
- 保存完整模型GGUF格式:这种格式适合采用Ollama部署,代码如下:
model.save_pretrained_gguf("dir", tokenizer, quantization_method = "q4_k_m") # q4量化版
model.save_pretrained_gguf("dir", tokenizer, quantization_method = "q8_0") # q8量化版
model.save_pretrained_gguf("dir", tokenizer, quantization_method = "f16") # float16版
以上就是Unsloth微调参数设置的全部经验内容啦!
总结
本篇分享我们基于Unsloth官方文档结合工作种微调经验,为大家提供了合适的参数选择范围,帮助大家从成百上千种参数组合中快速定位到最优组合,加速微调过程,让初学者也能简单快速上手大模型微调。还在等什么,赶紧按照分享建议的方案去微调属于你的专业领域大模型吧!
屏幕前的各位如果对文章内容感兴趣可点关注,我会分享更多工作实践中的大模型内容。 也可关注我的同名微信公众号:大模型真好玩,免费分享工作生活中大模型开发知识点和实践经验,大家有什么需求都可通过公众号私信我呦~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









