







DeepSeek R1 超详细三种部署方法
DeepSeek R1的横空出世让世界看到中国大模型的力量!我们真正从AI的追随者变成了领导者。然而DeepSeek模型如此好用的同时也带来了一些问题,由于使用人数过多(同时还有美丽国大量的IP攻击)导致了DeepSeek的服务器不堪重负,经常出现服务器繁忙的情况。对于个人用户或中小企业用户来说,稳定的运行环境是十分重要的,同时由于一些场景下数据隐私与安全,成本效益,定制化拓展等问题,使得 本地部署DeepSeek大模型迫在眉睫。
众所周知,DeepSeek R1模型参数量异常庞大,达到671B,大小约达到720GB,所占用的显存空间非常大,即便是 8张A100显卡 A100 * 8 GPU (80GB * 8 = 640GB < 720GB)运行起来也非常困难,有博主估计运行一天的算力成本约等于900元,这对于个人用户和中小企业是不可接受的。那我们普通人就不配玩大模型嘛?当然不是,在DeepSeek R1发布后的这段时间里,各大科技公司(hugging face, unsolth),高校( 清北)都在想方设法降低DeepSeek R1本地部署成本,也产生了很多成果。
今天笔者就向您分享三种DeepSeek R1本地部署的方法,适合个人用户和中小企业,大家一起来看一看~
一、DeepSeek R1 官方蒸馏模型(7B-70B),适合个人用户
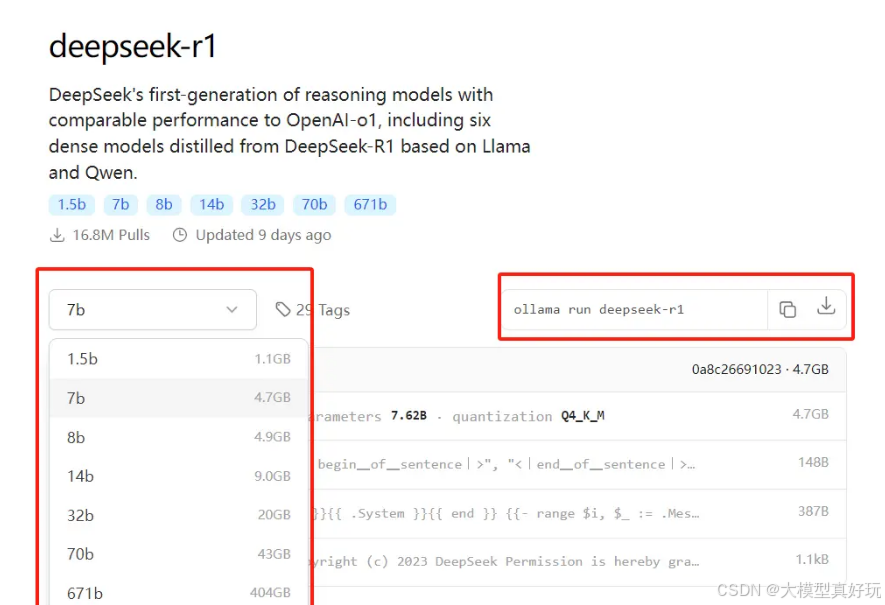
DeepSeek R1 官方 使用DeepSeek R1 技术报告中提及的模型蒸馏方法对qwen和llama开源模型进行了模型蒸馏 (对模型蒸馏概念不熟悉可以看笔者文章 大模型瘦身指南 )。 大家可以使用Ollama在本地下载并运行大模型,关于Ollama 使用教程大家也看一看我的文章人工智能大模型入门分享(一)——利用ollama搭建本地大模型服务(DeepSeek-R1) ,下图是Ollama官方网站中列出的DeepSeek-r1的蒸馏版本,右侧红色框内容是使用ollama 下载运行大模型的命令。
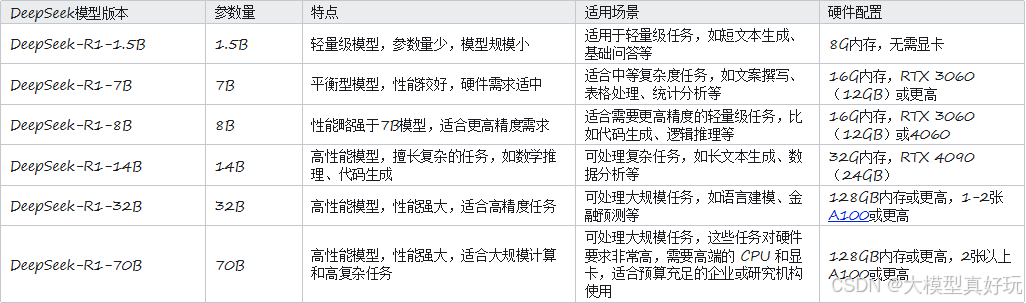
本文也列出了不同大小蒸馏模型对应的配置条件,大家可按需下载使用:
二、满血版DeepSeek量化模型, 适合显存>200G的个人用户,实验室,中小企业
目前HuggingFace有两款常见的DeepSeek 671B 量化( 对量化概念有疑问的也可以看通俗易懂的讲解 大模型瘦身指南 )的模型,分别为:
- DeepSeek-R1-Q4_K_M (671B, 8 -> 4 位标准, 404 GB, HuggingFace Ollama)
- DeepSeek-R1-UD-IQ1_M(671B,动态量化 8 ->1.73 位,158 GB,HuggingFace Unsloth)
DeepSeek-R1-Q4_K_M是直接将FP8格式的模型转换为QINT4格式模型,减少了将近一半有效位数。DeepSeek-R1-UD-IQ1_M 采用了更为巧妙的量化方法“动态量化” ,它的核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化。Unsloth 发布了基于 671b 完整版的动态量化版本有4个,分别是1.58bit 131GB,1.73bit 158GB,2.22bit 183GB 和 2.51bit 212GB。这些比 Ollama 里的4位量化版的 404G 大幅度减小。
我这里使用一台内存256G, 显存4张A100(40G)的实验室服务器 对1.73bit 158G的量化模型进行了部署。步骤如下:
- 从七牛云 https://algorithm.qnaigc.com/DeepSeek/DeepSeek-R1-UD-IQ1_M.gguf 地址下载.GGUF文件

- 创建 Ollama 的描述文件(最好在
OLLAMA_MODELS)环境变量目录下创建名称为DeepSeek-R1_Q_ModelFile的文件 (注意内容中的MODEL_PATH要修改为你自己的下载路径),内容如下:
FROM {MODEL_PATH}/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 28
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"
- 执行下面命令
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeek-R1_Q_ModelFile绝对路径
注意这里等待的时间会比较长,而且一定要确保你的OLLAMA_MODELS 环境变量目录中有大于170G的空间,因为这行命令会在OLLAMA_MODELS 目录下创建模型。
- 运行模型
ollama run DeepSeek-R1-UD-IQ1_M --verbose
这时我们的Ollama就跑起来大模型啦,实现的效果如下:
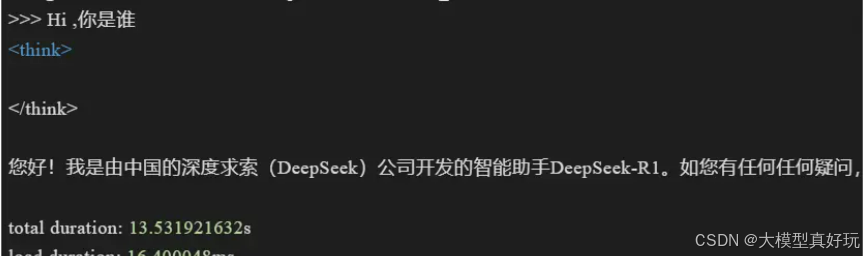
可以看到目前模型已经成功运行啦,当然模型也可以接入我们以前文章中曾讲到的page assist完成在Web界面的访问,更方便大家使用,这里就不赘述啦。感兴趣可参考 人工智能大模型入门分享(一)——利用ollama搭建本地大模型服务(DeepSeek-R1) .
要注意的是从实际使用效果来看,个人认为量化模型的能力相当于满血版R1能力的80%,对于比较“刁钻”的逻辑思考问题,量化版本还是比R1的全量版本要差一些意思,但对于日常使用已经绰绰有余,比蒸馏版的模型强了很多倍。
三、KTransformers 部署满血版DeepSeek-R1 Q4模型, 内存>380G, 仅需一张4090显卡,适合个人用户和中小企业
特别关注:由于篇幅原因,这部分内容只列出了我的大体步骤,大家如果想了解一步一步更详细内容,可以关注微信公众号: 大模型真好玩,并私信 DeepSeek-R1高性能部署, 会收到43页pdf: 使用KTransformers工具从部署到开发的全部流程**,谢谢大家的支持~,撒娇打滚求点赞!!!
KTransformers 是清华大学KVCache.AI团队与趋境科技合作推出开源项目,在2025年2月15日的更新中,KTransformers项目 只需要 > 380G的内存和一张4090显卡,就可以部署满血版DeepSeek-R1 Q4量化模型(大约404GB),对AI计算能力的一个全新突破。官方文档在:https://github.com/kvcache-ai/ktransformers/blob/v0.2.0/doc/en/DeepseekR1_V3_tutorial.md 或 https://kvcache-ai.github.io/ktransformers/en/install.html 。目前来看支持Linux和Windows双系统,我这里用Ubuntu进行尝试。
简单介绍一下 KTransformers 的核心技术主要体现在异构计算策略上,具体包括稀疏性利用、量化与算子优化以及CUDAGraph加速等几个方面,它利用了DeepSeek-R1的MoE(混合专家)架构,仅在需要时激活部分专家模块,大幅减少了对显存的需求。同时,该项目团队将非共享的稀疏矩阵卸载至CPU内存,从而实现了显存占用的压缩,成功让24GB显存的RTX 4090承担起重任。
下面废话不多说,马上我们的实操:
- 下载
DeepSeek-R1-Q4模型, 网址在: https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-Q4_K_M ,注意模型还是比较大的,需要花费较多下载时间。 - 使用git 拉取 KTransformers 代码并编译:
# git clone https://github.com/kvcache-ai/ktransformers.git
# cd ktransformers
# git submodule init
# git submodule update
# export USE_NUMA=1 # 如果你是64核的CPU需要执行该条指令,否则不需要。
# make dev_install
编译的速度还是很慢的,直到出现字样 Installation completed successfully 表示编译成功:
- 执行命令并运行
python ./ktransformers/local_chat.py --model_path <希望模型保存路径> --gguf_path <第一步下载的GGUF路径> --cpu_infer 65 --max_new_tokens 1000
这里运行时有时会报没找到 flash-attention的错误,这里可以根据自己的pytorch和cuda版本来安装, 具体可参考博客 https://blog.csdn.net/Changxing_J/article/details/139563269
执行完该命令后大家也需稍等片刻,因为需要加载大量参数,跑通之后就卡而已看到如下界面啦,我这里输入了: 请帮我写个Rust比其它语言好的软文,可以看到效果还是不错的。

以上就是我们KTransformers的部署调用流程了。KTransformer是这个神奇架构让我们只需要一张512G内存,一张RTX4090的显卡就可以跑起来了,速度还不慢(可以看KTransformers的官方介绍),整体成本还没一张A100显卡贵,也许这就是AI开源的真正意义吧!
四、总结
DeepSeek R1大模型的横空出世,标志着中国AI从追随者跃升为领导者!然而,服务器压力和数据隐私问题催生了本地部署的需求。本文揭秘三种低成本部署方案:1. 官方蒸馏模型,适合个人用户;2. 量化模型,显存>200G的用户可享满血版体验;3. KTransformers,仅需一张4090显卡,内存>380G即可运行满血版R1。AI不再是巨头专属,普通人也能玩转大模型!🚀 (大家对人工智能大模型内容感兴趣也欢迎关注我的微信公众号: 大模型真好玩,我会实时分享在学习工作生活中遇到的大模型相关问题,也会把我工作中总结的大模型相关资料和文档分享出来,大家可关注我的csdn和公众号实时获取~)

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









