




 本文详细介绍了Linux内核中的虚拟文件系统(VFS)及其核心数据结构,包括超级块、索引节点、目录项和文件结构。还概述了文件系统的注册与注销过程。
本文详细介绍了Linux内核中的虚拟文件系统(VFS)及其核心数据结构,包括超级块、索引节点、目录项和文件结构。还概述了文件系统的注册与注销过程。
要回答为何Linux系统能够支持多种不同类型的文件系统?是怎么做到的?这就得研究一下Linux中的虚拟文件系统(简写为
VFS),才能给出答案了。
虚拟文件系统(VFS) 是一个处于内核中的软件层,它的作用为:
- 对于用户空间的程序来说,提供文件系统接口;
- 对于文件系统来说,提供一个统一抽象,由具体文件系统来实现细节。
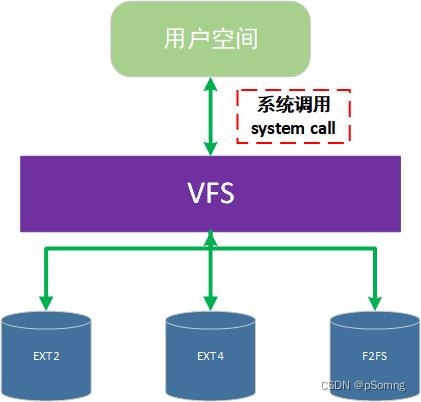
类似于面向对象思想中的接口,规范是已经统一的,而如何去实现规范就看各文件系统如何操作了。
1 VFS中的基本抽象数据结构
了解一个具体的模块,首先要从它实现的数据结构出发,理解了才能更好地解析其调用过程。
VFS核心的四个数据结构为:
super_block:超级块,用于描述具体的文件系统信息inode:索引节点,用以描述一个文件的元信息,如文件大小、权限、拥有者等,每个文件均对应一个inodedentry:目录项结构,它的出现就是为了性能,一般在磁盘中是没有对应的结构的file:文件结构,代表与进程交互过程中被打开的一个文件
1.1 超级块
一个具体的文件系统,如ext2、ext4等,都会对应一个超级块结构。内核也是通过扫描这个结构的信息来确定文件系统的大致信息,以下为其在内核源码中的部分定义(选自Linux 5.19,后续一样)
struct super_block {
struct list_head s_list; // 指向超级块链表的指针
dev_t s_dev; /* 块设备的具体标识号 */
unsigned char s_blocksize_bits;
unsigned long s_blocksize; // 文件系统中的数据块大小
loff_t s_maxbytes; /* 允许的最大文件的大小 */
struct file_system_type *s_type; // 具体的文件系统类型
const struct super_operations *s_op; // 用于超级块操作的函数集合
const struct quotactl_ops *s_qcop; // 限额操作的函数集合
unsigned long s_flags; // 安装表示
unsigned long s_magic; // 幻数 一般可以用于表示唯一的文件系统
struct dentry *s_root; //根dentry
struct rw_semaphore s_umount; // 同步读写
int s_count; // 超级块的使用计数
atomic_t s_active;
void *s_fs_info; /* 文件系统的隐私信息 */
/* c/m/atime限制 */
time64_t s_time_min;
time64_t s_time_max;
unsigned int s_max_links;
fmode_t s_mode;
// 默认的目录项操作集合
const struct dentry_operations *s_d_op; /* default d_op for dentries */
// 虽然链接数目为0 但仍然被引用
atomic_long_t s_remove_count;
// 没有被使用的dentry、inode会被加入这个
struct list_lru s_dentry_lru;
struct list_lru s_inode_lru;
struct rcu_head rcu;
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* 所有的索引节点 由前面的锁进行保护 */
spinlock_t s_inode_wblist_lock;
struct list_head s_inodes_wb; /* writeback inodes */
......
} __randomize_layout;
超级块的操作函数集合:
struct super_operations {
//给超级块分配索引节点
struct inode *(*alloc_inode)(struct super_block *sb);
// 销毁索引节点
void (*destroy_inode)(struct inode *);
// 检查atime的更新情况
void (*dirty_inode) (struct inode *, int flags);
// 写入一个inode到磁盘中
int (*write_inode) (struct inode *, struct writeback_control *wbc);
// 删除一个inode
int (*drop_inode) (struct inode *);
//在链接数目为0时会进行释放
void (*evict_inode) (struct inode *);
// 释放超级块所占用的内存
void (*put_super) (struct super_block *);
......
};
这些集合的函数会由具体的文件系统进行实现,没有实现的会被置为NULL
1.2 索引节点
Linux中是视一切为文件,一个文件就会有对应的inode,文件包含了常规文件、目录等。在需要时,在磁盘中的inode会被拷贝到内存中,修改完毕后会被写回到磁盘中。一个inode会被指向多个目录项索引(硬链接等)
以下为它在内核中的部分源码定义:
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid; // 文件所属的用户
kgid_t i_gid; // 文件所属的组
unsigned int i_flags;
const struct inode_operations *i_op; // 索引节点操作函数集
struct super_block *i_sb; // 文件所在文件系统的超级块
struct address_space *i_mapping;
/* Stat data, not accessed from path walking */
unsigned long i_ino; // 索引号
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink; // 链接数目
unsigned int __i_nlink;
};
dev_t i_rdev; // 文件所在的设备号
loff_t i_size; // 文件大小
struct timespec64 i_atime;// 最后的访问时间
struct timespec64 i_mtime; // 最后修改时间
struct timespec64 i_ctime; // 最后改变时间
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes; // 使用的字节数
/* Misc */
unsigned long i_state;
struct rw_semaphore i_rwsem; // 读写信号量
struct hlist_node i_hash; // 哈希值 负责提高查找效率
struct list_head i_io_list; /* backing dev IO list */
struct list_head i_lru; /* inode LRU list 未使用的inode*/
struct list_head i_sb_list; // 链接一个文件系统中的inode链表
struct list_head i_wb_list; /* backing dev writeback list */
union {
struct hlist_head i_dentry; // 所属的目录项
struct rcu_head i_rcu;
};
atomic64_t i_version; // 索引节点版本号
atomic_t i_count; // 引用计数
atomic_t i_writecount; // 写计数
// 文件操作函数集合
union {
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
void (*free_inode)(struct inode *);
};
struct address_space i_data;
struct list_head i_devices;
void *i_private; /* 文件与设备的私有指针 */
......
} __randomize_layout;
索引节点的函数操作集合:
struct inode_operations {
// 查找指定文件的dentry
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
//根据inode所描述的文件类型,如果是目录,则会创建一个inode,不是则不会调用
int (*create) (struct user_namespace *, struct inode *,struct dentry *,
umode_t, bool);
//在指定目录下创建一个子目录
int (*mkdir) (struct user_namespace *, struct inode *,struct dentry *,
umode_t);
//从inode所描述的目录中删除一个子目录时,会被调用
int (*rmdir) (struct inode *,struct dentry *);
......
} ____cacheline_aligned;
1.3 目录项结构
它的出现主要是为了查找性能,只存在于内存中,而不存在于磁盘中。这提供了一种非常快的查询机制来将一个路径名称(文件名称)转换为特定的目录项对象。
以下为它在内核中的部分源码定义:
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_spinlock_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list 哈希列表*/
struct dentry *d_parent; /* parent directory 父目录 */
struct qstr d_name;
struct inode *d_inode; /*与目录关联的inode Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op; // 目录项操作
struct super_block *d_sb; /* 目录项所属文件系统的超级块 The root of the dentry tree */
union {
struct list_head d_lru; /* LRU list 未使用目录项以LRU算法链接的链表*/
wait_queue_head_t *d_wait; /* in-lookup ones only */
};
struct list_head d_child; /* child of parent list 加入到父目录的d_subdirs */
struct list_head d_subdirs; /* our children 子目录 */
/*
* d_alias and d_rcu can share memory
*/
union {
struct hlist_node d_alias; /* inode alias list */
struct hlist_bl_node d_in_lookup_hash; /* only for in-lookup ones */
struct rcu_head d_rcu;
} d_u;
} __randomize_layout;
目录项的函数操作集合:
struct dentry_operations {
// 检查当前目录项是否还有效
int (*d_revalidate)(struct dentry *, unsigned int);
// 较弱形式的校验
int (*d_weak_revalidate)(struct dentry *, unsigned int);
//
int (*d_hash)(const struct dentry *, struct qstr *);
// 引用计数为0时删除dentry(dput调用)
int (*d_delete)(const struct dentry *);
// 释放所占有的数据
void (*d_release)(struct dentry *);
//当dentry失去inode时调用,
void (*d_iput)(struct dentry *, struct inode *);
......
} ____cacheline_aligned;
1.4 文件结构
当一个进程打开一个文件时,该文件就是用此文件结构进行描述的,如文件的读写模式、读写偏移量、所属inode等信息。这个文件结构会被进程的文件描述符表所存放。
以下为它在内核中的部分源码定义:
struct file {
union {
struct llist_node fu_llist; // 文件系统中被打开的文件对象(单个进程所打开的文件会被维护在另一个结构中 files_struct)
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value 被缓存的值 所属的inode吧*/
const struct file_operations *f_op; // 文件操作指针
/*
* Protects f_ep, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock; // 自旋锁
atomic_long_t f_count; // 引用计数器
unsigned int f_flags; // 打开文件所引用的标志
fmode_t f_mode; // 文件的访问模式(r模式等)
struct mutex f_pos_lock;
loff_t f_pos; // 读写偏移量
struct fown_struct f_owner; // 所属者信息
u64 f_version; // 版本号
/* needed for tty driver, and maybe others */
void *private_data; //隐私数据
struct address_space *f_mapping;
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
文件结构的函数操作集合:
struct file_operations {
.......
// 移动文件指针
loff_t (*llseek) (struct file *, loff_t, int);
// 从文件对象中读数据(系统调用中的读最终会被应用于此)
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
// 从文件对象中写数据
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
......
} __randomize_layout;
1.5 它们的关系
很早就查过
dentry、inode之间的关系了,但是过了一段时间还是会忘记它们之间的关系,这实际反映了这些关系并不是那么好去去理解的,那么在这里我就通过一张图来描述它们之间的关系。
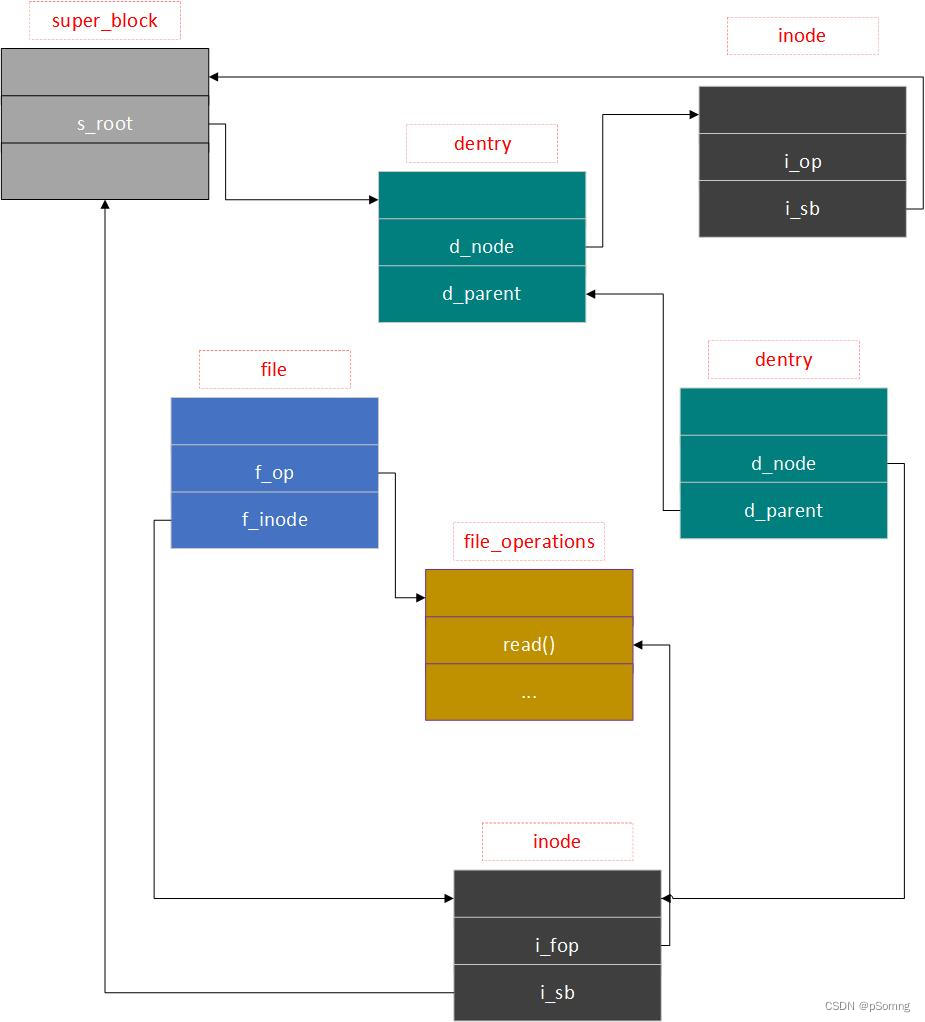
在这张图中,需要额外的关注的是,inode、dentry、super_block之间是有链接关系的,而file并不需要跟它们之间存在链接关系的(不同的Linux的大版本会存在部分不同),构建file的方式是通过解析路径而从获得dentry、inode然后再用这些数据初始化它,具体细节可以分析文件的打开流程。
这个关系也是比较简单的,实际上
inode可能会被多个dentry所指向。
2 文件系统的注册与注销
注册
前面说到VFS提供了统一的抽象接口供给具体的文件系统去实现,为了让Linux内核去发现真实的文件系统,那么就需要使用register_filesystem去注册。该函数的实现如下:
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
if (fs->parameters &&
!fs_validate_description(fs->name, fs->parameters)) // 文件系统校验
return -EINVAL;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;
// 保护资源
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name)); // 遍历已经注册的文件系统
if (*p) //已经注册
res = -EBUSY;
else// 为NULL
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
这个函数的实现思想也是很简单的,相当于是将当前fs加入到全局链表中,这样当Linux启动时,会遍历所有注册过的文件系统来识别磁盘中的文件系统(根据超级块super_block的信息)。
从函数参数可以看到,这个参数类型是struct file_system_type,所有具体的文件系统都需要定义一个这样的实体,它的定义为:
struct file_system_type {
const char *name; // 文件系统名称
int fs_flags; // 标志
int (*init_fs_context)(struct fs_context *); // 文件系统上下文
const struct fs_parameter_spec *parameters;
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *); // 挂载
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next; // 指向下一个
......
};
注销
注销这个文件系统也是相当于直接从文件系统全局列表中进行移除即可。它的函数实现如下:
int unregister_filesystem(struct file_system_type * fs)
{
struct file_system_type ** tmp;
write_lock(&file_systems_lock);
tmp = &file_systems;
while (*tmp) {
if (fs == *tmp) {
*tmp = fs->next;
fs->next = NULL;
write_unlock(&file_systems_lock);
synchronize_rcu(); // 阻塞更新
return 0;
}
tmp = &(*tmp)->next;
}
write_unlock(&file_systems_lock);
return -EINVAL;
}
3 总结
本文从比较简单的角度学习了Linux内核中虚拟文件系统的源码以及其核心数据结构,如果要继续剖析该模块的内容,其实还可以更深入,如发生系统调用(如read、write等)过程中VFS在此过程中如何处理的。 但理解这些深入的内容,还是回归基础,搞清楚这个基本的数据结构的定义以及它们背后隐含的关系,才能更好地去分析。
后续如果来得及的话,会继续分析这部分的内容

















 5809
5809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









