







Spark33个算子梳理-Scala版
什么是算子?
spark 中对RDD进行操作的一些方法,这些方法作用于RDD的每一个partition。
算子如何划分
从大的方向来说,spark算子可以分两类:
1)Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
2)Action算子:Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
从小的方向分,可以分为三类:
1)Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
2)Key-Value数据类型的Transfromation算子,这种变换并不触发提交作业,针对处理的数据项是Key-Value型的数据对。
3)Action算子,这类算子会触发SparkContext提交Job作业。
总结:Transformation算子是惰性执行,只有遇到Action算子才可以触发Transformation操作
一、value数据类型的Transformation算子
(1)输入分区与输出分区一对一型
1. map算子
2. flatmap算子
3. mapPartitions算子
4. glom算子
(2)输入分区与输出分区多对一型
5. union算子
6. cartesian算子
(3)输入分区与输出分区多对一型
7. groupBy算子
(4)输出分区为输入分区子集
8. filter算子
9. distinct算子
10. subtract算子
11. sample算子
12. takeSample算子
(5)Cache型
13. cache算子
14. persist算子
二、Key-Value数据类型Transformation算子
(1)输入分区与输出分区一对一
15. mapValues算子
(2)对单个或两个RDD聚合
16. combineByKey算子
17. reduceByKey算子
18.partitionBy算子
(3)多个RDD聚合
19. Cogroup算子
(4)连接
20. join算子
21. leftOutJoin和rightOutJoin算子
三、Action算子
(1)无输出
22. foreach算子
(2)HDFS
23. saveAsTextFile算子
24. saveAsObjectFile算子
(3)Scala集合和数据类型
25. collect算子
26. collectAsMap算子
27. reduceByKeyLocally算子
28. lookup算子
29. count算子
30. top算子
31. reduce算子
32. fold算子
33. aggregate算子
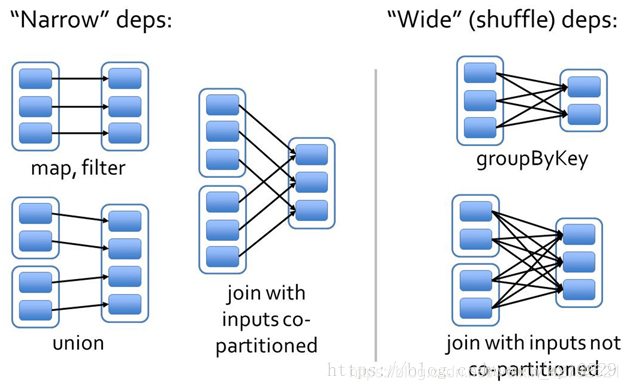
算子的依赖划分
- 窄依赖:一个父RDD的partition最多被子RDD的一个partition使用一次。
- 宽依赖:一个父RDD的partition可能被子RDD的partition使用多次。
总结:如出现Shuffle,父子RDD之间便为宽依赖
算子实操
Transformation
一、flatmap
接收一个匿名函数,进行数组爆炸【对RDD中元素进行扁平化处理】
val textRDDFlatMap = textFile.flatMap(key => key.split("\n"))

二、filter
对每个元素做过滤,接收一个匿名函数,匿名函数的返回True就保留该元素,否侧转化成新的RDD就不会包含该元素。
val textRDDFilter = textRDDFlatMap.filter(_.length > 2)

三、map
将原来 RDD 的每个数据项通过 map 中的用户自定义函数 f 映射转变为一个新的元素。
val textRDDMap = textRDDFilter.map(key => (key.trim, 1))

四、reduceByKey
按key进行***聚合***, value 由匿名函数进行处理 k,v表示 第k个元素,v表示k下一个元素
val wordcount = textRDDMap.reduceByKey((k, v) => k + v)

五、groupByKey
按key进行***分组***, 将相同的所有的键值对分组到一个集合序列当中,其顺序是不确定的
val wordCountGroupBy = textRDDMap.groupByKey()

六、mapPartitions
运行于RDD的每个分区上 (function)必须是Iterator => Iterator类型的方法(入参)
val result = textRDDFilter.mapPartitions(doubleFunc)

七、mapPartitionsWithIndex
与mapPartitions类似,但需要提供一个表示分区索引值的整型值作为参数,因此function必须是(int, Iterator)=>Iterator类型的。
val resultIndex = textRDDFilter.mapPartitionsWithIndex(doubleFuncIndex)

八、sample
采样操作,用于从样本中取出部分数据。withReplacement是否放回,fraction采样比例,seed用于指定的随机数生成器的种子。(是否放回抽样分true和false,fraction取样比例为(0, 1]。seed种子为整型实数。)
val sampleRdd = textRDDMap.sample(false, 0.5, 1)

九、union
对于源数据集和其他数据集求并集,不去重。
val resletUnion = textRDDFilter.union(textRDDFilter)

十、intersection
对于源数据集和其他数据集求交集,并去重,且无序返回。
val intersectionRDD = textRDDFilter.intersection(textRDDFilter)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IvPSIsT8-1583041782285)(/Users/cccccoldkl/Library/Application Support/typora-user-images/image-20200223185447403 .png)]
.png)]
十一、join
加入一个RDD,在一个(k,v)和(k,w)类型的dataSet上调用,返回一个(k,(v,w))的pair dataSet。
val RDDJoin = textRDDMap.join(textRDDMap,1)

十二、distinct
返回一个在源数据集去重之后的新数据集,即去重,并局部无序而整体有序返回。
val disRDD = textRDDMap.distinct()

十三、aggregateByKey
类似reduceByKey,对pairRDD中想用的key值进行聚合操作,使用初始值(seqOp中使用,而combOpenCL中未使用)对应返回值为pairRDD,而区于aggregate(返回值为非RDD)
十四、sortByKey
基于pairRDD的,根据key值来进行排序。ascending升序,默认为true,即升序;numTasks
val aggreRdd = textRDDMap.sortByKey()

十五、cogroup
合并两个RDD,生成一个新的RDD。实例中包含两个Iterable值,第一个表示RDD1中相同值,第二个表示RDD2中相同值(key值),这个操作需要通过partitioner进行重新分区,因此需要执行一次shuffle操作。(若两个RDD在此之前进行过shuffle,则不需要)
val cogroupRDD = textRDDMap.cogroup(textRDDMap)

十六、cartesian
求笛卡尔乘积。该操作不会执行shuffle操作。
val caseRDD = textRDDMap.cartesian(textRDDMap)

十七、 pipe
管道方法,通过一个shell命令来对RDD各分区进行“管道化”。通过pipe变换将一些shell命令用于Spark中生成的新RDD
val pipeRDD = textRDDMap.pipe("head -n 1")

十八、 coalesce
重新分区,减少RDD中分区的数量到numPartitions。
val partitionRDD = textRDDMap.coalesce(1)
十九、 repartition
repartition是coalesce接口中shuffle为true的简易实现,即Reshuffle RDD并随机分区,使各分区数据量尽可能平衡。若分区之后分区数远大于原分区数,则需要shuffle。
val relationRDD = textRDDMap.repartition(5)

二十、 repartitionAndSortWithinPartitions
该方法根据partitioner对RDD进行分区,并且在每个结果分区中按key进行排序。
使用场景:
- 如果需要重分区,并且想要对分区中的数据进行升序排序
- 提高性能,替换repartition和sortBy
rdd1.zipWithIndex().repartitionAndSortWithinPartitions(new HashPartitioner(1)).foreach(print)

Action
二十一、 reduce
reduce将RDD中元素两两传递给输入函数,同时产生一个新值,新值与RDD中下一个元素再被传递给输入函数,直到最后只有一个值为止。
val sumrdd1 = rdd1.reduce(_+_)

二十二、collect
将不同节点数据拉至Driver,如果数据量过大可能会导致Driver节点OOM
将一个RDD以一个Array数组形式返回其中的所有元素。
println(rdd1.collect().mkString)

二十三、count
返回数据集中元素个数,默认Long类型。
rdd1.count()
二十四、first
返回数据集首个元素
rdd1.first()
二十五、takeSample
对于一个数据集进行随机抽样,返回一个包含num个随机抽样元素的数组,withReplacement表示是否有放回抽样,参数seed指定生成随机数的种子。
rdd1.takeSample(true, 5, 1)

二十六、take
返回包含前N个元素的数组
rdd1.take(1)
二十七、takeOrdered
返回RDD中前n个元素,并按默认顺序排序(升序)或者按自定义比较器顺序排序。
rdd1.takeOrdered(3)
二十八、saveAsTextFile
将dataSet中元素以文本文件的形式写入本地文件系统或者HDFS等。Spark将对每个元素调用toString方法,将数据元素转换为文本文件中的一行记录。
若将文件保存到本地文件系统,那么只会保存在executor所在机器的本地目录。
rdd1.saveAsTextFile("./test.txt")
保持文件类似于HDFS
二十九、saveAsSequenceFile
将dataSet中元素以Hadoop SequenceFile的形式写入本地文件系统或者HDFS等。(对pairRDD操作)
rdd1.saveAsSequenceFile("./test.txt")
三十、saveAsObjectFile
将数据集中元素以ObjectFile形式写入本地文件系统或者HDFS等。
rdd1.saveAsObjectFile("./test.txt")
三十一、countByKey
用于统计RDD[K,V]中每个K的数量,返回具有每个key的计数的(k,int)pairs的hashMap。
rdd1.countByValue().foreach(println)

三十二、foreach
对数据集中每一个元素运行函数function
对数据集进行便利,有点类似map,区别在于foreach返回值为undefined,map返回为数组
rdd1.countByValue().foreach(println)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









