









Spark
一、Spark介绍
Spark 是用于大规模数据处理的统一分析引擎。
Spark是一种与Hadoop相似的开源集群计算环境,Spark使用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了内存内运算技术,能在数据尚未写入硬盘时即在内存内分析运算。Spark在内存内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。Spark允许用户将数据加载至集群内存,并多次对其进行查询,非常适合用于机器学习算法。
二、Spark生态圈
Spark生态圈以HDFS、S3、Techyon为底层存储引擎,以Yarn、Mesos和Standlone作为资源调度引擎;
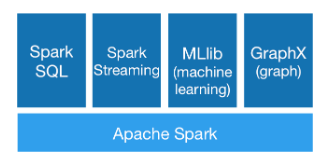
Spark:可以实现MapReduce应用。
Spark SQL:可以实现即席查询。
Spark Streaming:可以处理实时应用。
Spark MLib:可以实现机器学习算法。
Spark GraphX:可以实现图计算。
Spark R:可以实现复杂数学计算。三、Spark运行架构

1.Spark架构采用了分布式计算中的Master-Slave模型。
2.Master是对应集群中的含有Master进程的节点,
3.Slave是集群中含有Worker进程的节点。
4.Master作为整个集群的控制器,负责整个集群的正常运行;
5.Worker相当于是计算节点,接收主节点命令与进行状态汇报;
6.Executor负责任务的执行;
7.Client作为用户的客户端负责提交应用,Driver负责控制一个应用的执行。将Spark项目部署到Spark集群后,需要在主节点启动Master进程和从节点启动Worker进程,以此对整个集群进行控制。
在Spark应用的执行过程中,Driver和Worker是两个重要角色。
Driver程序是应用执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。
在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。四、Spark架构的基本组件
1.ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器。
2.Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
3.Driver:运行Application的main()函数并创建SparkContext。
4.Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
5.SparkContext:整个应用的上下文,控制应用的生命周期。
6.RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
7.DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
8.TaskScheduler:将任务(Task)分发给Executor执行。
9.SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。SparkEnv内创建并包含如下一些重要组件的引用。
10.MapOutPutTracker:负责Shuffle元信息的存储。
11.BroadcastManager:负责广播变量的控制与元信息的存储。
12.BlockManager:负责存储管理、创建和查找块。
13.MetricsSystem:监控运行时性能指标信息。
14.SparkConf:负责存储配置信息。五、Spark执行的整体流程
1.Client提交应用,Master找到一个Worker启动Driver,
2.Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph,
3.再由DAGScheduler将RDD Graph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。
4.在任务执行的过程中,其他组件协同工作,确保整个应用顺利执行。六、Spark的基本RDD
Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。
RDD代表一个不可变、只读的,被分区的数据集。操作 RDD 就像操作本地集合一样,有很多的方法可以调用,使用方便,而无需关心底层的调度细节。
RDD是懒散,短暂的。(RDD的固化:cache缓存至内存; save保存到分布式文件系统)。RDD 的操作是惰性的,当 RDD 执行转化操作的时候,实际计算并没有被执行,只有当 RDD 执行行动操作时才会促发计算任务提交,从而执行相应的计算操作。
1.获取RDD
a.从HDFS获取。
b.通过已存在的RDD转换。
c.将已存在scala集合(只要是Seq对象)并行化,通过调用SparkContext的parallelize方法实现。
d.改变现有RDD的持久性。2.RDD分为两大类
a.Actions:对数据集计算后返回一个数据value给驱动程序
b.Transformation:根据数据集创建一个新的数据集,计算后返回一个新RDD3.RDD的依赖(宽依赖和窄依赖)
窄依赖:指父Rdd的分区最多只能被一个子Rdd的分区所引用,即一个父Rdd的分区对应一个子Rdd的分区,或者多个父Rdd的分区对应一个子Rdd的分区。
宽依赖:指子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。1个父RDD分区对应多个子RDD分区,这其中又分两种情况:1个父RDD对应所有子RDD分区(未经协同划分的Join)或者1个父RDD对应非全部的多个RDD分区(如groupByKey)。该图:map就是一种窄依赖,而join则会导致宽依赖

a.Actions操作算子
reduce(func):通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行。
collect():在Driver的程序中,以数组的形式,返回数据集的所有元素。将计算的RDD结果回收到Driver端,转为List集合。适用于小量数据。
count():返回数据集的元素个数。
countByKey(): 作用到K,V格式的RDD,根据Key计数相同Key的数据集元素,返回一个Map<Integer, Object>。
countByValue():根据数据集每个元素相同的内容来计数,返回相同内容元素对应的条数。
take(n):返回一个数组,由数据集的前n个元素组成。该操作并非在多个节点上并行执行,而是Driver程序所在机器,单机计算所有的元素(Gateway的内存压力会增大,需要谨慎使用)。
first():返回数据集的第一个元素(类似于take(1))。
saveAsTextFile(path):将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者任何其它hadoop支持的文件系统。Spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本。
saveAsSequenceFile(path):将数据集的元素,以sequencefile的格式,保存到指定的目录下,本地系统,hdfs或者任何其它hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable(Spark包括了基本类型的转换,例如Int,Double,String等等)。
foreach(func):在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互
foreachPartition(func):在数据集时指定分区,运行函数func。b.Transformation转换算子
map(func):返回一个新的分布式数据集,由每个原元素经过func函数转换后组成。
flatMap(func):类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)。
reduceByKey(func, [numTasks]):在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。
mapPartitions():对rdd中的每个分区的迭代器进行操作,返回一个可迭代的对象。SparkSql或DataFrame默认会对程序进行mapPartition的优化。
mapPartitionsWithIndex():mapPartitionsWithIndex与mapPartitions的相似,只是增加了分区的索引,对每个分区的迭代器进行计算,并得到当前分区的索引,返回一个迭代器。
filter(func):返回一个新的数据集,由经过func函数后返回值为true的原元素组成,过滤符合条件的数据。
join(otherDataset, [numTasks]):在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集。
cogroup():在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。此操作也被称做groupWith。
aggregate():将每个分区里面的元素进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。
aggregateByKey():对PairRDD中相同的Key值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似,aggregateByKey返回值的类型不需要和RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,.所以aggregateByKey函数最终返回的类型还是PairRDD,对应的结果是Key和聚合后的值,而aggregate函数直接返回的是非RDD的结果。
coalesce():返回指定一个新的指定分区的RDD。
combineByKey():combineByKey是针对不同partition进行操作的。第一个参数用于数据初始化,第二个参数是同个partition内combine操作函数,第三个参数是在所有partition都combine完后,对所有临时结果进行combine操作的函数。
distinct():对原RDD进行去重做操作,返回不重复的成员。
groupByKey([numTasks]):在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task。
sample(withReplacement, frac, seed):根据给定的随机种子seed,随机抽样出数量为frac的数据。
union(otherDataset):返回一个新的数据集,由原数据集和参数联合而成。
intersection():取两个RDD之间的交集。
subtract():取一个RDD与另一个RDD的差集。
mapValues():是对<K,V>的V值进行map操作。
parallelize():将集合转为RDD。
rePartition():重分区,来进行数据紧缩,减少分区数量,将小分区合并为大分区,从而提高效率。
repartitionAndSortWithinPartitions():如果需要在repartition重分区之后,还要进行排序则推荐使用该算子,效率比使用repartition加sortBykey高,排序是在shuffle过程中进行,一边shuffle,一边排序。
sortByKey():对Key做排序,参数为fasle时降序,为true时升序。
zip():将两个非KV格式的RDD,通过一一对应的关系压缩成KV格式的RDD,需要分区数和分区中的元素个数相等
ZipWithIndex():将RDD中的元素和这个元素在RDD中的索引好(从0开始),组合成K,V对。
checkpoint():是为了最大程度保证绝对可靠的复用 RDD 计算数据的 Spark 的高级功能,通过 Checkpoint 我们通过把数据持久化到 HDFS 上来保证数据的最大程度的安全性。c.单词计数(WordCount)
package com.kevin.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 单词计数
*/
object WordCount {
def main(args: Array[String]): Unit = {
val file = "DTSparkCore\\src\\main\\resources\\test.txt"
// 1.创建SparkConf,设置作业名称,设置模式为单机模式
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
// 2.基于SparkConf对象创建一个SparkContext上下文,它是通往集群的唯一通道,且在创建时会创建任务调度器
val sc = new SparkContext(conf)
// 3.textFile读取文件,flatMap将文件以空格形式切分,map将所有的单词次数初始值为1,reduceByKey将相同的单词的次数相加,collect转为集合,foreach遍历输出
sc.textFile(file).flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect().foreach(println(_))
// 4.关闭SparkContext
sc.stop()
}
}
七、actions和transformations算子案例
collect():在Driver的程序中,以数组的形式,返回数据集的所有元素。将计算的RDD结果回收到Driver端,转为List集合。适用于小量数据。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* Collect将计算的RDD结果回收到Driver端,转为List集合。适用于小量数据
*/
object Collect_RDD {
def main(args: Array[String]): Unit = {
val file = "DTSparkCore\\src\\main\\resources\\test.txt"
// 1.创建SparkConf
val conf = new SparkConf().setAppName("Collect_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.textFile获取文件数据,filter过滤掉kill,collect转成集合,foreach遍历,println打印
sc.textFile(file).filter(!_.contains("kill")).collect().foreach(println(_))
// 4.关闭sc
sc.stop()
}
}
Java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.List;
/**
* @author kevin
* @version 1.0
* @description Collect将计算的RDD结果回收到Driver端,转为List集合。适用于小量数据
* @createDate 2018/12/27
*/
public class Collect_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("Collect_RDD").setMaster("local");
// 2.基于Sparkconf对象创建一个SparkContext上下文,它是通往集群的唯一通道,且在创建时会创建任务调度器
JavaSparkContext sc = new JavaSparkContext(conf);
String file = "DTSparkCore\\src\\main\\resources\\test.txt";
// 3.获取文件数据
JavaRDD<String> linesRDD = sc.textFile(file);
// 4.使用filter函数过滤kill
JavaRDD<String> resultRDD = linesRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String s) throws Exception {
return !s.contains("kill");
}
});
// 5.将rdd转为集合
List<String> collect = resultRDD.collect();
// 6.遍历输出
for (String s : collect) {
System.out.println(s);
}
// 7.关闭JavaSparkContext
sc.close();
}
}
count():返回数据集的元素个数。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* 返回结果集中的行数
*/
object Count_RDD {
def main(args: Array[String]):Unit = {
val file = "DTSparkCore\\src\\main\\resources\\test.txt"
// 1.创建SparkConf
val conf = new SparkConf().setAppName("Count_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.统计数据记录数
val count = sc.textFile(file).count()
// 4.打印
println(count)
// 5.关闭sc
sc.stop()
}
}
Java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* @author kevin
* @version 1.0
* @description 返回结果集中的行数
* @createDate 2018/12/27
*/
public class Count_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("Count_RDD").setMaster("local");
// 2.JavaSparkContext是Spark的唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
String file = "DTSparkCore\\src\\main\\resources\\test.txt";
// 4.获取文件数据
JavaRDD<String> liens = sc.textFile(file);
// 5.统计其行数
long count = liens.count();
System.out.println(count);
// 6.关闭JavaSparkContext
sc.close();
}
}
countByKey(): 作用到K,V格式的RDD,根据Key计数相同Key的数据集元素,返回一个Map<Integer, Object>。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* 作用到K,V格式的RDD,根据Key计数相同Key的数据集元素,返回一个Map<Integer, Object>
*/
object CountByKey_RDD {
def main(args:Array[String]):Unit={
// 创建一个Tuple2元组集合
val list = List((1, "a"),(2, "b"),(3, "c"),(4, "d"),(4, "e"))
// 1.创建SparkConf
val conf = new SparkConf().setAppName("CountByKey_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.parallelize将集合转成rdd,countByKey统计相同的key的value次数返回key,foreach遍历,println打印
sc.parallelize(list).countByKey().foreach(println(_))
// 4.关闭sc
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Map;
/**
* @author kevin
* @version 1.0
* @description 作用到K,V格式的RDD,根据Key计数相同Key的数据集元素,返回一个Map<Integer, Object>
* @createDate 2018/12/27
*/
public class CountByKey_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("CountByKey_RDD").setMaster("local");
// 2.基于SparkConf创建JavaSparkContext,JavaSparkContext是Spark唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.将list转为RDD
JavaPairRDD<Integer, String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
new Tuple2<Integer,String>(1,"a"),
new Tuple2<Integer,String>(2,"b"),
new Tuple2<Integer,String>(3,"c"),
new Tuple2<Integer,String>(4,"d"),
new Tuple2<Integer,String>(4,"e")
));
// 4.统计相同Key的Value次数,返回key
Map<Integer, Object> countByKey = parallelizePairs.countByKey();
for(Map.Entry<Integer,Object> entry : countByKey.entrySet()){
System.out.println("key:"+entry.getKey()+"value:"+entry.getValue());
}
// 5.关闭
sc.close();
}
}
countByValue():根据数据集每个元素相同的内容来计数,返回相同内容元素对应的条数。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
*
* 根据数据集每个元素相同的内容来计数,返回相同内容元素对应的条数
*/
object CountByValue_RDD {
def main(args: Array[String]): Unit = {
// 创建一个Tuple2元组集合
val list = List((1, "a"),(2, "b"),(3, "c"),(4, "d"),(4, "e"))
// 1.创建SparkConf
val conf = new SparkConf().setAppName("CountByValue_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.parallelize将集合转成rdd,countByKey统计相同的key的value次数返回(key,value),foreach遍历,println打印
sc.parallelize(list).countByValue().foreach(println(_))
// 4.关闭sc
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author kevin
* @version 1.0
* @description 根据数据集每个元素相同的内容来计数,返回相同内容元素对应的条数
* @createDate 2018/12/27
*/
public class CountByValue_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("CountByValue_RDD").setMaster("local");
// 2.基于Sparkconf对象创建一个SparkContext上下文,它是通往集群的唯一通道,且在创建时会创建任务调度器
JavaSparkContext sc = new JavaSparkContext(conf);
List<Tuple2<Integer,String>> list = new ArrayList();
list.add(new Tuple2<Integer,String>(1,"a"));
list.add(new Tuple2<Integer,String>(2,"b"));
list.add(new Tuple2<Integer,String>(2,"c"));
list.add(new Tuple2<Integer,String>(3,"c"));
list.add(new Tuple2<Integer,String>(4,"d"));
list.add(new Tuple2<Integer,String>(4,"d"));
// 3.将list数据转为RDD
JavaPairRDD<Integer, String> parallelizePairs = sc.parallelizePairs(list);
// 4.统计相同key的value次数,返回(key,value)
Map<Tuple2<Integer, String>, Long> countByValue = parallelizePairs.countByValue();
// 5.遍历统计好的结果集
for (Map.Entry<Tuple2<Integer,String>, Long> entry : countByValue.entrySet()) {
System.out.println(entry.getKey()+" : "+entry.getValue());
}
// 6.关闭
sc.close();
}
}
first():返回数据集的第一个元素(类似于take(1))。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* first是获取第一个数据
*/
object First_RDD {
def main(args: Array[String]): Unit = {
// 创建集合
val list = List("a", "b", "c", "d", "e")
// 1.创建SparkConf
val conf = new SparkConf().setAppName("First_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.parallelize将集合转成rdd,first取第一个数据
val first = sc.parallelize(list).first()
// 4.关闭sc
println(first)
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
/**
* @author kevin
* @version 1.0
* @description first是获取第一个数据
* @createDate 2018/12/27
*/
public class First_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("First_RDD").setMaster("local");
// 2.基于SparkConf创建JavaSparkContext,JavaSparkContext是Spark唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.将list转为RDD
JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("a", "b", "c", "d", "e"));
// 4.获取rdd的第一个数据
String first = parallelize.first();
System.out.println("first: " + first);
// 5.关闭
sc.close();
}
}
foreach(func):在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* 使用spark的foreach函数进行遍历数据
*/
object Foreach_RDD {
def main(args: Array[String]): Unit = {
// 创建集合
val list = List("a", "b", "c", "d", "e")
// 1.创建SparkConf
val conf = new SparkConf().setAppName("Foreach_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.parallelize将集合转成rdd,foreach遍历,println打印
sc.parallelize(list).foreach(println(_))
// 4.关闭sc
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
/**
* @author kevin
* @version 1.0
* @description 使用spark的foreach函数进行遍历数据
* @createDate 2018/12/27
*/
public class Foreach_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("Foreach_RDD").setMaster("local");
// 2.基于SparkConf创建JavaSparkContext,JavaSparkContext是Spark唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.将List集合转为RDD
JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3,4,5));
// 4.使用Spark函数的foreach遍历rdd数据集
parallelize.foreach(new VoidFunction<Integer>(){
@Override
public void call(Integer s) throws Exception {
System.out.println(s);
}
});
// 5.关闭SparkContext
sc.close();
}
}
foreachPartition(func):在数据集时指定分区,运行函数func。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* 在获取文件数据的时候指定最小分区,并且在遍历的时候使用foreachPartition进行分区输出
*/
object ForeachPartition_RDD {
def main(args: Array[String]): Unit = {
val file = "DTSparkCore\\src\\main\\resources\\test.txt"
// 1.创建SparkConf
val conf = new SparkConf().setAppName("ForeachPartition_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.textFile读取文件数据并设置最小分区为3,foreachPartition分区为3个分区遍历,如果直接使用foreach则默认只使用一个分区
sc.textFile(file,3).foreachPartition(_.foreach(println(_)))
// 4.关闭sc
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Iterator;
/**
* @author kevin
* @version 1.0
* @description 在获取文件数据的时候指定最小分区,并且在遍历的时候使用foreachPartition进行分区输出
* @createDate 2018/12/27
*/
public class ForeachPartition_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("ForeachPartition_RDD").setMaster("local");
// 2.基于Sparkconf对象创建一个SparkContext上下文,它是通往集群的唯一通道,且在创建时会创建任务调度器
JavaSparkContext sc = new JavaSparkContext(conf);
String file = "DTSparkCore\\src\\main\\resources\\test.txt";
// 3.设置最小分区
JavaRDD<String> lines = sc.textFile(file,3);
// 4.分区遍历,分为三区,如果使用foreach则达不到分区效果。
// 如果读取数据的时候不指定最小分区,默认只有一个分区
lines.foreachPartition(new VoidFunction<Iterator<String>>() {
@Override
public void call(Iterator<String> t) throws Exception {
System.out.println("分区");
while (t.hasNext()) {
System.out.println(t.next());
}
}
});
// 5.关闭
sc.close();
}
}
reduce(func):通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* 根据聚合逻辑聚合数据集中的每个元素
*/
object Reduce_RDD {
def main(args: Array[String]): Unit = {
// 创建集合
val list = List(1,2,3,4,5,6)
// 1.创建SparkConf
val conf = new SparkConf().setAppName("Reduce_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.parallelize将集合转成rdd,reduce将值进行累加
val reduce = sc.parallelize(list).reduce(_+_)
// 4.打印
println(reduce)
// 5.关闭sc
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import java.util.Arrays;
/**
* @author kevin
* @version 1.0
* @description 根据聚合逻辑聚合数据集中的每个元素
* @createDate 2018/12/27
*/
public class Reduce_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("Reduce_RDD").setMaster("local");
// 2.基于SparkConf创建JavaSparkContext,JavaSparkContext是Spark的唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
// 3.将list集合转为RDD
JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
// 4.使用reduce将其值累加
Integer reduce = parallelize.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println(reduce);
// 5.关闭JavaSparkContext
sc.close();
}
}
take(n):返回一个数组,由数据集的前n个元素组成。该操作并非在多个节点上并行执行,而是Driver程序所在机器,单机计算所有的元素(Gateway的内存压力会增大,需要谨慎使用)。
scala版
package com.kevin.scala.actions
import org.apache.spark.{SparkConf, SparkContext}
/**
* take是获取指定的数据
*/
object Take_RDD {
def main(args: Array[String]): Unit = {
val file = "DTSparkCore\\src\\main\\resources\\test.txt"
// 1.创建SparkConf
val conf = new SparkConf().setAppName("Take_RDD").setMaster("local")
// 2.创建SparkContext
val sc = new SparkContext(conf)
// 3.textFile读取文件数据,take获取前两行数据,foreach遍历,println打印
sc.textFile(file).take(2).foreach(println(_))
// 4.关闭sc
sc.stop()
}
}
java版
package com.kevin.java.actions;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.List;
/**
* @author kevin
* @version 1.0
* @description take是获取指定的数据
* @createDate 2019/1/2
*/
public class Take_RDD {
public static void main(String[] args) {
// 1.创建SparkConf,设置作业名称和模式
SparkConf conf = new SparkConf().setAppName("Take_RDD").setMaster("local");
// 2.JavaSparkContext是Spark的唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
String file = "DTSparkCore\\src\\main\\resources\\test.txt";
// 4.获取文件数据
JavaRDD<String> liens = sc.textFile(file);
// 5.获取rdd中指定的前几个数据,如获取rdd中前两个数据
List<String> take = liens.take(2);
// 6.遍历数据
for (String s:take) {
System.out.println(s);
}
// 7.关闭JavaSparkContext
sc.close();
}
}
其它的rdd算子我就不贴上来了,需要的看我的github
github地址: https://github.com/kevin961212/DTSpark/tree/master/DTSparkCore















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









