









Spark作业提交流程源码
目录

一、环境准备及提交流程
1)spark-3.0.0-bin-hadoop3.2\bin\spark-submit.cmd
=> cmd /V /E /C “”%~dp0spark-submit2.cmd" %*"
2)spark-submit2.cmd
=> set CLASS=org.apache.spark.deploy.SparkSubmit
“%~dp0spark-class2.cmd” %CLASS% %*
3)spark-class2.cmd
=> %SPARK_CMD%
4)在spark-class2.cmd文件中增加打印%SPARK_CMD%语句
echo %SPARK_CMD%
%SPARK_CMD%
5)在spark-3.0.0-bin-hadoop3.2\bin目录上执行cmd命令
6)进入命令行窗口,输入
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/
spark-examples_2.12-3.0.0.jar 10
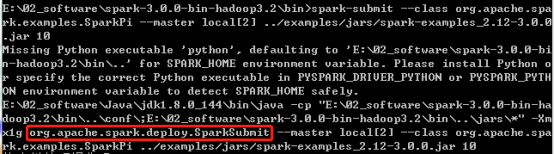
7)发现底层执行的命令为
java -cp org.apache.spark.deploy.SparkSubmit
说明:java -cp和 -classpath一样,是指定类运行所依赖其他类的路径。
8)执行java -cp 就会开启JVM虚拟机,在虚拟机上开启SparkSubmit进程,然后开始执行main方法
java -cp =》开启JVM虚拟机 =》开启Process(SparkSubmit)=》程序入口SparkSubmit.main
9)在IDEA中全局查找(ctrl + n):org.apache.spark.deploy.SparkSubmit,找到SparkSubmit的伴生对象,并找到main方法
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
... ...
}
}
二、创建Yarn Client客户端并提交
2.1 程序入口
SparkSubmit.scala
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
... ...
override def doSubmit(args: Array[String]): Unit = {
super.doSubmit(args)
}
}
submit.doSubmit(args)
}
def doSubmit(args: Array[String]): Unit = {
val uninitLog = initializeLogIfNecessary(true, silent = true)
// 解析参数
val appArgs = parseArguments(args)
… …
appArgs.action match {
// 提交作业
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
2.2 解析输入参数
protected def parseArguments(args: Array[String]): SparkSubmitArguments = {
new SparkSubmitArguments(args)
}
SparkSubmitArguments.scala
private[deploy] class SparkSubmitArguments(args: Seq[String], env: Map[String, String] = sys.env)
extends SparkSubmitArgumentsParser with Logging {
... ...
parse(args.asJava)
... ...
}
SparkSubmitOptionParser.java
protected final void parse(List<String> args) {
Pattern eqSeparatedOpt = Pattern.compile("(--[^=]+)=(.+)");
int idx = 0;
for (idx = 0; idx < args.size(); idx++) {
String arg = args.get(idx);
String value = null;
Matcher m = eqSeparatedOpt.matcher(arg);
if (m.matches()) {
arg = m.group(1);
value = m.group(2);
}
String name = findCliOption(arg, opts);
if (name != null) {
if (value == null) {
… …
}
// handle的实现类(ctrl + h)是SparkSubmitArguments.scala中
if (!handle(name, value)) {
break;
}
continue;
}
… …
}
handleExtraArgs(args.subList(idx, args.size()));
}
SparkSubmitArguments.scala
override protected def handle(opt: String, value: String): Boolean = {
opt match {
case NAME =>
name = value
// protected final String MASTER = "--master"; SparkSubmitOptionParser.java
case MASTER =>
master = value
case CLASS =>
mainClass = value
... ...
case _ =>
error(s"Unexpected argument '$opt'.")
}
action != SparkSubmitAction.PRINT_VERSION
}
private[deploy] class SparkSubmitArguments(args: Seq[String], env: Map[String, String] = sys.env)
extends SparkSubmitArgumentsParser with Logging {
... ...
var action: SparkSubmitAction = null
... ...
private def loadEnvironmentArguments(): Unit = {
... ...
// Action should be SUBMIT unless otherwise specified
// action默认赋值submit
action = Option(action).getOrElse(SUBMIT)
}
... ...
}
2.3 选择创建哪种类型的客户端
SparkSubmit.scala
private[spark] class SparkSubmit extends Logging {
... ...
def doSubmit(args: Array[String]): Unit = {
val uninitLog = initializeLogIfNecessary(true, silent = true)
// 解析参数
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
appArgs.action match {
// 提交作业
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
def doRunMain(): Unit = {
if (args.proxyUser != null) {
… …
} else {
runMain(args, uninitLog)
}
}
if (args.isStandaloneCluster && args.useRest) {
… …
} else {
doRunMain()
}
}
private def runMain(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
// 选择创建什么应用:YarnClusterApplication
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
... ...
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
... ...
}
// 反射创建应用:YarnClusterApplication
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
... ...
try {
//启动应用
app.start(childArgs.toArray, sparkConf)
} catch {
case t: Throwable =>
throw findCause(t)
}
}
... ...
}
SparkSubmit.scala
private[deploy] def prepareSubmitEnvironment(
args: SparkSubmitArguments,
conf: Option[HadoopConfiguration] = None)
: (Seq[String], Seq[String], SparkConf, String) = {
var childMainClass = ""
... ...
// yarn集群模式
if (isYarnCluster) {
// YARN_CLUSTER_SUBMIT_CLASS="org.apache.spark.deploy.yarn.YarnClusterApplication"
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
... ...
}
... ...
(childArgs, childClasspath, sparkConf, childMainClass)
}
2.4 Yarn客户端参数解析
1)在pom.xml文件中添加依赖spark-yarn
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
2)在IDEA中全文查找(ctrl+n)org.apache.spark.deploy.yarn.YarnClusterApplication
3)Yarn客户端参数解析
Client.scala
private[spark] class YarnClusterApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
... ...
new Client(new ClientArguments(args), conf, null).run()
}
}
ClientArguments.scala
private[spark] class ClientArguments(args: Array[String]) {
... ...
parseArgs(args.toList)
private def parseArgs(inputArgs: List[String]): Unit = {
var args = inputArgs
while (!args.isEmpty) {
args match {
case ("--jar") :: value :: tail =>
userJar = value
args = tail
case ("--class") :: value :: tail =>
userClass = value
args = tail
... ...
case _ =>
throw new IllegalArgumentException(getUsageMessage(args))
}
}
}
... ...
}
2.5 创建Yarn客户端
Client.scala
private[spark] class Client(
val args: ClientArguments,
val sparkConf: SparkConf,
val rpcEnv: RpcEnv)
extends Logging {
// 创建yarnClient
private val yarnClient = YarnClient.createYarnClient
... ...
}
YarnClient.java
public abstract class YarnClient extends AbstractService {
@Public
public static YarnClient createYarnClient() {
YarnClient client = new YarnClientImpl();
return client;
}
... ...
}
YarnClientImpl.java
public class YarnClientImpl extends YarnClient {
// yarnClient主要用来和RM通信
protected ApplicationClientProtocol rmClient;
... ...
public YarnClientImpl() {
super(YarnClientImpl.class.getName());
}
... ...
}
2.6 Yarn客户端创建并启动ApplicationMaster
Client.scala
private[spark] class YarnClusterApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
// SparkSubmit would use yarn cache to distribute files & jars in yarn mode,
// so remove them from sparkConf here for yarn mode.
conf.remove(JARS)
conf.remove(FILES)
new Client(new ClientArguments(args), conf, null).run()
}
}
private[spark] class Client(
val args: ClientArguments,
val sparkConf: SparkConf,
val rpcEnv: RpcEnv)
extends Logging {
def run(): Unit = {
this.appId = submitApplication()
... ...
}
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
launcherBackend.connect()
yarnClient.init(hadoopConf)
yarnClient.start()
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
... ...
// 封装提交参数和命令
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
yarnClient.submitApplication(appContext)
... ...
appId
} catch {
... ...
}
}
}
// 封装提交参数和命令
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse)
: ContainerLaunchContext = {
... ...
val amClass =
// 如果是集群模式启动ApplicationMaster,如果是客户端模式启动ExecutorLauncher
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
val amArgs =
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
Seq("--properties-file",
buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, SPARK_CONF_FILE)) ++
Seq("--dist-cache-conf",
buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, DIST_CACHE_CONF_FILE))
// Command for the ApplicationMaster
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
val printableCommands = commands.map(s => if (s == null) "null" else s).toList
amContainer.setCommands(printableCommands.asJava)
... ...
val securityManager = new SecurityManager(sparkConf)
amContainer.setApplicationACLs(
YarnSparkHadoopUtil.getApplicationAclsForYarn(securityManager).asJava)
setupSecurityToken(amContainer)
amContainer
}
三、ApplicationMaster任务
1)在IDEA中全局查找(ctrl + n)org.apache.spark.deploy.yarn.ApplicationMaster,点击对应的伴生对象
ApplicationMaster.scala
def main(args: Array[String]): Unit = {
// 1解析传递过来的参数
val amArgs = new ApplicationMasterArguments(args)
val sparkConf = new SparkConf()
... ...
val yarnConf = new YarnConfiguration(SparkHadoopUtil.newConfiguration(sparkConf))
// 2创建ApplicationMaster对象
master = new ApplicationMaster(amArgs, sparkConf, yarnConf)
... ...
ugi.doAs(new PrivilegedExceptionAction[Unit]() {
// 3执行ApplicationMaster
override def run(): Unit = System.exit(master.run())
})
}
3.1 解析传递过来的参数
ApplicationMasterArguments.scala
class ApplicationMasterArguments(val args: Array[String]) {
... ...
parseArgs(args.toList)
private def parseArgs(inputArgs: List[String]): Unit = {
val userArgsBuffer = new ArrayBuffer[String]()
var args = inputArgs
while (!args.isEmpty) {
args match {
case ("--jar") :: value :: tail =>
userJar = value
args = tail
case ("--class") :: value :: tail =>
userClass = value
args = tail
... ...
case _ =>
printUsageAndExit(1, args)
}
}
... ...
}
... ...
}
3.2 创建RMClient并启动Driver
ApplicationMaster.scala
private[spark] class ApplicationMaster(
args: ApplicationMasterArguments,
sparkConf: SparkConf,
yarnConf: YarnConfiguration) extends Logging {
... ...
// 1创建RMClient
private val client = new YarnRMClient()
... ...
final def run(): Int = {
... ...
if (isClusterMode) {
runDriver()
} else {
runExecutorLauncher()
}
... ...
}
private def runDriver(): Unit = {
addAmIpFilter(None, System.getenv(ApplicationConstants.APPLICATION_WEB_PROXY_BASE_ENV))
// 2根据输入参数启动Driver
userClassThread = startUserApplication()
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
// 3等待初始化完毕
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
// sparkcontext初始化完毕
if (sc != null) {
val rpcEnv = sc.env.rpcEnv
val userConf = sc.getConf
val host = userConf.get(DRIVER_HOST_ADDRESS)
val port = userConf.get(DRIVER_PORT)
// 4 向RM注册自己(AM)
registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
val driverRef = rpcEnv.setupEndpointRef(
RpcAddress(host, port),
YarnSchedulerBackend.ENDPOINT_NAME)
// 5获取RM返回的可用资源列表
createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
} else {
... ...
}
resumeDriver()
userClassThread.join()
} catch {
... ...
} finally {
resumeDriver()
}
}
ApplicationMaster.scala
private def startUserApplication(): Thread = {
... ...
// args.userClass来源于ApplicationMasterArguments.scala
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
... ...
val userThread = new Thread {
override def run(): Unit = {
... ...
if (!Modifier.isStatic(mainMethod.getModifiers)) {
logError(s"Could not find static main method in object ${args.userClass}")
finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_EXCEPTION_USER_CLASS)
} else {
mainMethod.invoke(null, userArgs.toArray)
finish(FinalApplicationStatus.SUCCEEDED, ApplicationMaster.EXIT_SUCCESS)
logDebug("Done running user class")
}
... ...
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}
3.3 向RM注册AM
private def registerAM(
host: String,
port: Int,
_sparkConf: SparkConf,
uiAddress: Option[String],
appAttempt: ApplicationAttemptId): Unit = {
… …
client.register(host, port, yarnConf, _sparkConf, uiAddress, historyAddress)
registered = true
}
3.4 获取RM返回可以资源列表
ApplicationMaster.scala
private def createAllocator(
driverRef: RpcEndpointRef,
_sparkConf: SparkConf,
rpcEnv: RpcEnv,
appAttemptId: ApplicationAttemptId,
distCacheConf: SparkConf): Unit = {
... ...
// 申请资源 获得资源
allocator = client.createAllocator(
yarnConf,
_sparkConf,
appAttemptId,
driverUrl,
driverRef,
securityMgr,
localResources)
... ...
// 处理资源结果,启动Executor
allocator.allocateResources()
... ...
}
YarnAllocator.scala
def allocateResources(): Unit = synchronized {
val progressIndicator = 0.1f
val allocateResponse = amClient.allocate(progressIndicator)
// 获取可分配资源
val allocatedContainers = allocateResponse.getAllocatedContainers()
allocatorBlacklistTracker.setNumClusterNodes(allocateResponse.getNumClusterNodes)
// 可分配的资源大于0
if (allocatedContainers.size > 0) {
......
// 分配规则
handleAllocatedContainers(allocatedContainers.asScala)
}
... ...
}
def handleAllocatedContainers(allocatedContainers: Seq[Container]): Unit = {
val containersToUse = new ArrayBuffer[Container](allocatedContainers.size)
// 分配在同一台主机上资源
val remainingAfterHostMatches = new ArrayBuffer[Container]
for (allocatedContainer <- allocatedContainers) {
... ...
}
// 分配同一个机架上资源
val remainingAfterRackMatches = new ArrayBuffer[Container]
if (remainingAfterHostMatches.nonEmpty) {
... ...
}
// 分配既不是本地节点也不是机架本地的剩余部分
val remainingAfterOffRackMatches = new ArrayBuffer[Container]
for (allocatedContainer <- remainingAfterRackMatches) {
... ...
}
// 运行已分配容器
runAllocatedContainers(containersToUse)
}
3.5 根据可用资源创建NMClient
YarnAllocator.scala
private def runAllocatedContainers(containersToUse: ArrayBuffer[Container]): Unit = {
for (container <- containersToUse) {
... ...
if (runningExecutors.size() < targetNumExecutors) {
numExecutorsStarting.incrementAndGet()
if (launchContainers) {
launcherPool.execute(() => {
try {
new ExecutorRunnable(
… …
).run()
updateInternalState()
} catch {
... ...
}
})
} else {
// For test only
updateInternalState()
}
} else {
… …
}
}
}
ExecutorRunnable.scala
private[yarn] class ExecutorRunnable(... ...) extends Logging {
var rpc: YarnRPC = YarnRPC.create(conf)
var nmClient: NMClient = _
def run(): Unit = {
logDebug("Starting Executor Container")
nmClient = NMClient.createNMClient()
nmClient.init(conf)
nmClient.start()
startContainer()
}
... ...
def startContainer(): java.util.Map[String, ByteBuffer] = {
... ...
// 准备命令,封装到ctx环境中
val commands = prepareCommand()
ctx.setCommands(commands.asJava)
... ...
// 向指定的NM启动容器对象
try {
nmClient.startContainer(container.get, ctx)
} catch {
... ...
}
}
private def prepareCommand(): List[String] = {
... ...
YarnSparkHadoopUtil.addOutOfMemoryErrorArgument(javaOpts)
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++
Seq("org.apache.spark.executor.YarnCoarseGrainedExecutorBackend",
"--driver-url", masterAddress,
"--executor-id", executorId,
"--hostname", hostname,
"--cores", executorCores.toString,
"--app-id", appId,
"--resourceProfileId", resourceProfileId.toString) ++
... ...
}
}
四、Spark组件通信
4.1 Spark中通信框架的发展

4.2 三种通信方式

4.3 Spark底层通信原理

- RpcEndpoint:RPC通信终端。Spark针对每个节点(Client/Master/Worker)都称之为一个RPC终端,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。在Spark中,所有的终端都存在生命周期:
Constructor =》onStart =》receive* =》onStop - RpcEnv:RPC上下文环境,每个RPC终端运行时依赖的上下文环境称为RpcEnv;在当前Spark版本中使用的NettyRpcEnv
- Dispatcher:消息调度(分发)器,针对于RPC终端需要发送远程消息或者从远程RPC接收到的消息,分发至对应的指令收件箱(发件箱)。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱;
- Inbox:指令消息收件箱。一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费;
- RpcEndpointRef:RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。
- OutBox:指令消息发件箱。对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
- RpcAddress:表示远程的RpcEndpointRef的地址,Host + Port。
- TransportClient:Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer;
- TransportServer:Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱;
4.4 Executor通信终端
1)在IDEA中全局查找(ctrl + n)org.apache.spark.executor.YarnCoarseGrainedExecutorBackend,点击对应的伴生对象
2)YarnCoarseGrainedExecutorBackend.scala 继承CoarseGrainedExecutorBackend继承RpcEndpoint
// constructor -> onStart -> receive* -> onStop
private[spark] trait RpcEndpoint {
val rpcEnv: RpcEnv
final def self: RpcEndpointRef = {
require(rpcEnv != null, "rpcEnv has not been initialized")
rpcEnv.endpointRef(this)
}
def receive: PartialFunction[Any, Unit] = {
case _ => throw new SparkException(self + " does not implement 'receive'")
}
def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case _ => context.sendFailure(new SparkException(self + " won't reply anything"))
}
def onStart(): Unit = {
// By default, do nothing.
}
def onStop(): Unit = {
// By default, do nothing.
}
}
private[spark] abstract class RpcEndpointRef(conf: SparkConf)
extends Serializable with Logging {
... ...
def send(message: Any): Unit
def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]
... ...
}
4.5 Driver通信终端
ExecutorBackend发送向Driver发送请求后,Driver开始接收消息。全局查找(ctrl + n)SparkContext类
SparkContext.scala
class SparkContext(config: SparkConf) extends Logging {
... ...
private var _schedulerBackend: SchedulerBackend = _
... ...
}
点击SchedulerBackend进入SchedulerBackend.scala,查找实现类(ctrl+h),找到CoarseGrainedSchedulerBackend.scala,在该类内部创建DriverEndpoint对象。
private[spark]
class CoarseGrainedSchedulerBackend(scheduler: TaskSchedulerImpl, val rpcEnv: RpcEnv)
extends ExecutorAllocationClient with SchedulerBackend with Logging {
class DriverEndpoint extends IsolatedRpcEndpoint with Logging {
override def receive: PartialFunction[Any, Unit] = {
... ...
// 接收注册成功后的消息
case LaunchedExecutor(executorId) =>
executorDataMap.get(executorId).foreach { data =>
data.freeCores = data.totalCores
}
makeOffers(executorId)
}
// 接收ask消息,并回复
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls,
attributes, resources, resourceProfileId) =>
... ...
context.reply(true)
... ...
}
... ...
}
val driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint())
protected def createDriverEndpoint(): DriverEndpoint = new DriverEndpoint()
}
DriverEndpoint继承IsolatedRpcEndpoint继承RpcEndpoint
// constructor -> onStart -> receive* -> onStop
private[spark] trait RpcEndpoint {
val rpcEnv: RpcEnv
final def self: RpcEndpointRef = {
require(rpcEnv != null, "rpcEnv has not been initialized")
rpcEnv.endpointRef(this)
}
def receive: PartialFunction[Any, Unit] = {
case _ => throw new SparkException(self + " does not implement 'receive'")
}
def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case _ => context.sendFailure(new SparkException(self + " won't reply anything"))
}
def onStart(): Unit = {
// By default, do nothing.
}
def onStop(): Unit = {
// By default, do nothing.
}
}
private[spark] abstract class RpcEndpointRef(conf: SparkConf)
extends Serializable with Logging {
... ...
def send(message: Any): Unit
def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]
... ...
}
五、Executor通信环境准备
5.1 创建RPC通信环境
1)在IDEA中全局查找(ctrl + n)org.apache.spark.executor.YarnCoarseGrainedExecutorBackend,点击对应的伴生对象
2)运行CoarseGrainedExecutorBackend
YarnCoarseGrainedExecutorBackend.scala
private[spark] object YarnCoarseGrainedExecutorBackend extends Logging {
def main(args: Array[String]): Unit = {
val createFn: (RpcEnv, CoarseGrainedExecutorBackend.Arguments, SparkEnv, ResourceProfile) =>
CoarseGrainedExecutorBackend = { case (rpcEnv, arguments, env, resourceProfile) =>
new YarnCoarseGrainedExecutorBackend(rpcEnv, arguments.driverUrl, arguments.executorId,
arguments.bindAddress, arguments.hostname, arguments.cores, arguments.userClassPath, env,
arguments.resourcesFileOpt, resourceProfile)
}
val backendArgs = CoarseGrainedExecutorBackend.parseArguments(args,
this.getClass.getCanonicalName.stripSuffix("$"))
CoarseGrainedExecutorBackend.run(backendArgs, createFn)
System.exit(0)
}
}
CoarseGrainedExecutorBackend.scala
def run(
arguments: Arguments,
backendCreateFn: (RpcEnv, Arguments, SparkEnv, ResourceProfile) =>
CoarseGrainedExecutorBackend): Unit = {
SparkHadoopUtil.get.runAsSparkUser { () =>
// Bootstrap to fetch the driver's Spark properties.
val executorConf = new SparkConf
val fetcher = RpcEnv.create(
"driverPropsFetcher",
arguments.bindAddress,
arguments.hostname,
-1,
executorConf,
new SecurityManager(executorConf),
numUsableCores = 0,
clientMode = true)
… …
driverConf.set(EXECUTOR_ID, arguments.executorId)
val env = SparkEnv.createExecutorEnv(driverConf, arguments.executorId, arguments.bindAddress,
arguments.hostname, arguments.cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor",
backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile))
arguments.workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
}
}
3)点击create,进入RpcEnv.Scala
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
new NettyRpcEnvFactory().create(config)
}
NettyRpcEnv.scala
private[rpc] class NettyRpcEnvFactory extends RpcEnvFactory with Logging {
def create(config: RpcEnvConfig): RpcEnv = {
... ...
val nettyEnv =
new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress,
config.securityManager, config.numUsableCores)
if (!config.clientMode) {
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
case NonFatal(e) =>
nettyEnv.shutdown()
throw e
}
}
nettyEnv
}
}
5.2 创建多个发件箱
NettyRpcEnv.scala
private[netty] class NettyRpcEnv(
val conf: SparkConf,
javaSerializerInstance: JavaSerializerInstance,
host: String,
securityManager: SecurityManager,
numUsableCores: Int) extends RpcEnv(conf) with Logging {
... ...
private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]()
... ...
}
5.3 启动TransportServer
NettyRpcEnv.scala
def startServer(bindAddress: String, port: Int): Unit = {
... ...
server = transportContext.createServer(bindAddress, port, bootstraps)
dispatcher.registerRpcEndpoint(
RpcEndpointVerifier.NAME, new RpcEndpointVerifier(this, dispatcher))
}
TransportContext.scala
public TransportServer createServer(
String host, int port, List<TransportServerBootstrap> bootstraps) {
return new TransportServer(this, host, port, rpcHandler, bootstraps);
}
TransportServer.java
public TransportServer(
TransportContext context,
String hostToBind,
int portToBind,
RpcHandler appRpcHandler,
List<TransportServerBootstrap> bootstraps) {
... ...
init(hostToBind, portToBind);
... ...
}
private void init(String hostToBind, int portToBind) {
// 默认是NIO模式
IOMode ioMode = IOMode.valueOf(conf.ioMode());
EventLoopGroup bossGroup = NettyUtils.createEventLoop(ioMode, 1,
conf.getModuleName() + "-boss");
EventLoopGroup workerGroup = NettyUtils.createEventLoop(ioMode, conf.serverThreads(), conf.getModuleName() + "-server");
bootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(NettyUtils.getServerChannelClass(ioMode))
.option(ChannelOption.ALLOCATOR, pooledAllocator)
.option(ChannelOption.SO_REUSEADDR, !SystemUtils.IS_OS_WINDOWS)
.childOption(ChannelOption.ALLOCATOR, pooledAllocator);
... ...
}
NettyUtils.java
public static Class<? extends ServerChannel> getServerChannelClass(IOMode mode) {
switch (mode) {
case NIO:
return NioServerSocketChannel.class;
case EPOLL:
return EpollServerSocketChannel.class;
default:
throw new IllegalArgumentException("Unknown io mode: " + mode);
}
}
5.4 注册通信终端RpcEndpoint
NettyRpcEnv.scala
def startServer(bindAddress: String, port: Int): Unit = {
... ...
server = transportContext.createServer(bindAddress, port, bootstraps)
dispatcher.registerRpcEndpoint(
RpcEndpointVerifier.NAME, new RpcEndpointVerifier(this, dispatcher))
}
5.5 创建TransportClient
Dispatcher.scala
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
... ...
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
... ...
}
private[netty] class NettyRpcEndpointRef(... ...) extends RpcEndpointRef(conf) {
... ...
@transient @volatile var client: TransportClient = _
// 创建TransportClient
private[netty] def createClient(address: RpcAddress): TransportClient = {
clientFactory.createClient(address.host, address.port)
}
private val clientFactory = transportContext.createClientFactory(createClientBootstraps())
... ...
}
5.6 收发邮件箱
1)接收邮件箱1个
Dispatcher.scala
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
... ...
var messageLoop: MessageLoop = null
try {
messageLoop = endpoint match {
case e: IsolatedRpcEndpoint =>
new DedicatedMessageLoop(name, e, this)
case _ =>
sharedLoop.register(name, endpoint)
sharedLoop
}
endpoints.put(name, messageLoop)
} catch {
... ...
}
}
endpointRef
}
DedicatedMessageLoop.scala
private class DedicatedMessageLoop(
name: String,
endpoint: IsolatedRpcEndpoint,
dispatcher: Dispatcher)
extends MessageLoop(dispatcher) {
private val inbox = new Inbox(name, endpoint)
… …
}
Inbox.scala
private[netty] class Inbox(val endpointName: String, val endpoint: RpcEndpoint)
extends Logging {
... ...
inbox.synchronized {
messages.add(OnStart)
}
... ...
}
六、Executor注册
CoarseGrainedExecutorBackend.scala
// RPC生命周期: constructor -> onStart -> receive* -> onStop
private[spark] class CoarseGrainedExecutorBackend(... ...)
extends IsolatedRpcEndpoint with ExecutorBackend with Logging {
... ...
override def onStart(): Unit = {
… …
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use "ThreadUtils.sameThread"
driver = Some(ref)
// 1向Driver注册自己
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls, extractAttributes, _resources, resourceProfile.id))
}(ThreadUtils.sameThread).onComplete {
// 2接收Driver返回成功的消息,并给自己发送注册成功消息
case Success(_) =>
self.send(RegisteredExecutor)
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
}(ThreadUtils.sameThread)
}
... ...
override def receive: PartialFunction[Any, Unit] = {
// 3收到注册成功的消息后,创建Executor,并启动Executor
case RegisteredExecutor =>
try {
// 创建Executor
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false, resources = _resources)
driver.get.send(LaunchedExecutor(executorId))
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
... ...
}
}
七、Driver接收消息并应答
ExecutorBackend发送向Driver发送请求后,Driver开始接收消息。全局查找(ctrl + n)SparkContext类
SparkContext.scala
class SparkContext(config: SparkConf) extends Logging {
... ...
private var _schedulerBackend: SchedulerBackend = _
... ...
}
点击SchedulerBackend进入SchedulerBackend.scala,查找实现类(ctrl+h),找到CoarseGrainedSchedulerBackend.scala
private[spark]
class CoarseGrainedSchedulerBackend(scheduler: TaskSchedulerImpl, val rpcEnv: RpcEnv)
extends ExecutorAllocationClient with SchedulerBackend with Logging {
class DriverEndpoint extends IsolatedRpcEndpoint with Logging {
override def receive: PartialFunction[Any, Unit] = {
... ...
// 接收注册成功后的消息
case LaunchedExecutor(executorId) =>
executorDataMap.get(executorId).foreach { data =>
data.freeCores = data.totalCores
}
makeOffers(executorId)
}
// 接收ask消息,并回复
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls,
attributes, resources, resourceProfileId) =>
... ...
context.reply(true)
... ...
}
... ...
}
val driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint())
protected def createDriverEndpoint(): DriverEndpoint = new DriverEndpoint()
}
八、Executor执行代码
8.1 SparkContext初始化完毕,通知执行后续代码
1)进入到ApplicationMaster
ApplicationMaster.scala
private[spark] class ApplicationMaster(
args: ApplicationMasterArguments,
sparkConf: SparkConf,
yarnConf: YarnConfiguration) extends Logging {
private def runDriver(): Unit = {
addAmIpFilter(None, System.getenv(ApplicationConstants.APPLICATION_WEB_PROXY_BASE_ENV))
userClassThread = startUserApplication()
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
val rpcEnv = sc.env.rpcEnv
val userConf = sc.getConf
val host = userConf.get(DRIVER_HOST_ADDRESS)
val port = userConf.get(DRIVER_PORT)
registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
val driverRef = rpcEnv.setupEndpointRef(
RpcAddress(host, port),
YarnSchedulerBackend.ENDPOINT_NAME)
createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
} else {
… …
}
// 执行程序
resumeDriver()
userClassThread.join()
} catch {
... ...
} finally {
resumeDriver()
}
}
... ...
private def resumeDriver(): Unit = {
sparkContextPromise.synchronized {
sparkContextPromise.notify()
}
}
}
8.2 接收代码继续执行消息
在SparkContext.scala文件中查找_taskScheduler.postStartHook(),点击postStartHook,查找实现类(ctrl + h)
private[spark] class YarnClusterScheduler(sc: SparkContext) extends YarnScheduler(sc) {
logInfo("Created YarnClusterScheduler")
override def postStartHook(): Unit = {
ApplicationMaster.sparkContextInitialized(sc)
super.postStartHook()
logInfo("YarnClusterScheduler.postStartHook done")
}
}
点击super.postStartHook()
TaskSchedulerImpl.scala
override def postStartHook(): Unit = {
waitBackendReady()
}
private def waitBackendReady(): Unit = {
if (backend.isReady) {
return
}
while (!backend.isReady) {
if (sc.stopped.get) {
throw new IllegalStateException("Spark context stopped while waiting for backend")
}
synchronized {
this.wait(100)
}
}
}















 3269
3269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









