









Flink流处理(开窗、水印、侧输出流)
目录
在上一个篇文章中,介绍了Flink的基础编程API的使用,接下来是Flink编程的高阶部分。所谓的高阶部分内容,其实就是Flink与其他计算框架不相同且占优势的地方,比如Window和Exactly-Once。
一、Flink的window机制
1.1 窗口概述
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而Window窗口是一种切割无限数据为有限块进行处理的手段。
在Flink中, 窗口(window)是处理无界流的核心. 窗口把流切割成有限大小的多个"存储桶"(bucket), 我们在这些桶上进行计算.
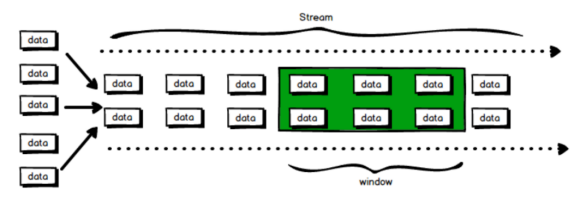
1.2 窗口的分类
窗口分为2类:
- 基于时间的窗口(时间驱动)
- 基于元素个数的(数据驱动)
1.2.1 基于时间的窗口
时间窗口包含一个开始时间戳(包括)和结束时间戳(不包括), 这两个时间戳一起限制了窗口的尺寸.
在代码中, Flink使用TimeWindow这个类来表示基于时间的窗口. 这个类提供了key查询开始时间戳和结束时间戳的方法, 还提供了针对给定的窗口获取它允许的最大时间戳的方法(maxTimestamp())
时间窗口又分4种:
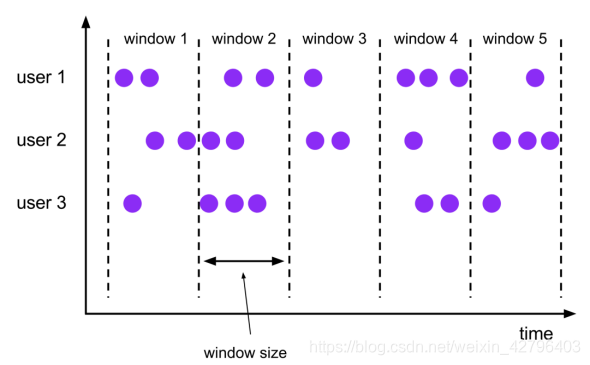
滚动窗口(Tumbling Windows)
滚动窗口有固定的大小, 窗口与窗口之间不会重叠也没有缝隙.比如,如果指定一个长度为5分钟的滚动窗口, 当前窗口开始计算, 每5分钟启动一个新的窗口.
滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。
示例代码:
env
.socketTextStream("hadoop102", 9999)
.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
Arrays.stream(value.split("\\W+")).forEach(word -> out.collect(Tuple2.of(word, 1L)));
}
})
.keyBy(t -> t.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(8))) // 添加滚动窗口
.sum(1)
.print();
说明:
- 时间间隔可以通过:
Time.milliseconds(x), Time.seconds(x), Time.minutes(x),等等来指定. - 我们传递给window函数的对象叫
窗口分配器.
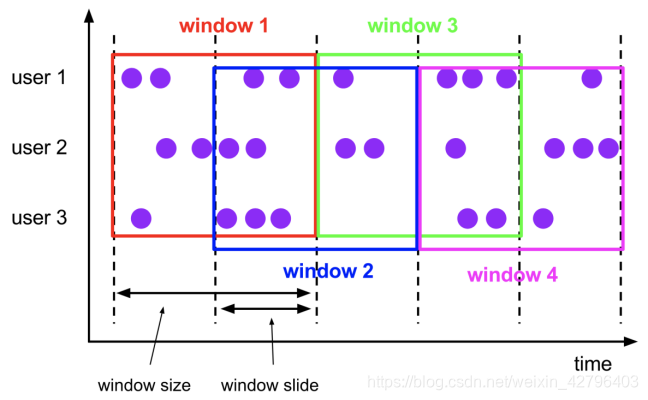
滑动窗口(Sliding Windows)
与滚动窗口一样, 滑动窗口也是有固定的长度. 另外一个参数我们叫滑动步长, 用来控制滑动窗口启动的频率.
所以, 如果滑动步长小于窗口长度, 滑动窗口会重叠. 这种情况下, 一个元素可能会被分配到多个窗口中
例如, 滑动窗口长度10分钟, 滑动步长5分钟, 则, 每5分钟会得到一个包含最近10分钟的数据.
示例代码:
env
.socketTextStream("hadoop102", 9999)
.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
Arrays.stream(value.split("\\W+")).forEach(word -> out.collect(Tuple2.of(word, 1L)));
}
})
.keyBy(t -> t.f0)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) // 添加滚动窗口
.sum(1)
.print();
env.execute();
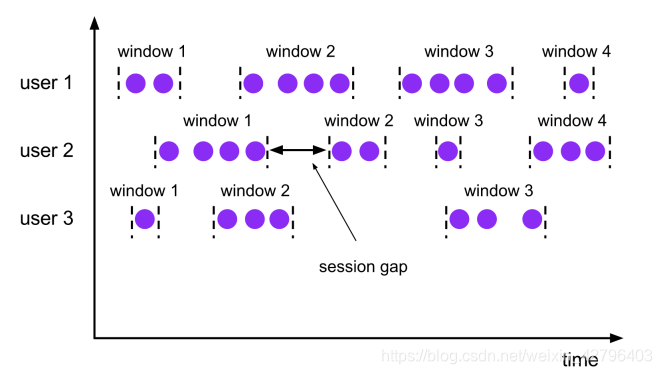
会话窗口(Session Windows)
会话窗口分配器会根据活动的元素进行分组. 会话窗口不会有重叠, 与滚动窗口和滑动窗口相比, 会话窗口也没有固定的开启和关闭时间.
如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的时间就是会话窗口的gap(间隔)
我们可以配置静态的gap, 也可以通过一个gap extractor 函数来定义gap的长度. 当时间超过了这个gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话窗口
示例代码:
1.静态gap
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
2.动态gap
.window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) { // 返回 gap值, 单位毫秒
return element.f0.length() * 1000;
}
}))
创建原理:
因为会话窗口没有固定的开启和关闭时间, 所以会话窗口的创建和关闭与滚动,滑动窗口不同. 在Flink内部, 每到达一个新的元素都会创建一个新的会话窗口, 如果这些窗口彼此相距比较定义的gap小, 则会对他们进行合并. 为了能够合并, 会话窗口算子需要合并触发器和合并窗口函数: ReduceFunction, AggregateFunction, or ProcessWindowFunction
全局窗口(Global Windows)
全局窗口分配器会分配相同key的所有元素进入同一个 Global window. 这种窗口机制只有指定自定义的触发器时才有用. 否则, 不会做任务计算, 因为这种窗口没有能够处理聚集在一起元素的结束点.

示例代码:
.window(GlobalWindows.create());
1.2.2 基于元素个数的窗口
按照指定的数据条数生成一个Window,与时间无关
分2类:
滚动窗口
默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
实例代码
.countWindow(3)
说明:哪个窗口先达到3个元素, 哪个窗口就关闭. 不影响其他的窗口.
滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围最多是3个元素。
实例代码
.countWindow(3, 2)
1.3 Window Function
前面指定了窗口的分配器, 接着我们需要来指定如何计算, 这事由window function来负责. 一旦窗口关闭, window function 去计算处理窗口中的每个元素.
window function 可以是ReduceFunction,AggregateFunction,or ProcessWindowFunction中的任意一种.
ReduceFunction,AggregateFunction更加高效, 原因就是Flink可以对到来的元素进行增量聚合 . ProcessWindowFunction 可以得到一个包含这个窗口中所有元素的迭代器, 以及这些元素所属窗口的一些元数据信息.
ProcessWindowFunction不能被高效执行的原因是Flink在执行这个函数之前, 需要在内部缓存这个窗口上所有的元素
- ReduceFunction(增量聚合函数)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
System.out.println(value1 + " ----- " + value2);
// value1是上次聚合的结果. 所以遇到每个窗口的第一个元素时, 这个函数不会进来
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
- AggregateFunction(增量聚合函数)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new AggregateFunction<Tuple2<String, Long>, Long, Long>() {
// 创建累加器: 初始化中间值
@Override
public Long createAccumulator() {
System.out.println("createAccumulator");
return 0L;
}
// 累加器操作
@Override
public Long add(Tuple2<String, Long> value, Long accumulator) {
System.out.println("add");
return accumulator + value.f1;
}
// 获取结果
@Override
public Long getResult(Long accumulator) {
System.out.println("getResult");
return accumulator;
}
// 累加器的合并: 只有会话窗口才会调用
@Override
public Long merge(Long a, Long b) {
System.out.println("merge");
return a + b;
}
})
- ProcessWindowFunction(全窗口函数)
.process(new ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>() {
// 参数1: key 参数2: 上下文对象 参数3: 这个窗口内所有的元素 参数4: 收集器, 用于向下游传递数据
@Override
public void process(String key,
Context context,
Iterable<Tuple2<String, Long>> elements,
Collector<Tuple2<String, Long>> out) throws Exception {
System.out.println(context.window().getStart());
long sum = 0L;
for (Tuple2<String, Long> t : elements) {
sum += t.f1;
}
out.collect(Tuple2.of(key, sum));
}
})
二、Keyed vs Non-Keyed Windows
其实, 在用window前首先需要确认应该是在keyBy后的流上用, 还是在没有keyBy的流上使用.
在keyed streams上使用窗口, 窗口计算被并行的运用在多个task上, 可以认为每个task都有自己单独窗口. 正如前面的代码所示.
在非non-keyed stream上使用窗口, 流的并行度只能是1, 所有的窗口逻辑只能在一个单独的task上执行.
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)))
需要注意的是: 非key分区的流上使用window, 如果把并行度强行设置为>1, 则会抛出异常
三、Flik中的时间语义与WaterMark
3.1 Flink中的时间语义
在Flink的流式操作中, 会涉及不同的时间概念
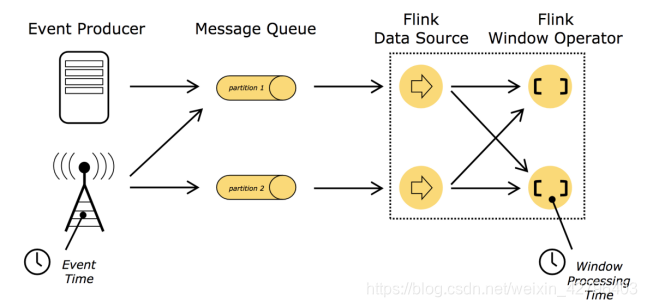
3.1.1 处理时间(process time)
处理时间是指的执行操作的各个设备的时间
对于运行在处理时间上的流程序, 所有的基于时间的操作(比如时间窗口)都是使用的设备时钟.比如, 一个长度为1个小时的窗口将会包含设备时钟表示的1个小时内所有的数据. 假设应用程序在 9:15am分启动, 第1个小时窗口将会包含9:15am到10:00am所有的数据, 然后下个窗口是10:00am-11:00am, 等等
处理时间是最简单时间语义, 数据流和设备之间不需要做任何的协调. 他提供了最好的性能和最低的延迟. 但是, 在分布式和异步的环境下, 处理时间没有办法保证确定性, 容易受到数据传递速度的影响: 事件的延迟和乱序
在使用窗口的时候, 如果使用处理时间, 就指定时间分配器为处理时间分配器
3.1.2 事件时间(event time)
事件时间是指的这个事件发生的时间.
在event进入Flink之前, 通常被嵌入到了event中, 一般作为这个event的时间戳存在.
在事件时间体系中, 时间的进度依赖于数据本身, 和任何设备的时间无关. 事件时间程序必须制定如何产生Event Time Watermarks(水印) . 在事件时间体系中, 水印是表示时间进度的标志(作用就相当于现实时间的时钟).
在理想情况下,不管事件时间何时到达或者他们的到达的顺序如何, 事件时间处理将产生完全一致且确定的结果. 事件时间处理会在等待无序事件(迟到事件)时产生一定的延迟。由于只能等待有限的时间,因此这限制了确定性事件时间应用程序的可使用性。
假设所有数据都已到达,事件时间操作将按预期方式运行,即使在处理无序或迟到的事件或重新处理历史数据时,也会产生正确且一致的结果。例如,每小时事件时间窗口将包含带有事件时间戳的所有记录,该记录落入该小时,无论它们到达的顺序或处理时间。
在使用窗口的时候, 如果使用事件时间, 就指定时间分配器为事件时间分配器
注意:
在1.12之前默认的时间语义是处理时间, 从1.12开始, Flink内部已经把默认的语义改成了事件时间
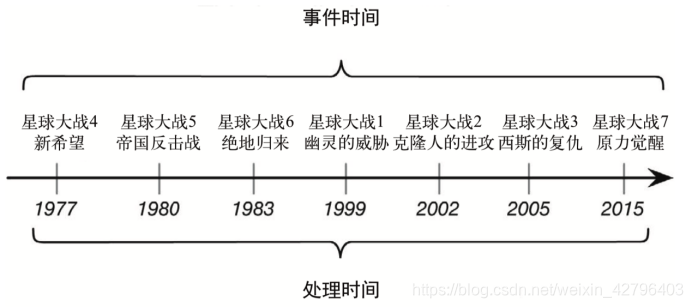
3.2 哪种时间更重要
3.3 Flink中的WaterMark
支持event time的流式处理框架需要一种能够测量event time 进度的方式. 比如, 一个窗口算子创建了一个长度为1小时的窗口,那么这个算子需要知道事件时间已经到达了这个窗口的关闭时间, 从而在程序中去关闭这个窗口.
事件时间可以不依赖处理时间来表示时间的进度. 例如, 在程序中, 即使处理时间和事件时间有相同的速度, 事件时间可能会轻微的落后处理时间. 另外一方面,使用事件时间可以在几秒内处理已经缓存在Kafka中多周的数据, 这些数据可以照样被正确处理, 就像实时发生的一样能够进入正确的窗口.
这种在Flink中去测量事件时间的进度的机制就是 watermark(水印). watermark作为数据流的一部分在流动, 并且携带一个时间戳t.
一个Watermark(t)表示在这个流里面事件时间已经到了时间t, 意味着此时, 流中不应该存在这样的数据: 他的时间戳t2<=t (时间比较旧或者等于时间戳)
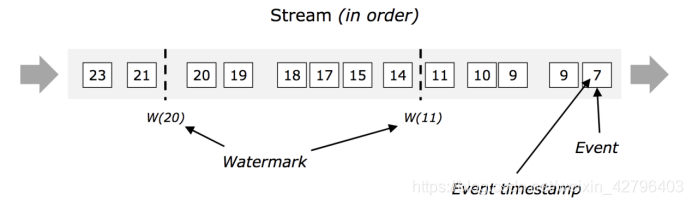
有序流中的水印
在下面的这个图中, 事件是有序的(按照他们自己的时间戳来看), watermark是流中一个简单的周期性的标记
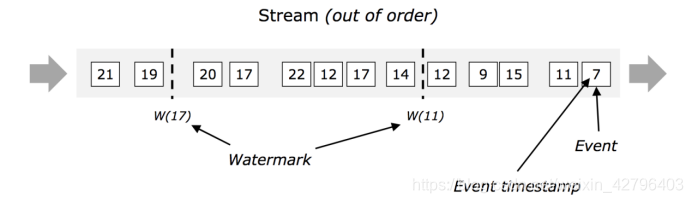
乱序流中的水印
在下图中, 按照他们时间戳来看, 这些事件是乱序的, 则watermark对于这些乱序的流来说至关重要.
通常情况下, 水印是一种标记, 是流中的一个点, 所有在这个时间戳(水印中的时间戳)前的数据应该已经全部到达. 一旦水印到达了算子, 则这个算子会提高他内部的时钟的值为这个水印的值.
3.4 Flink中如何产生水印
在 Flink 中, 水印由应用程序开发人员生成, 这通常需要对相应的领域有 一定的了解。完美的水印永远不会错:时间戳小于水印标记时间的事件不会再出现。在特殊情况下(例如非乱序事件流),最近一次事件的时间戳就可能是完美的水印。
启发式水印则相反,它只估计时间,因此有可能出错, 即迟到的事件 (其时间戳小于水印标记时间)晚于水印出现。针对启发式水印, Flink 提供了处理迟到元素的机制。
设定水印通常需要用到领域知识。举例来说,如果知道事件的迟到时间不会超过 5 秒, 就可以将水印标记时间设为收到的最大时间戳减去 5 秒。 另 一种做法是,采用一个 Flink 作业监控事件流,学习事件的迟到规律,并以此构建水印生成模型。
3.5 EventTime和WaterMark的使用
Flink内置了两个WaterMark生成器:
- Monotonously Increasing Timestamps(时间戳单调增长:其实就是允许的延迟为0)
WatermarkStrategy.forMonotonousTimestamps();
- Fixed Amount of Lateness(允许固定时间的延迟)
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class Flink10_Chapter07_OrderedWaterMark {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env
.socketTextStream("hadoop102", 9999) // 在socket终端只输入毫秒级别的时间戳
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
// 创建水印生产策略
WatermarkStrategy<WaterSensor> wms = WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // // 最大容忍的延迟时间
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() { // 指定时间戳
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000;
}
});
stream
.assignTimestampsAndWatermarks(wms) // 指定水印和时间戳
.keyBy(WaterSensor: :getId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
String msg = "当前key: " + key
+ "窗口: [" + context.window().getStart() / 1000 + "," + context.window().getEnd()/1000 + ") 一共有 "
+ elements.spliterator().estimateSize() + "条数据 ";
out.collect(msg);
}
})
.print();
env.execute();
}
}
3.6 自定义WatermarkStrategy
有2种风格的WaterMark生产方式: periodic(周期性) and punctuated(间歇性).都需要继承接口: WatermarkGenerator
- 周期性
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class Flink11_Chapter07_Period {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env
.socketTextStream("hadoop102", 9999) // 在socket终端只输入毫秒级别的时间戳
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
// 创建水印生产策略
WatermarkStrategy<WaterSensor> myWms = new WatermarkStrategy<WaterSensor>() {
@Override
public WatermarkGenerator<WaterSensor> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
System.out.println("createWatermarkGenerator ....");
return new MyPeriod(3);
}
}.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println("recordTimestamp " + recordTimestamp);
return element.getTs() * 1000;
}
});
stream
.assignTimestampsAndWatermarks(myWms)
.keyBy(WaterSensor::getId)
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(5)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
String msg = "当前key: " + key
+ "窗口: [" + context.window().getStart() / 1000 + "," + context.window().getEnd() / 1000 + ") 一共有 "
+ elements.spliterator().estimateSize() + "条数据 ";
out.collect(context.window().toString());
out.collect(msg);
}
})
.print();
env.execute();
}
public static class MyPeriod implements WatermarkGenerator<WaterSensor> {
private long maxTs = Long.MIN_VALUE;
// 允许的最大延迟时间 ms
private final long maxDelay;
public MyPeriod(long maxDelay) {
this.maxDelay = maxDelay * 1000;
this.maxTs = Long.MIN_VALUE + this.maxDelay + 1;
}
// 每收到一个元素, 执行一次. 用来生产WaterMark中的时间戳
@Override
public void onEvent(WaterSensor event, long eventTimestamp, WatermarkOutput output) {
System.out.println("onEvent..." + eventTimestamp);
//有了新的元素找到最大的时间戳
maxTs = Math.max(maxTs, eventTimestamp);
System.out.println(maxTs);
}
// 周期性的把WaterMark发射出去, 默认周期是200ms
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// System.out.println("onPeriodicEmit...");
// 周期性的发射水印: 相当于Flink把自己的时钟调慢了一个最大延迟
output.emitWatermark(new Watermark(maxTs - maxDelay - 1));
}
}
}
- 间歇性
public class Flink12_Chapter07_punctuated {
public static void main(String[] args) throws Exception {
// 省略....
public static class MyPunctuated implements WatermarkGenerator<WaterSensor> {
private long maxTs;
// 允许的最大延迟时间 ms
private final long maxDelay;
public MyPunctuated(long maxDelay) {
this.maxDelay = maxDelay * 1000;
this.maxTs = Long.MIN_VALUE + this.maxDelay + 1;
}
// 每收到一个元素, 执行一次. 用来生产WaterMark中的时间戳
@Override
public void onEvent(WaterSensor event, long eventTimestamp, WatermarkOutput output) {
System.out.println("onEvent..." + eventTimestamp);
//有了新的元素找到最大的时间戳
maxTs = Math.max(maxTs, eventTimestamp);
output.emitWatermark(new Watermark(maxTs - maxDelay - 1));
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要实现
}
}
}
3.7 多并行度下WaterMark的传递
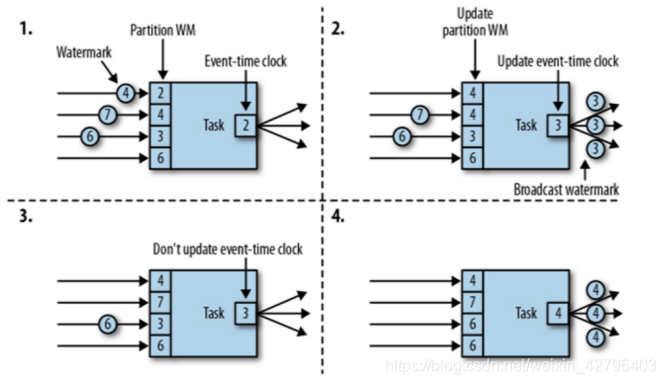
总结: 多并行度的条件下, 向下游传递WaterMark的时候, 总是以最小的那个WaterMark为准! 木桶原理!
四、窗口允许迟到的数据
已经添加了wartemark之后, 仍有数据会迟到怎么办? Flink的窗口, 也允许迟到数据.
当触发了窗口计算后, 会先计算当前的结果, 但是此时并不会关闭窗口.以后每来一条迟到数据, 则触发一次这条数据所在窗口计算(增量计算).
那么什么时候会真正的关闭窗口呢? wartermark 超过了窗口结束时间+等待时间
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
注意:
允许迟到只能运用在event time上
五、侧输出流(sideOutput)
5.1 接收窗口关闭之后的迟到数据
允许迟到数据, 窗口也会真正的关闭, 如果还有迟到的数据怎么办? Flink提供了一种叫做侧输出流的来处理关窗之后到达的数据.
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class Flink13_Chapter07_SideOutput {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
System.out.println(env.getConfig());
SingleOutputStreamOperator<WaterSensor> stream = env
.socketTextStream("hadoop102", 9999) // 在socket终端只输入毫秒级别的时间戳
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
});
// 创建水印生产策略
WatermarkStrategy<WaterSensor> wms = WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 最大容忍的延迟时间
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() { // 指定时间戳
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000;
}
});
SingleOutputStreamOperator<String> result = stream
.assignTimestampsAndWatermarks(wms)
.keyBy(WaterSensor::getId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
.sideOutputLateData(new OutputTag<WaterSensor>("side_1") {
}) // 设置侧输出流
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
String msg = "当前key: " + key
+ " 窗口: [" + context.window().getStart() / 1000 + "," + context.window().getEnd() / 1000 + ") 一共有 "
+ elements.spliterator().estimateSize() + "条数据" +
"watermark: " + context.currentWatermark();
out.collect(context.window().toString());
out.collect(msg);
}
});
result.print();
result.getSideOutput(new OutputTag<WaterSensor>("side_1"){}).print();
env.execute();
}
}
5.2 使用侧输出流把一个流拆成多个流
split算子可以把一个流分成两个流, 从1.12开始已经被移除了. 官方建议我们用侧输出流来替换split算子的功能.
需求: 采集监控传感器水位值,将水位值高于5cm的值输出到side output
SingleOutputStreamOperator<WaterSensor> result =
env
.socketTextStream("hadoop102", 9999) // 在socket终端只输入毫秒级别的时间戳
.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
})
.keyBy(ws -> ws.getTs())
.process(new KeyedProcessFunction<Long, WaterSensor, WaterSensor>() {
@Override
public void processElement(WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception {
out.collect(value);
if (value.getVc() > 5) { //水位大于5的写入到侧输出流
ctx.output(new OutputTag<WaterSensor>("警告") {}, value);
}
}
});
result.print("主流");
result.getSideOutput(new OutputTag<WaterSensor>("警告"){}).print("警告");
六、ProcessFunction API(底层API)
我们之前介绍的转换算子是无法访问事件的时间戳信息和水位线信息的。而这在一些应用场景下,极为重要。例如MapFunction这样的map转换算子就无法访问时间戳或者当前事件的事件时间。
基于此,DataStream API提供了一系列的Low-Level转换算子。可以访问时间戳、watermark以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。Process Function用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的window函数和转换算子无法实现)。例如,Flink SQL就是使用Process Function实现的。
Flink提供了8个Process Function:
6.1 ProcessFunction
env
.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] datas = line.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
})
.process(new ProcessFunction<WaterSensor, String>() {
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
out.collect(value.toString());
}
})
.print();
6.2 KeyedProcessFunction
env
.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] datas = line.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
})
.keyBy(ws -> ws.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() { // 泛型1:key的类型 泛型2:输入类型 泛型3:输出类型
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
System.out.println(ctx.getCurrentKey());
out.collect(value.toString());
}
})
.print();
6.3 CoProcessFunction
DataStreamSource<Integer> intStream = env.fromElements(1, 2, 3, 4, 5);
DataStreamSource<String> stringStream = env.fromElements("a", "b", "c");
ConnectedStreams<Integer, String> cs = intStream.connect(stringStream);
cs
.process(new CoProcessFunction<Integer, String, String>() {
@Override
public void processElement1(Integer value, Context ctx, Collector<String> out) throws Exception {
out.collect(value.toString());
}
@Override
public void processElement2(String value, Context ctx, Collector<String> out) throws Exception {
out.collect(value);
}
})
.print();
6.4 ProcessJoinFunction
SingleOutputStreamOperator<WaterSensor> s1 = env
.socketTextStream("hadoop102", 8888) // 在socket终端只输入毫秒级别的时间戳
.map(value -> {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
});
SingleOutputStreamOperator<WaterSensor> s2 = env
.socketTextStream("hadoop102", 9999) // 在socket终端只输入毫秒级别的时间戳
.map(value -> {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
});
s1.join(s2)
.where(WaterSensor::getId)
.equalTo(WaterSensor::getId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5))) // 必须使用窗口
.apply(new JoinFunction<WaterSensor, WaterSensor, String>() {
@Override
public String join(WaterSensor first, WaterSensor second) throws Exception {
return "first: " + first + ", second: " + second;
}
})
.print();
6.5 BroadcastProcessFunction
广播流中使用
6.6 KeyedBroadcastProcessFunction
keyBy之后使用
6.7 ProcessWindowFunction
添加窗口之后使用
6.8 ProcessAllWindowFunction
全窗口函数之后使用














 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









