







 文章介绍了如何使用LangChain和GPT技术来解析PDF文件,通过问答方式提取内容摘要。首先,PDF内容被拆分成小块并进行向量化,然后利用向量数据库和相似度计算找到相关文本片段。当用户提问时,系统通过向量匹配找到最相关的文本,再由GPT进行总结和回答,从而避免了直接使用GPT可能导致的Token限制和高成本问题。
文章介绍了如何使用LangChain和GPT技术来解析PDF文件,通过问答方式提取内容摘要。首先,PDF内容被拆分成小块并进行向量化,然后利用向量数据库和相似度计算找到相关文本片段。当用户提问时,系统通过向量匹配找到最相关的文本,再由GPT进行总结和回答,从而避免了直接使用GPT可能导致的Token限制和高成本问题。
hatPDF 最近比较火,上传 PDF 文件后,即可通过问答的方式让他帮你总结内容,比如让它帮你概括核心观点、询问问题,或者做观点判断。
背后用到了几个比较时髦的技术,还好有 ChatGPT for YOUR OWN PDF files with LangChain 解释了背后的原理,我觉得非常精彩,因此记录下来并做一些思考,希望可以帮到大家。
技术思路概括
由于 GPT 非常强大,只要你把 PDF 文章内容发给他,他就可以解答你对于该文章的任何问题了。-- 全文完。
等等,那么为什么要提到 langChain 与 vector dataBase?因为 PDF 文章内容太长了,直接传给 GPT 很容易超出 Token 限制,就算他允许无限制的 Token 传输,可能一个问题可能需要花费 10~100 美元,这个 成本 也是不可接受的。
因此黑魔法来了,下图截取自视频 ChatGPT for YOUR OWN PDF files with LangChain:
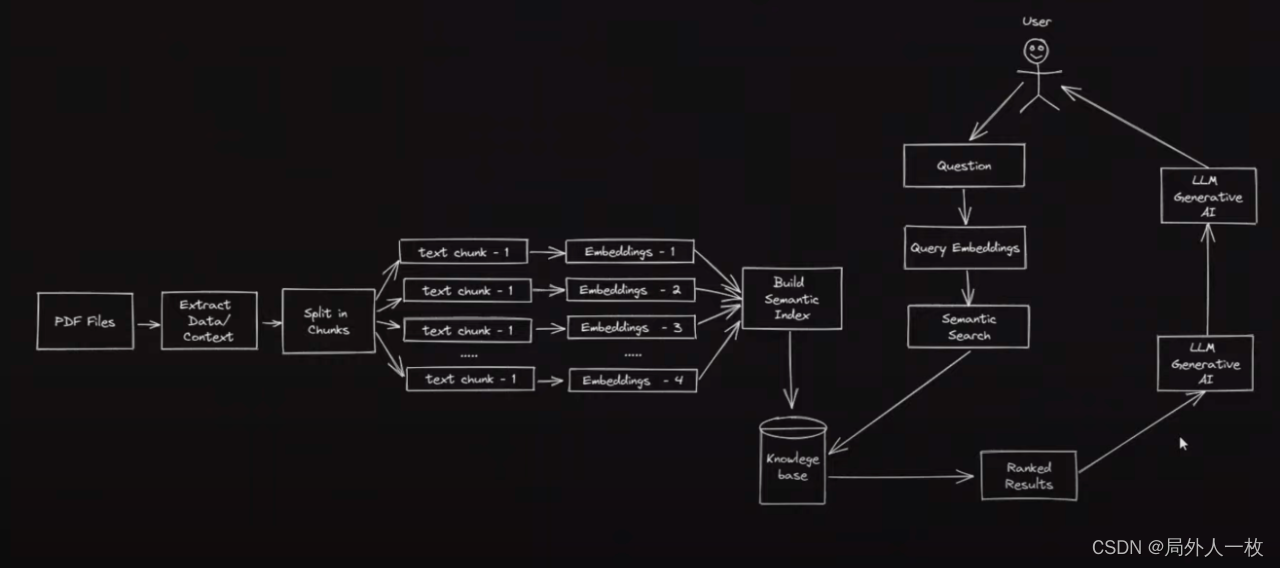
我们一步步解读:
- 找一些库把 PDF 内容文本提取出来。
- 把这些文本拆分成 N 份更小的文本,用 openai 进行文本向量化。
- 当用户提问时,对用户提问进行向量化,并用数学函数计算与 PDF 已向量化内容的相似程度。
- 把最相似的文本发送给 openai,让他总结并回答你的问题。
利用 GPT 解读 PDF 的实现步骤
我把视频里每一步操作重新介绍一遍,并补上自己的理解。
登录 colab
你可以在本地电脑运行 python 一步步执行,也可以直接登录 colab 这个 python 运行平台,它提供了很方便的 python 环境,并且可以一步步执行代码并保存,非常适合做研究。
只要你有谷歌账号就可以使用 colab。
安装依赖
要运行一堆 gpt 相关函数,需要安装一些包,虽然本质上都是不断给 gpt openapi 发 http 请求,但封装后确实会语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











