






UMAP降维方法
概述
UMAP(Uniform Manifold Approximation and Projection)是一种基于流形学习与拓扑数据分析的非线性降维算法,其理论基础扎根于黎曼几何和代数拓扑,能够在保持局部和全局结构的同时,对高维数据进行高效、可扩展的映射。其核心思想是:首先假设数据分布在高维黎曼流形上,并近似认为局部流形度量恒定;然后在高维与低维空间分别构建模糊单纯形复形(fuzzy simplicial sets),并通过最小化两者之间的交叉熵来优化低维表示,从而实现流形结构的保留与展平 arXivumap-learn.readthedocs.io。UMAP 广泛应用于可视化、聚类、异常检测、单细胞生物学、图像与文本嵌入等领域,其支持外样本映射、参数化扩展(Parametric UMAP)、密度保留(DensMAP)和监督式降维等多种变体,能够满足从离线分析到在线增量更新的多样化需求 umap-learn.readthedocs.ioSpringerLink。
理论框架
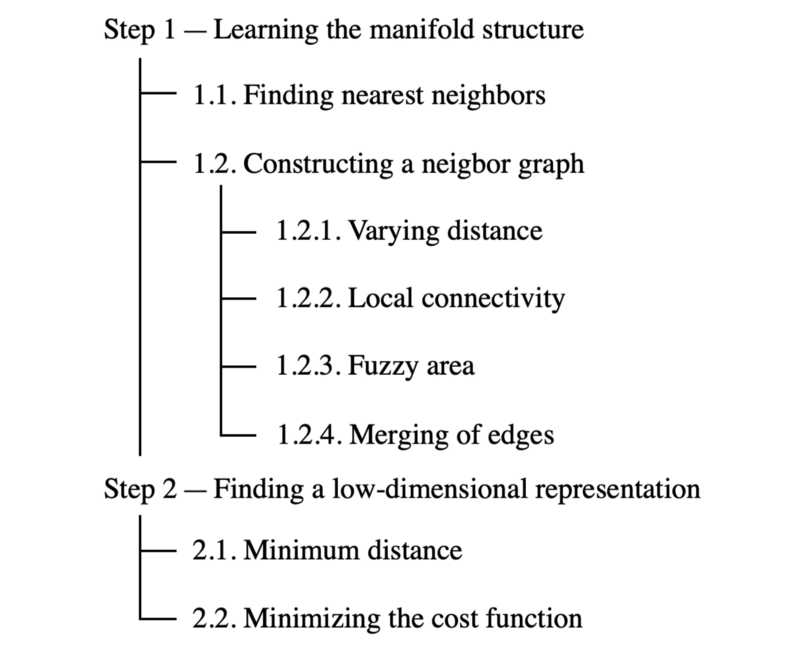
1. 流形假设与度量
UMAP 假设高维数据均匀分布在某个黎曼流形上,且该流形的度量在局部可近似为常数 umap-learn.readthedocs.io。
2. 构建模糊单纯形复形
- 高维图:利用近似最近邻算法(如 NN-Descent)确定每个点的邻域,并根据距离构建加权图。
- 概率化处理:将邻域关系转化为模糊集合,通过模糊单纯形复形表征流形的拓扑结构 umap-learn.readthedocs.io。
3. 低维结构的优化
在低维空间中,同样构建一个模糊单纯形复形,并通过最小化高维与低维复形间的交叉熵(cross-entropy)损失函数来优化点的低维坐标 arXiv。
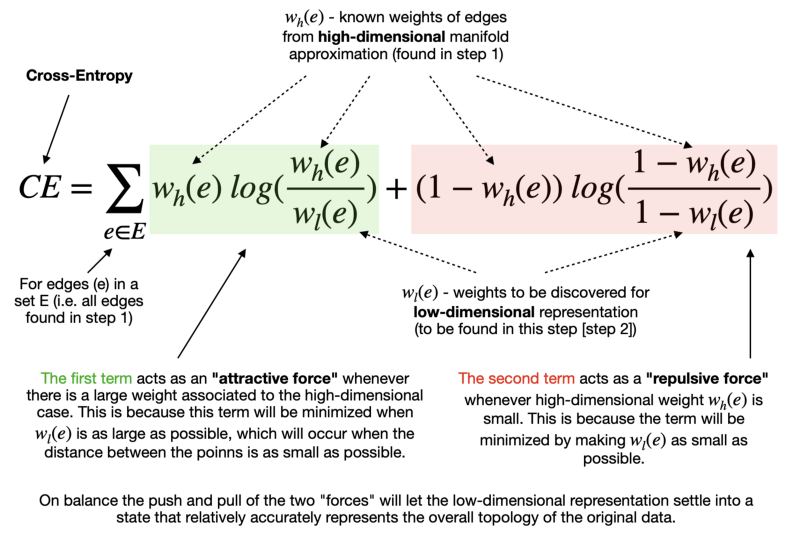
4. 数学基础
UMAP 的理论支撑来自:
- 黎曼几何:描述流形上的度量与邻域结构。
- 代数拓扑:使用单纯形复形与范畴论(category theory)刻画高维数据的拓扑特征 SpringerLink。
环境准备与安装
-
安装包:
pip install umap-learnUMAP 在 PyPI 上以
umap-learn发布,安装后即可在 Python 中调用 (Medium)。 -
导入库:
import umap import numpy as np官方推荐通过
import umap或import umap.umap_ as umap引入实现模块 (GeeksforGeeks)。
数据预处理
- 标准化/归一化:
对于不同量纲特征,应使用sklearn.preprocessing.StandardScaler或MinMaxScaler进行预处理,避免距离计算偏差 (RS Blog)。 - 可选的初步降维:
对于超高维数据(如文本嵌入或基因表达),可先用 PCA 将维度降至 50–100,再执行 UMAP,以提升速度和稳定性 (Pair Code)。
UMAP 模型构建与降维
构建 UMAP 对象
reducer = umap.UMAP(
n_neighbors=15, # 邻域大小,平衡局部/全局结构
min_dist=0.1, # 控制嵌入中点的最小距离
n_components=2, # 目标低维空间维度
metric='euclidean', # 距离度量,可选 'cosine', 'manhattan' 等
random_state=42 # 固定随机种子以复现结果
)
- n_neighbors:推荐取 5–50 之间,根据数据密度调优(umap-learn.readthedocs.io)。
- min_dist:值越小,簇越紧凑;值越大,保留更多全局结构(umap-learn.readthedocs.io)。
- metric:除了欧氏距离,还支持余弦相似度、闵可夫斯基距离等(GitHub)。
拟合与降维
embedding = reducer.fit_transform(X) # X: shape (n_samples, n_features)
fit_transform同时完成模型训练与数据映射,可直接返回低维坐标(umap-learn.readthedocs.io)。
外样本映射
new_embedding = reducer.transform(X_new)
- 训练好模型后,可用
transform将新样本投影到已有低维空间,便于在线/增量应用(umap-learn.readthedocs.io)。
可视化结果
import matplotlib.pyplot as plt
plt.scatter(
embedding[:, 0],
embedding[:, 1],
c=labels, # 若有类别标签,可用不同颜色区分
cmap='Spectral',
s=5
)
plt.title('UMAP projection')
plt.xlabel('UMAP-1')
plt.ylabel('UMAP-2')
plt.show()
- 使用
matplotlib绘制散点图,配合c参数按标签着色,有助于观察簇结构与类别分布 (Data Apps for Production | Plotly)。
适用范围
非线性降维与可视化
UMAP 能在 2–3 维空间中直观展现高维数据的集群与流形结构,常用于科学可视化与探索性数据分析 Pair Code。
单细胞生物学
广泛应用于单细胞 RNA 测序数据的可视化与聚类,帮助研究者揭示细胞类型与发育轨迹 科学直接。
图像处理与计算机视觉
在图像特征嵌入上,可用于聚类相似图像、异常检测及预训练模型输出的可视化 数字分析。
文本与嵌入向量
对大规模文本嵌入(如 BERT、GPT 产出)进行降维,可视化主题分布与语义空间,并支持在线映射新文档 Data Science Stack Exchange。
聚类与异常检测
通过降维后的结构分离能力,可结合 HDBSCAN 等算法进行精细聚类,也可检测远离簇心的异常点 umap-learn.readthedocs.io。
参数化与密度保留扩展
-
Parametric UMAP:利用神经网络学习可微映射,适合大规模数据与反向映射需求 arXiv。
-
DensMAP:在 UMAP 损失中加入密度保留正则化,以改善不同密度簇的视觉一致性 arXiv。
参数调优与进阶
参数调优
- n_neighbors:影响局部与全局结构的平衡,数值越大,更关注全局结构;越小,更强调局部结构(Topos Institute)。
- min_dist:控制低维嵌入中点的最小距离,可通过网格搜索优化分类或聚类效果(数字分析)。
- metric:文本嵌入常用
cosine度量,图像特征可考虑manhattan或自定义核函数(Medium)。
高级应用
- Parametric UMAP:结合神经网络,可学习参数化映射函数,适合大规模或需要反向映射时使用(umap-learn.readthedocs.io)。
- DensMAP:在 UMAP 基础上加入密度保留正则化,改善不同密度簇的可视化效果(umap-learn.readthedocs.io)。
- 监督式 UMAP:利用标签信息引导嵌入,提升分类分离度(umap-learn.readthedocs.io)。
参考示例与资源
- 官方文档:How to Use UMAP (umap-learn.readthedocs.io) · How UMAP Works (umap-learn.readthedocs.io)
- 教程与博客:
- GeeksforGeeks UMAP 示例 (GeeksforGeeks)
- Number Analytics 实战指南 (数字分析)
- Renesh Bedre Python 指南 (RS Blog)
- 示例代码集:UMAP auto_examples (umap-learn.readthedocs.io)

















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









