







SENet:Squeeze-and-Excitation Networks
主要思路:语义分割中一项重要目标是提高卷积的感受野,即空间上融合更多特征融合,对于channel维度的特征融合,卷积操作基本上默认对输入特征图的所有channel进行融合。SENet的创新点在于关注channel之间的关系,使模型自动学习不同channel特征的重要程度,提出了Squeeze-and-Excitation (SE)模块:

首先对卷积得到的特征图进行Squeeze操作(global pooling),得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。该机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。
对于普通的卷及操作,若以U = [u1,u2… uC]为输出特征图,v是2D空间卷积,X是输入特征图,则其表达式如下:
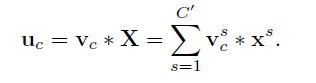
由于对各个channel的卷积结果做了sum,所以channel特征关系与卷积核学习到的空间关系混合在一起,而SE模块就是为了抽离这种混杂,使得模型直接学习到channel特征关系。
Squeeze: Global Information Embedding
卷积在局部空间内的操作很难获得足够的信息来提取channel之间的关系,感受野受到限制。Squeeze操作将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现。
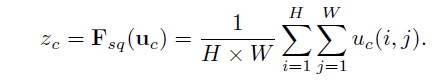
Excitation: Adaptive Recalibration
为了降低模型复杂度以及提升泛化能力,首先采用两个FC全连接层的bottleneck结构,第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。
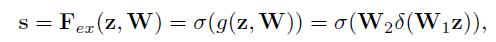
最后将学习到的各个channel的激活值(sigmoid激活,值0~1)乘以U上的原始特征:
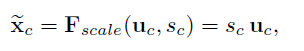
由此获得各个channel的权重系数,从而使得模型对各个channel的特征更有辨别能力。


SENet可以灵活地嵌入各种backbone中,增加的运算量也很难小,可移植性强。
Non-local:Non-local Neural Networks for Video Classification
**主要思路:**单纯的卷积操作感受野有限,为了达到non local的效果(long range dependency),需要不断叠加卷积层提取特征,深层网络的感受野(receptive field)越来越大,获取的信息分布广度也越来越高。但是这种不断叠加的方式必然会带来计算量的增加和优化难度的增加,因此就有了本文从attention的角度出发提出了non local机制。
non-local操作的定义如下:
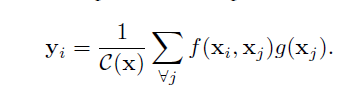
其中x表示输入信号(图片,序列,视频等,也可能是它们的features),y表示输出信号,其size和x相同。f(xi,xj)f(xi,xj)用来计算i和所有可能关联的位置j之间pairwise的关系,这个关系可以是比如i和j的位置距离越远,f值越小,表示j位置对i影响越小。g(xj)g(xj)用于计算输入信号在j位置的特征值。C(x)是归一化参数。
non-local block:
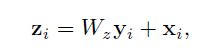
其中+xi则表示的是一个residual connection,该结构可以允许在任意的pretrain模型中插入一个新的non-local block而不需要改变其原有的结构,其具体实现如下图所示:

DANet:Dual Attention Network for Scene Segmentation
主要思想:物体或物体在尺度、光照和视图上是不同的,由于卷积运算会产生局部感受野,因此相同标签像素对应的特征可能会有所不同。这些差异导致类内不一致,影响识别的准确性。为了解决这个问题,DANet自适应地集成局部特征和全局依赖关系,分别对空间维度和通道维度的语义相互依赖进行建模。

Position Attention Module
为了在局部特征之上建立丰富的上下文关系模型,引入了位置注意模块。位置注意模块将更广泛的上下文信息编码为局部特征,从而提高了局部特征的表示能力:
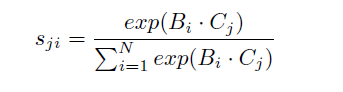
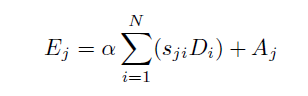
其实与non-local一样,先做矩阵转置和矩阵乘法得到(HWHW)的特征图,然后用softmax处理,得到spatial attention的特征图后与另一幅(CHW)的特征图做矩阵乘法,最后与原始图做residual connection。
Channel Attention Module
每个高级特征的通道映射都可以看作是一个类特有的响应,不同的语义响应相互关联。通过挖掘通道映射之间的相互依赖关系,可以强调相互依赖的特征映射并改进特定语义的特征表示:
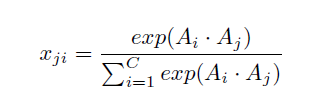
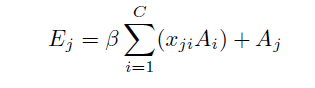
与spatial attention不同在于第一步特征图的转置与生成,得到的是(C*C)的特征图,然后同样是softmax,矩阵乘法matrix multiplication和residual connection。
class PAM_Module(nn.Module):
""" Position attention module"""
# Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
se 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









