







稀疏自注意力(Sparse Self-Attention)
稀疏自注意力是一种改进的自注意力机制,用于提高计算效率和减少计算复杂度。在传统的自注意力机制中,每个输入元素(token)都需要与所有其他输入元素计算注意力权重,这导致了计算复杂度为 (O(N^2))(其中 (N) 是序列长度)。当序列长度很大时,这种计算复杂度会变得非常高,难以处理长序列。
稀疏自注意力通过引入稀疏矩阵,使得每个输入元素只与部分输入元素计算注意力权重,从而降低计算复杂度。下面详细介绍一种稀疏自注意力机制——概率稀疏自注意力(ProbSparse Self-Attention),以及一个具体示例。
概率稀疏自注意力(ProbSparse Self-Attention)
概率稀疏自注意力是Informer模型中引入的一种稀疏自注意力机制。其核心思想是通过概率方法选择最重要的一部分注意力权重进行计算,而忽略那些对结果影响较小的权重。这种方法能够显著降低计算复杂度,同时保持较高的模型性能。
-
权重筛选:
对于给定的查询(query)和键(key),首先计算它们的点积得到注意力得分(attention score)。 -
重要性评估:
通过概率方法对注意力得分进行筛选,只保留那些重要性较高的得分。例如,可以选择得分中前k个最大的值,或者根据某个阈值筛选得分。 -
计算注意力:
只对筛选后的注意力得分进行归一化处理,并计算注意力权重。然后使用这些稀疏的注意力权重进行加权求和,得到最终的输出。
示例
假设我们有一个长度为 (N = 5) 的序列,其自注意力计算过程如下:
-
输入序列:
X = [x1, x2, x3, x4, x5] -
计算查询和键的点积:
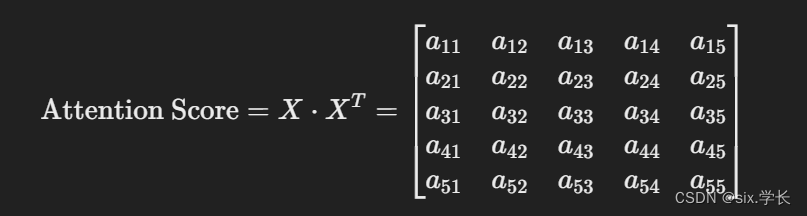
-
重要性评估和筛选:
例如,我们只保留每行中前2个最大的得分。假设筛选结果如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









