






主要思想:没有明确构建代价体积,而是依赖于快速的多分辨率初始化步骤,可微分的2D几何传播和翘曲机制来推断出视差假设;将image tail表示为具有学习紧凑特征表征描述符的平面块。
为了实现高度的精度,该网络不仅是在几何方面得到视差信息,而且而且还推断倾斜平面假设,从而允许更准确地执行几何扭曲和上采样操作。该架构本质上是多分辨率的,允许信息跨不同级别传播。
Introduction
将编码将视差分配给像素的成本的显式匹配成本体积与3D卷积结合在一起在精度方面提供了显著的改进,但代价是显著增加了计算量。后续工作表明,下采样的成本量可以在速度和准确性之间提供一个合理的折衷。然而,对成本量进行下采样是以牺牲准确性为代价的。
最近出现的提升效率的高精度视差预估方案(未融入端对端网络):首先,使用紧凑/稀疏特征进行快速高分辨率匹配成本计算;其次,非常有效的视差优化方案,不依赖于全部成本量;第三,使用倾斜平面的迭代图像扭曲来实现高精度最小化图像差异。所有这些设计选择都是在没有明确操作全3D成本的情况下使用的。
提出HITNet: 通过将图像扭曲、空间传播和快速高分辨率初始化步骤集成到网络架构中,克服了在3D体积上操作的计算缺点,同时保持学习特征的灵活性。
基本原理:利用空间传播融合来自高分辨率初始化的信息和当前的假设。传播是通过更新平面块及其附加要素的估计的卷积神经网络模块来实现的。
为了使网络迭代地提高视差预测的准确性,使用网络内图像翘曲在平面贴片周围的窄带(±1视差)内向网络提供局部代价体积,从而允许网络最小化图像相异度。
重建细化细节:从低分辨率开始分层上采样获取高分辨率预测。架构的一个重要特征是在每个分辨率上,从初始化模型提供匹配信息来促进薄结构的恢复。
主要贡献是:
1.快速的多分辨率初始化步骤,能够使用学习特征计算高分辨率匹配。
2.高效的2D视差传播,可以利用带有学习描述器的倾斜支持窗口。
3.与其他方法相比,仅使用一小部分计算得出最先进的基准测试结果
Method
目前有效的方法依赖于以下三个步骤:
1.提取紧凑的特征表示;2.高分辨率视差初始化步骤利用这些特征来检索可行的假设;3.有效的传播步骤使用倾斜的支持窗口来细化视差预估。在这些观察的激励下,我们将视差图表示为不同分辨率的planar。
tiles,并将一个可学习的特征向量附加到每个tile假设,这可以被解释为已显示为有益的可学习3D成本量的高效和稀疏版本。
方法流程:特征提取模块依赖于一个非常小的U-Net,其中解码器的多分辨率特征由其余的管道使用。这些特征对图像的多尺度细节进行编码。一旦提取了特征,我们就将视差图初始化为多分辨率下的正面平行tiles。为此,匹配器评估多个假设,并选择左视图特征和右视图特征之间的l1距离最小的一个。此外,使用小型网络计算紧凑的每块描述器。然后将初始化的输出传递到传播阶段,传播阶段的作用类似于近似的条件随机场CRF解决方案。
Tile Hypothesis
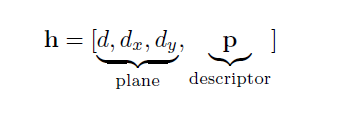
将tile假设定义为带有可学习特征的平面片。具体地说,它由描述具有视差d和视差在x、y方向(dx,dy)上的梯度的倾斜平面的几何部分和可学习的部分p组成,我们称之为特征描述符。因此,该假设被描述为对倾斜的3D平面进行编码的向量。
tile特征描述符是tile的可学习表示,其允许网络将附加信息附加到tile。例如,这可以是匹配质量或局部表面属性,例如几何图形的实际平面程度。我们不限制这些信息,而是从数据中端到端地学习它。

Initialization
初始化阶段的目标是在不同分辨率下提取每个分块的初始视差数据d和特征向量P。初始化阶段的输出是前向平行tile假设。
为了保持较高的初始视差分辨率,我们在右(次)图像中沿x方向(即宽度)使用重叠的tile,但在左(参考)图像中仍使用非重叠的tile以进行有效的匹配。为了提取tile特征,我们对每个提取的特征地图el使用4×4卷积。左(参考)图像和右(次)图像的步长不同,以便于前述重叠的tiles。对于左边的图像,我们使用4×4的步长,对于右图我们使用4×1的步长,这对于保持全视差分辨率以最大限度地提高精度至关重要。这个卷积之后是一个leaky Relu和一个1×1的卷积。
该步骤的输出是一系列拥有每一tile特征的新特征图,左右特征图的宽度此时已不相同。定义匹配代价(location (x; y)
and resolution l with disparity d)和初始视差:
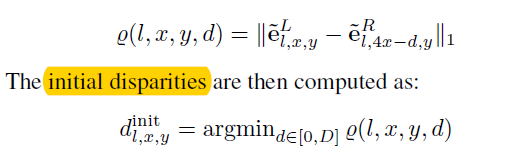
尽管初始化阶段为所有差异详尽地计算匹配,但不需要存储整个成本量。在测试时,只需要提取最佳匹配的位置,这可以利用快速存储器(例如,GPU上的共享存储器和单个操作中的融合实现)非常高效地完成。因此,不需要存储和处理3D成本量.
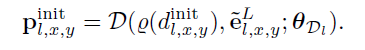
初始化特征描述符:使用一个感知器D学习匹配置信度,由leakyrelu和1*1卷积组成.
Propagation
传播步骤将tile假设作为输入,并基于信息的空间传播和信息的融合来输出细化的tile假设。它在内部扭曲特征提取阶段的特征,以预测输入图块的高精度偏移。一个额外的置信度被预测,这允许从初始阶段开始在两个假设之间进行有效的融合。
扭曲阶段计算与tile相关的左右特征图在l位置的匹配代价,用于建立在当前假设附近的局部代价体积,每个tile假设被转换成其最初在特征地图中覆盖的大小为4×4的平面片。
每个tile对应的4*4局部视差。使用沿着扫描线的线性内插,使用局部差异将特征e从右(次)图像扭曲到左(参考)图像。如果局部视差图d0是准确的,则这导致扭曲特征表示er应该非常类似于左(参考)图像e1的对应特征:

cost vector:
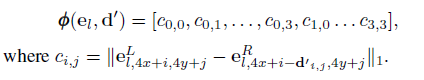
Tile Update Prediction
该步骤将n个tile假设作为输入,并预测tile假设的增量加上每个tile的标量值w,该标量值指示该tile正确的可能性有多大,即置信度度量。该机制被实现为CNN模块U,卷积结构允许网络看到空间邻域中的tile假设,因此能够在空间上传播信息。
这一步的一个关键部分是我们用来自warping步骤的匹配成本φ来扩充tile假设。通过对视差空间中的一个小邻域这样做,我们建立了一个局部代价体积,使得网络能够有效地细化tile假设。具体地说,我们将tile中的所有视差在正负方向上以一个视差1的恒定偏移量来移位,并计算三次成本。
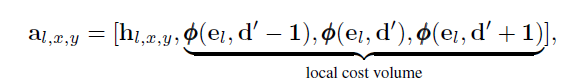
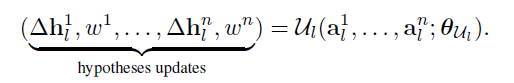
在最低分辨率M下,我们从初始化阶段开始每个位置只有1个tile假设,因此n=1。我们通过将输入tile假设和增量相加来应用tile更新,并在每个方向上以2的因子对tile进行上采样。由此,使用tile的平面方程对视差d进行上采样,并且使用最近邻采样对tile假设dx、dy和p的其余部分进行上采样。在下一个分辨率M−1,我们现在有两个假设:一个来自初始化阶段,另一个来自较低分辨率的上采样假设,因此n=2。我们利用tile置信度假设w为每个位置选择并更新置信度最高的tile假设。我们重复这个过程,直到我们达到原始分辨率。为了进一步细化视差图,我们将tile大小减小了2×2倍,并为tile分配了全分辨率特征。我们使用n=1运行传播模块,直到达到瓦片大小1×1,这是我们的最终预测。
Conclusion
用学习特征计算高分辨率匹配的初始化步骤。然后使用传播和融合步骤融合这些tile初始化。使用具有学习的描述符的倾斜支撑窗口提供了额外的准确性。















 3512
3512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









