






前言
HitNet是2023年2月份发表在AAAI的一篇文章,作者受到图像超分辨率反馈网络的启发,以迭代反馈的方式通过高分辨率特征来细化低分辨率表示,打破了伪装目标检测的性能瓶颈。
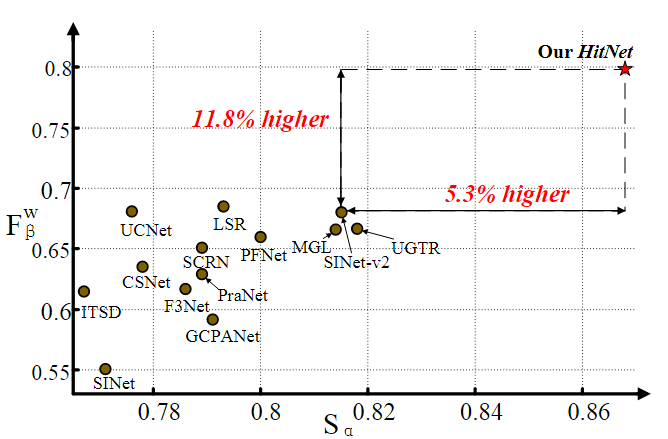
如下图,本文的方法与目前的29种SOTA方法在COD10k Test数据集上的性能比较。HitNet的 F β w F_{\beta}^w Fβw为0.798,比排名第二的LSR高16.5%。
并且,在CHAMELEON数据集上,HitNet实现了0.018的平均MAE误差,比SINet-v2提高了40%,优于 T 2 N e t T^2Net T2Net的0.023。
1. 模型的特点
作者提出高分辨率的输入图片对于伪装目标的边缘和边界检测至关重要,而现有的大多数方法都对高分辨率输入进行下采样操作来平衡计算资源和性能,这种从高分辨率(HR)到低分辨率(LR)的输入退化,导致视觉模糊,模型无法捕捉到精细结构。
作者分析,造成图像退化的原因有两个方面:
- 输入图像缺乏高分辨率信息
- 缺乏有效的加强低分辨率特征的机制
因此,如何在不牺牲实时性的前提下,保持高分辨率信息的输入水平,增强低分辨率特征,是一个值得探索的课题。
超分辨率的迭代反馈机制允许网络以更高的分辨率矫正更低的分辨率,论文Feedback Network for Image Super-Resolution中提出了一种图像超分辨率反馈网络,通过勾勒边缘和轮廓,同时抑制平滑区域,利用HR信息来细化LR表示。受此启发,作者构建了基于Transformer的高分辨率迭代反馈网络来解决伪装目标检测问题。
如下图所示,使用在LR图像上训练好的SINet分别对高分辨率(HR)输入和低分辨率(LR)输入进行分割。可以发现一个有趣的现象:同一个模型,表现出了不同的效果,HR的分割结果比LR的分割结果有更多的猫胡子等细节。

2. 模型结构
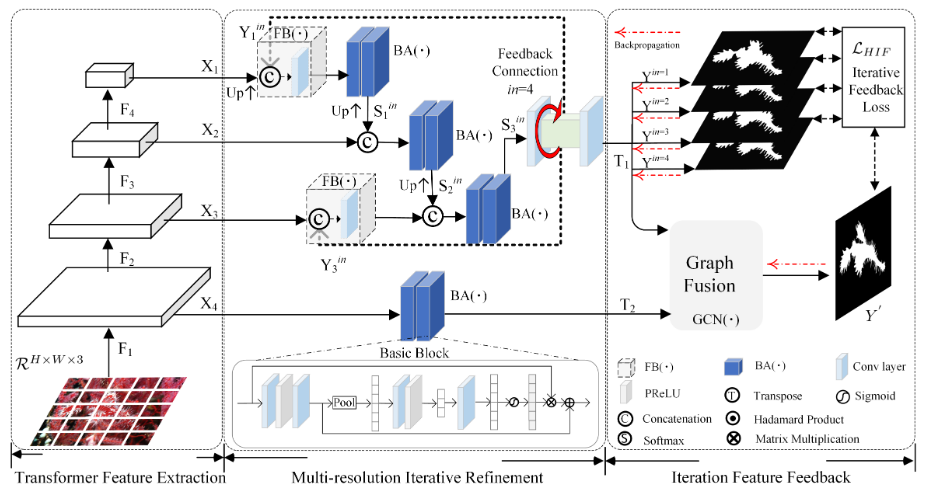
HitNet主要包含三个模块:
- 基于Transformer的特征提取模块(TFE)
- 多分辨率迭代细化模块(RIR)
- 迭代特征反馈模块(IFF)
为了降低HR特征图的计算成本,采用PVT作为图像特征编码器。
然后,利用RIR模块通过全局和跨尺度反馈策略递归地细化从TFE提取的LR特征。
为了保证反馈特征更好地聚合,使用迭代特征反馈(IFF)对反馈特征流进行约束。
2.1 基于Transformer的特征提取
Transformer相比于CNN往往需要占用更大的GPU内存,而处理高分辨率图像(HR)将进一步放大这个问题。
PVT作为特征提取模块可以提取多尺度特征,而且因其渐进收缩策略和空间缩减注意机制,可以用较小的内存成本处理相对较高分辨率的特征图。
得到多尺度特征图 ( X 1 , X 2 , X 3 , X 4 ) (X_1,X_2,X_3,X_4) (X1,X2,X3,X4),分辨率分别是原图的 ( 1 32 , 1 16 , 1 8 , 1 4 ) (\frac{1}{32},\frac{1}{16},\frac{1}{8},\frac{1}{4}) (321,161,81,41)
2.2 多分辨率反馈细化(特征融合细化)
如结构图中所示,从Transformer主干提取的多尺度分辨率特征 X X X被馈送到一个基本块BA( ⋅ \cdot ⋅)中,
B A ( X i ) = C 2 ( X i ) + C b ( C 2 ( X i ) ) ⋅ X i BA(X_i)=C_2(X_i)+C_b(C_2(X_i)) \cdot X_i BA(Xi)=C2(Xi)+Cb(C2(Xi))⋅Xi
其中, X i X_i Xi示Transformer模块产生的第i个尺度的输入特征, C 2 ( ⋅ ) C_2(\cdot) C2(⋅)表示两个 3 × 3 3 \times 3 3×3滤波器堆叠的卷积层, C b ( ⋅ ) C_b(\cdot) Cb(⋅)表示通道注意函数。
源代码如下,根据源代码发现,模块结构如下图。
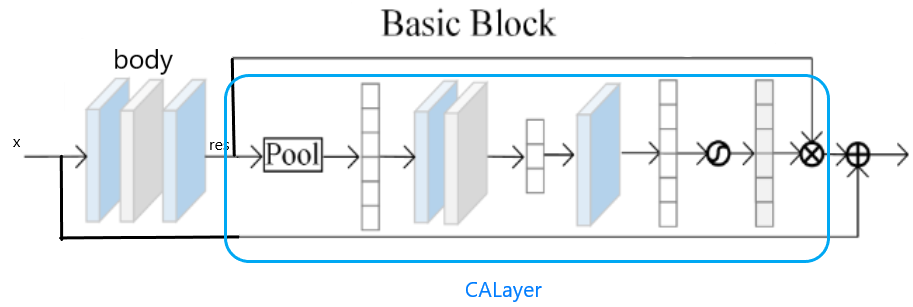
## Channel Attention Block (CAB)
class CAB(nn.Module):
def __init__(self, n_feat, kernel_size, reduction, bias, act):
super(CAB, self).__init__()
modules_body = []
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
modules_body.append(act)
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
self.CA = CALayer(n_feat, reduction, bias=bias)
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res = self.CA(res)
res += x
return res
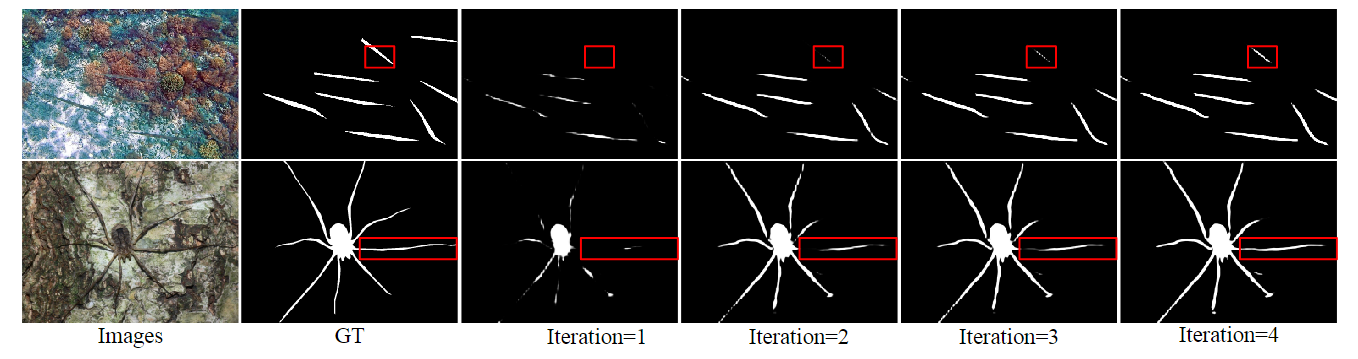
迭代反馈机制在多分辨率反馈细化模块中至关重要,如下图所示,通过逐次迭代可以实现对象边界的高精度分割。
当第一次迭代时, i n = 1 in = 1 in=1,没有从前一状态传输的反馈特征,此时 Y 1 i n Y_1^{in} Y1in是初值0。当迭代次数大于1时,之前迭代产生反馈特征,传递到反馈块 F B ( ⋅ ) FB(\cdot) FB(⋅)中。
F B ( X i + Y i i n ) = S q ( C o n c a t ( X i ↑ , Y i i n ) ) FB(X_i+Y_i^{in})=Sq(Concat(X_i \uparrow,Y_i^{in})) FB(Xi+Yiin)=Sq(Concat(Xi↑,Yiin))
其中, Y i i n Y_i^{in} Yiin是第i层特征层( i ≠ 2 i \neq 2 i=2)的第 i n in in次迭代的反馈特征,符号 ↑ \uparrow ↑代表将 X i X_i Xi上采样到与 Y i i n Y_i^{in} Yiin相同大小,用来避免高分辨率(HR)信息的退化。 C o n c a t ( ⋅ ) Concat(\cdot) Concat(⋅)表示将 X i X_i Xi和 Y i i n Y_i^{in} Yiin在通道维度上进行拼接。 S q ( ⋅ ) Sq(\cdot) Sq(⋅)代表使用具有大步长的大卷积核(如果i=1,则卷积核大小为8,步距为4;如果i=3,则卷积核大小为1,步距为1),在分辨率和通道维度上对特征图进行压缩,最终压缩至与第 i i i层相同大小。
如结构图中所示,在迭代次数 i n > 1 in > 1 in>1的前提下,第一层的输出特征可表示为:
S 1 i n = B A ( F B ( X 1 + Y 1 i n ) ) S_1^{in}=BA(FB(X_1+Y_1^{in})) S1in=BA(FB(X1+Y1in))
然后, S 1 i n S_1^{in} S1in被进一步馈送到下一个尺度中,以生成下一个输出特征:
S 2 i n = B A ( C o n c a t ( S 1 i n ↑ , X 2 ) ) S_2^{in}=BA(Concat(S_1^{in} \uparrow,X_2)) S2in=BA(Concat(S1in↑,X2))
最后,将上一层的特征传到下一层:
S 3 i n = B A ( C o n c a t ( S 2 i n ↑ , F B ( X 3 + Y 3 i n ) ) ) S_3^{in}=BA(Concat(S_2^{in} \uparrow,FB(X_3+Y_3^{in}))) S3in=BA(Concat(S2in↑,FB(X3+Y3in)))
在第 i n in in次迭代结束后, ( i n + 1 ) (in+1) (in+1)次迭代以同样的方式从第一层到最后一层。不同层级的设计主要是为了获得更好的跨层数据流。如结构图中所示,反馈特征显示输入到第一层和第三层中,而第二层则获取来自上一层的隐式反馈特征。根据实验结果,这种设计可以降低计算成本,但保持良好的性能。
2.3 迭代特征反馈(损失函数)
为了避免因循环导致的特征破坏,提出了迭代特征反馈策略,将每个反馈特征与GT联系在一起。简单地说,就是用损失函数控制反馈特征的数据流。
基础的损失函数为 L = L I o U w + L B C E w L=L_{IoU}^w+L_{BCE}^w L=LIoUw+LBCEw,其中, L I o U w L_{IoU}^w LIoUw表示加权的IoU损失, L B C E w L_{BCE}^w LBCEw表示加权的二元交叉熵损失。与F3Net中的递归结构不同,每次迭代都计算HR预测损失,并且用迭代加权的策略来惩罚每次迭代的输出。
L H I F = ∑ i n N ( w ⋅ i n ) L ( Y i n ) + L ( Y ′ ) L_{HIF}=\sum_{in}^N(w \cdot in)L(Y^{in})+L(Y') LHIF=in∑N(w⋅in)L(Yin)+L(Y′)
其中,in是当前迭代次数,N是总迭代次数,w是权重参数,源代码中为0.2, Y i n Y^{in} Yin是第n次迭代的输出, Y ′ Y' Y′是基于图的分辨率融合的输出。由此,通过赋予更高的权重来关注更深层迭代的特征。
为了更有效地集成前一个模块的特征,通过图融合模块引入非局部图融合。
Y ′ = G C N ( T 1 , T 2 ) Y'=GCN(T_1,T_2) Y′=GCN(T1,T2)
其中, Y ′ Y' Y′是最终预测图, T 1 T_1 T1是 Y i n = 4 Y^{in=4} Yin=4, T 2 T_2 T2是 X 4 X_4 X4经过 B A ( ⋅ ) BA(\cdot) BA(⋅)模块后的输出,GCN是图融合模块。
3. 思考与分析
HitNet打破性能瓶颈的原因在于以下三点:
- 每次迭代都输出一个高分辨率(HR)的分割预测,使用分割损失函数对其进行监督,使反馈特征能够学习到HR线索
- HR反馈特征与输入特征融合在一个反馈块中,缓解了HR信息的退化
- 使用反馈融合机制利用多尺度结构中的HR数据流
4. 下一步计划
- 对于论文中超分辨率的思想还不理解,阅读论文Feedback Network for Image Super-Resolution进一步理解。关注图像增强和超分辨率领域,有无可借鉴之处。
- backbone的替换。
- 特征细化模块与U-Net
- 考虑论文中提出的课题“如何在不牺牲实时性的前提下,保持高分辨率信息的输入水平,增强低分辨率特征”,考虑计算量和模型运行效率问题。















 3688
3688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









