







无模型预测:在没有MDP过程的情况下求解,没有环境先验,直接从agent和环境的交互中学习,估计值函数并得到策略
蒙特卡洛学习:信息在到达轨迹的终点以后,仅根据所观察的样本来评估其价值。
差分学习:对前一步进行反馈评估
蒙特卡洛学习:可能不是最高效的,但是是最有效的方法,广泛应用于实践中
使用经验均值反馈来替代预期反馈
First-Visit:第一次访问时计数,依据大数定理不断采样来接近真实值
采样实际上打破了对问题大小的依赖
Every-Visit:每次访问计数
Blackjack
递增求解均值
蒙特卡洛方法必须等到片段的结尾才会得知结果
蒙特卡洛增量更新:
非平稳情况下:![]()
不完全反馈的差分学习:直接从与环境互动的实际经验中进行学习,通过自举从不完整的片段中进行学习,利用估计量来估计剩余轨迹的值

通过即时反馈和下一步的折扣值来进行更新
可用于解决难以观察到最终结果以及无限循环的情况
蒙特卡洛方法和真值差分方法都是无偏估计
而差分方法引入了偏差,但减少了方差,相较于蒙特卡洛方法,TD方法只引入了一步转换的噪声,因此方差更小
总结:
蒙特卡洛方法具有高方差,零偏差,可以较好地收敛,对初值不敏感(因为不采用自举),易于理解和使用;
蒙特卡洛方法总是能最大限度地减少均方误差的解决方案
蒙特卡洛方法忽略了马尔科夫属性,但所带来的好处是其可以在非马尔可夫环境中应用
差分方法具有低方差,存在偏差,通常比蒙特卡洛方法更有效,对初值更敏感
差分方法可以利用马尔科夫特性,通过含蓄地构建MDP结构来利用它,因此通常在马尔科夫环境中差分方法更有效
自举:TD和DP都使用自举,采用估计进行更新而MC则采用正式的反馈进行更新
采样:MC和TD会进行采样,但是DP不进行采样,而是穷举备份

结合不同的n-step方法会使得方法变得更加稳定,因为它在不同情况下都得到了最佳。
如何在不增加算法复杂度的情况下,有效地结合所有的N:TD(λ![]() )
)

几何加权适用于可高效计算的算法,几何加权是无记忆的,因此不需要进行存储和计算,因此可以实现和TD(0)相同的计算成本实现TD(λ![]() )
)
资格迹(eligibility traces):①最频繁发生的;②最近发生的

前向视角TD(λ![]() ):需要考虑最终的状态,因此适应于片段性的MDP,和MC一样
):需要考虑最终的状态,因此适应于片段性的MDP,和MC一样
后向视角TD(λ![]() ):
):
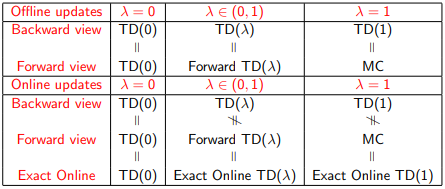
在离线更新的时候,前向和后向算法是相同的
总结:















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









