







目录
3. 关于为什么key类型为Array时,不支持Map端合并
1. 说明
我们可以将RDD想象成一个分布式表,按照不同的分区,数据分布在不同的节点上
我们对RDD做分组聚合时,一般都先在每个分区内对相同key的value做一次聚合
再在分区间对相同key的value做一次聚合
combineByKeyWithClassTag,RDD聚合操作中最通用的函数,几乎能覆盖所有聚合操作的场景
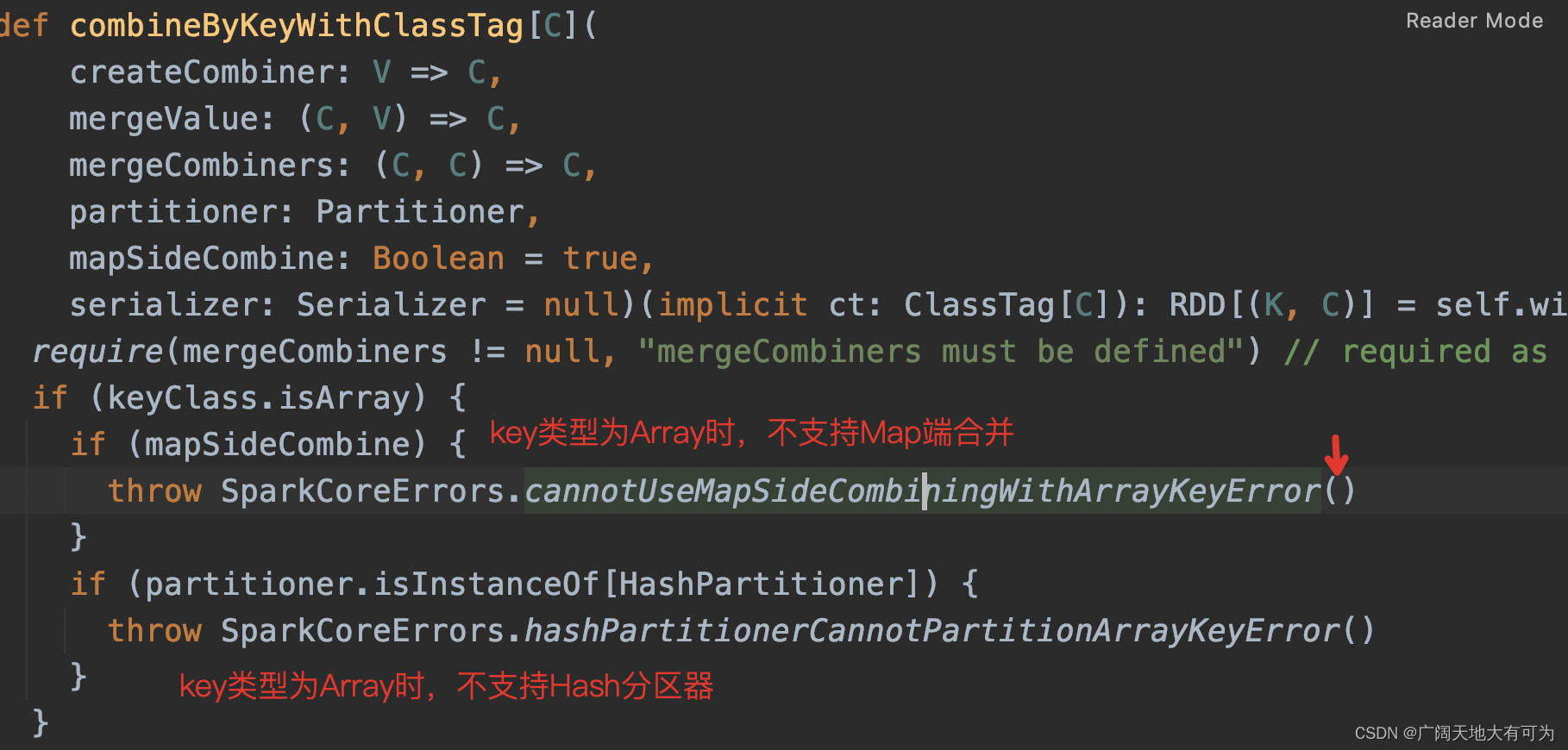
def combineByKeyWithClassTag[C](
createCombiner: V => C, // 指定Lambda表达式,用于转换value的数据类型
mergeValue: (C, V) => C, // 指定Lambda表达式,用于分区内 合并相同key下的value值
mergeCombiners: (C, C) => C, // 指定Lambda表达式,用于分区内 合并相同key下的value值
partitioner: Partitioner, // 指定分区器
mapSideCombine: Boolean = true, // 是否支持map端聚合
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)]
createCombiner、mergeValue用于map端的聚合操作
mergeCombiners 用于reduce端的聚合操作2. 示例
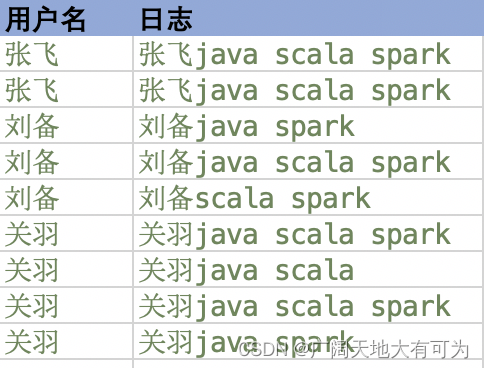
需求: 统计每个用户下,所拥有的的单词数量
场景1: 设置RDD分区数为2
test("combineByKeyWithClassTag示例") {
// 初始化 spark配置实例
val sparkconf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("")
// 初始化 spark环境对象
val sc: SparkContext = new SparkContext(sparkconf)
val rdd: RDD[(String, String)] = sc.makeRDD(List(
("张飞", "张飞java scala spark")
, ("张飞", "张飞java scala spark")
, ("刘备", "刘备java spark")
, ("刘备", "刘备java scala spark")
, ("刘备", "刘备scala spark")
, ("关羽", "关羽java scala spark")
, ("关羽", "关羽java scala")
, ("关羽", "关羽java scala spark")
, ("关羽", "关羽java spark")))
// 查看每个分区的内容
val value1: RDD[(String, String)] = rdd.mapPartitionsWithIndex(
(i, iter) => {
println(s"分区编号$i :${iter.mkString(" ")}");
iter
}
)
value1.collect()
/*
* TODO 需求: 查询每个用户下,所拥有的的单词数量
*
* */
val groupByName: RDD[(String, Int)] = rdd.combineByKeyWithClassTag(
/*
* Lambda1: 分区内用来将 String 转换成Int
* */
partionFirstValue => {
println(s"Lambda1:$partionFirstValue");
partionFirstValue.split(" ").length
}
/*
* Lambda2: 分区内对相同key 做聚合操作
* */
, (key: Int, value: String) => {
println(s"Lambda2:$key # $value")
key + value.split(" ").length
}
/*
* Lambda3: 分区间对相同key 做聚合操作
* */
, (v1: Int, v2: Int) => {
println(s"Lambda3:$v1 # $v2")
v1 + v2
}
)
groupByName.collect().foreach(println(_))
sc.stop()
}
通过执行日志和结果来执行过程
//1.查看每个分区下的数据
分区编号1 :(刘备,刘备scala spark) (关羽,关羽java scala spark) (关羽,关羽java scala) (关羽,关羽java scala spark) (关羽,关羽java spark)
分区编号0 :(张飞,张飞java scala spark) (张飞,张飞java scala spark) (刘备,刘备java spark) (刘备,刘备java scala spark)
//2.分区内合并操作
分区编号0 :(张飞,张飞java scala spark) (张飞,张飞java scala spark) (刘备,刘备java spark) (刘备,刘备java scala spark)
Lambda1:张飞java scala spark
Lambda2:3 # 张飞java scala spark
Lambda1:刘备scala spark
Lambda2:2 # 刘备java scala spark
分区编号0输出结果: (张飞,6) (刘备,5)
分区编号1 :(刘备,刘备scala spark) (关羽,关羽java scala spark) (关羽,关羽java scala) (关羽,关羽java scala spark) (关羽,关羽java spark)
Lambda1:刘备java spark
因为这个分区中,key=刘备 只有一个元素,所以不会调用 分区间合并函数
Lambda1:关羽java scala spark
Lambda2:3 # 关羽java scala
Lambda2:5 # 关羽java scala spark
Lambda2:8 # 关羽java spark
分区编号1输出结果: (刘备,2) (关羽,10)
//3.分区间合并操作
拉取map端合并的结果: (张飞,6) (刘备,5) (刘备,2) (关羽,10)
Lambda3:5 # 2
只有 key=刘备 需要合并value,所以分区间合并函数 只被调用了一次
//4.输出最终计算结果
(关羽,10)
(张飞,6)
(刘备,7)场景2: 设置RDD分区数为5
setMaster("local[5]") 用CPU核数为5来模拟
//1.查看每个分区下的数据
分区编号2 :(刘备,刘备java scala spark) (刘备,刘备scala spark)
分区编号1 :(张飞,张飞java scala spark) (刘备,刘备java spark)
分区编号0 :(张飞,张飞java scala spark)
分区编号3 :(关羽,关羽java scala spark) (关羽,关羽java scala)
分区编号4 :(关羽,关羽java scala spark) (关羽,关羽java spark)
//2.分区内合并操作
分区编号2 :(刘备,刘备java scala spark) (刘备,刘备scala spark)
Lambda1:刘备java scala spark
Lambda2:3 # 刘备scala spark
分区编号2输出结果: (刘备,5)
分区编号1 :(张飞,张飞java scala spark) (刘备,刘备java spark)
Lambda1:张飞java scala spark
Lambda1:刘备java spark
分区编号1输出结果: (张飞,3) (刘备,2)
分区编号0 :(张飞,张飞java scala spark)
Lambda1:张飞java scala spark
分区编号0输出结果: (张飞,3)
分区编号3 :(关羽,关羽java scala spark) (关羽,关羽java scala)
Lambda1:关羽java scala spark
Lambda2:3 # 关羽java scala
分区编号3输出结果: (关羽,5)
分区编号4 :(关羽,关羽java scala spark) (关羽,关羽java spark)
Lambda1:关羽java scala spark
Lambda2:3 # 关羽java spark
分区编号4输出结果: (关羽,5)
//3.分区间合并操作
拉取map端合并的结果: (刘备,5) (刘备,2) (张飞,3) (张飞,3) (关羽,5) (关羽,5)
Lambda3:3 # 3 合并key=张飞 的value
Lambda3:2 # 5 合并key=刘备 的value
Lambda3:5 # 5 合并key=关羽 的value
//4.输出最终计算结果
(张飞,6)
(刘备,7)
(关羽,10)3. 关于为什么key类型为Array时,不支持Map端合并
test("当key类型为Array时,combineByKeyWithClassTag示例") {
// 初始化 spark配置实例
val sparkconf: SparkConf = new SparkConf().setMaster("local[5]").setAppName("")
// 初始化 spark环境对象
val sc: SparkContext = new SparkContext(sparkconf)
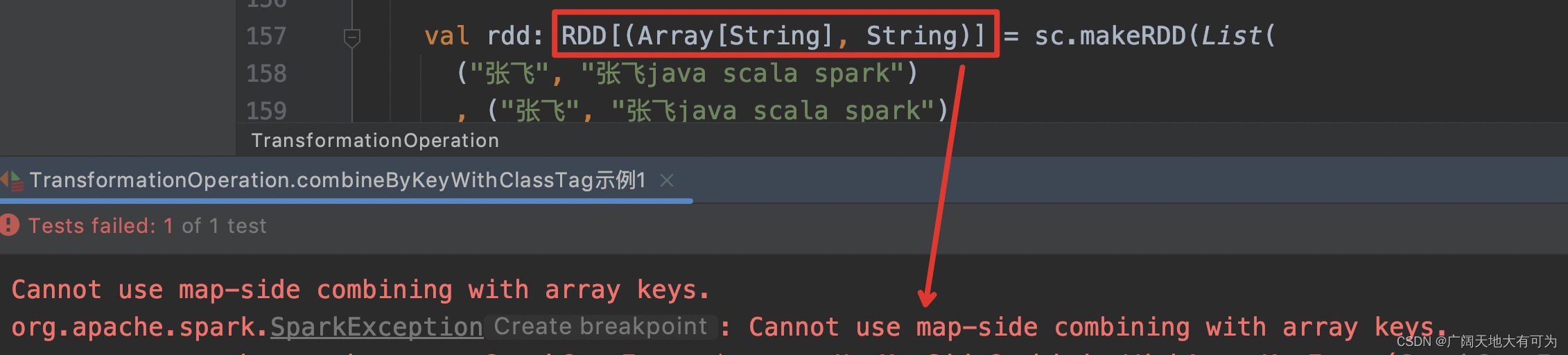
val rdd: RDD[(Array[String], String)] = sc.makeRDD(List(
("张飞", "张飞java scala spark")
, ("张飞", "张飞java scala spark")
, ("刘备", "刘备java spark")
, ("刘备", "刘备java scala spark")
, ("刘备", "刘备scala spark")
, ("关羽", "关羽java scala spark")
, ("关羽", "关羽java scala")
, ("关羽", "关羽java scala spark")
, ("关羽", "关羽java spark"))).map( tuple => (tuple._2.split(" "),tuple._1))
/*
* TODO 需求: 查询每个用户下,所拥有的的单词数量
*
* */
val groupByName: RDD[(Array[String], Int)] = rdd.combineByKeyWithClassTag(
/*
* Lambda1: 分区内用来将 String 转换成Int
* */
partionFirstValue => {
println(s"Lambda1:$partionFirstValue");
partionFirstValue.split(" ").length
}
/*
* Lambda2: 分区内对相同key 做聚合操作
* */
, (key: Int, value: String) => {
println(s"Lambda2:$key # $value")
key + value.split(" ").length
}
/*
* Lambda3: 分区间对相同key 做聚合操作
* */
, (v1: Int, v2: Int) => {
println(s"Lambda3:$v1 # $v2")
v1 + v2
}
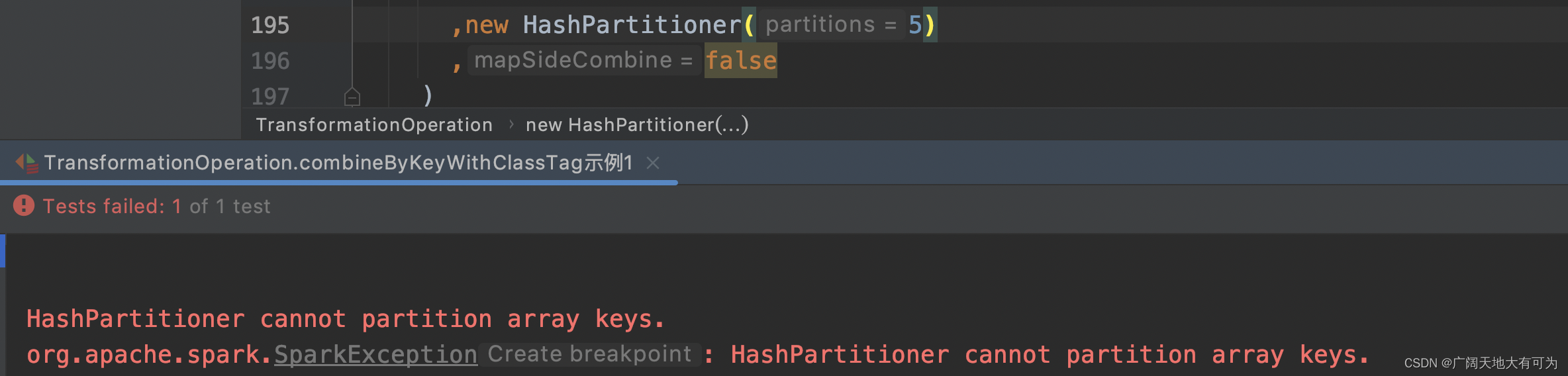
,new HashPartitioner(5)
,false
)
groupByName.collect().foreach(println(_))
sc.stop()
}
















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









